mirror of
https://github.com/jupyterhub/jupyterhub.git
synced 2025-10-10 19:43:01 +00:00
Compare commits
20 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
a3c93088a8 | ||
|
|
834229622d | ||
|
|
44a1ea42de | ||
|
|
3879a96b67 | ||
|
|
d40627d397 | ||
|
|
057cdbc9e9 | ||
|
|
75390d2e46 | ||
|
|
f5e4846cfa | ||
|
|
3dc115a829 | ||
|
|
af4ddbfc58 | ||
|
|
50a4d1e34d | ||
|
|
86a238334c | ||
|
|
dacb9d1668 | ||
|
|
95cc170383 | ||
|
|
437a9d150f | ||
|
|
c9616d6f11 | ||
|
|
61aed70c4d | ||
|
|
9abb573d47 | ||
|
|
b074304834 | ||
|
|
201e7ca3d8 |
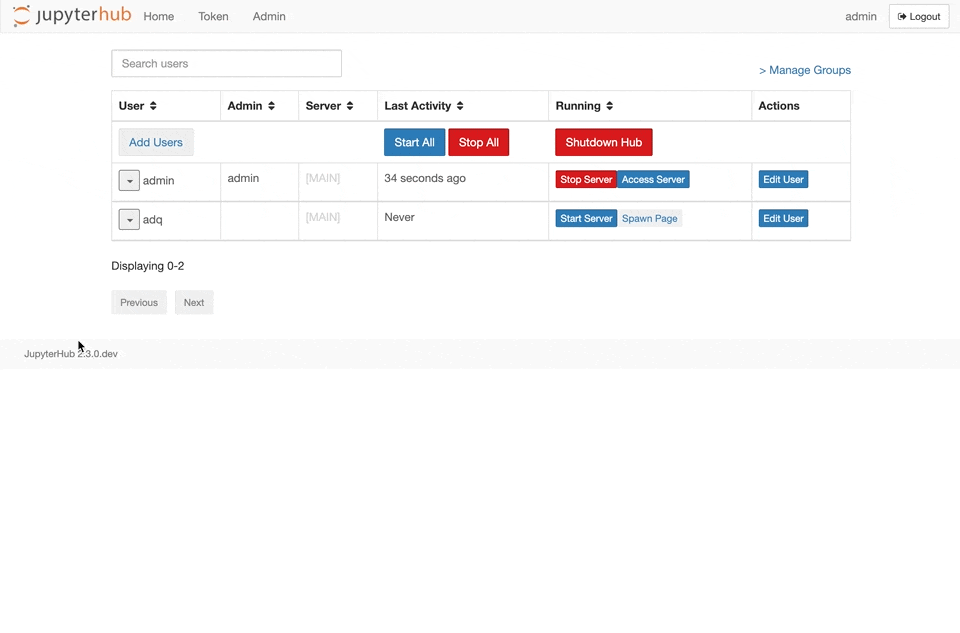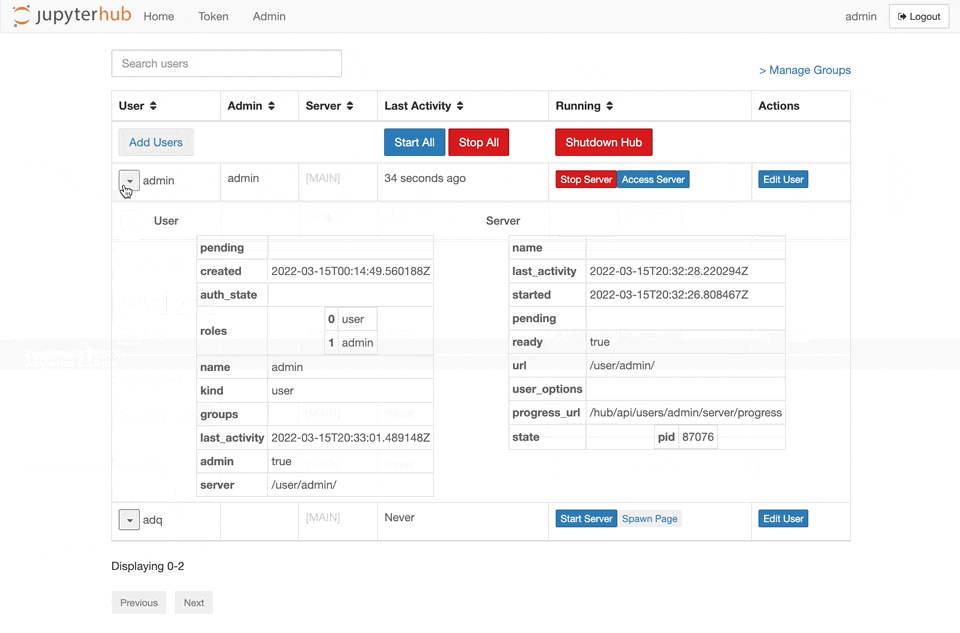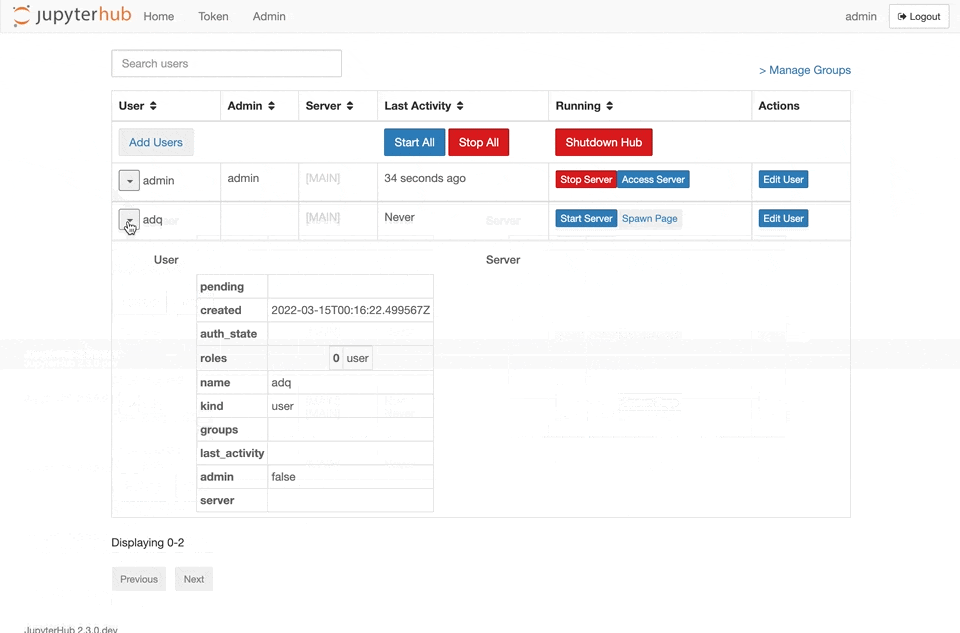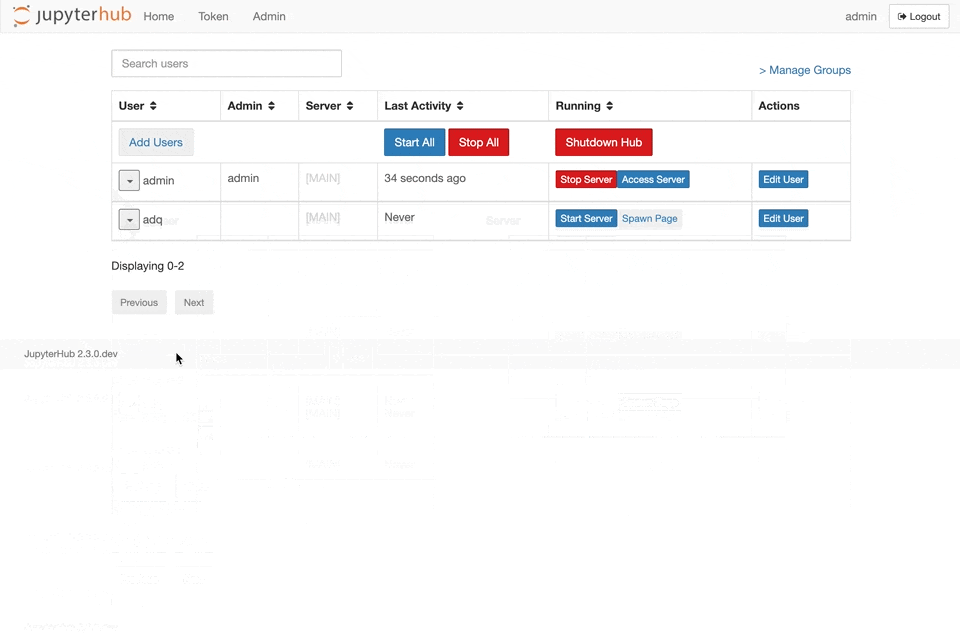{kind=link}
9
.flake8
9
.flake8
@@ -3,9 +3,14 @@
|
||||
# E: style errors
|
||||
# W: style warnings
|
||||
# C: complexity
|
||||
# D: docstring warnings (unused pydocstyle extension)
|
||||
# F401: module imported but unused
|
||||
# F403: import *
|
||||
# F811: redefinition of unused `name` from line `N`
|
||||
# F841: local variable assigned but never used
|
||||
ignore = E, C, W, D, F841
|
||||
# E402: module level import not at top of file
|
||||
# I100: Import statements are in the wrong order
|
||||
# I101: Imported names are in the wrong order. Should be
|
||||
ignore = E, C, W, F401, F403, F811, F841, E402, I100, I101, D400
|
||||
builtins = c, get_config
|
||||
exclude =
|
||||
.cache,
|
||||
|
||||
15
.github/dependabot.yml
vendored
15
.github/dependabot.yml
vendored
@@ -1,15 +0,0 @@
|
||||
# dependabot.yml reference: https://docs.github.com/en/code-security/dependabot/dependabot-version-updates/configuration-options-for-the-dependabot.yml-file
|
||||
#
|
||||
# Notes:
|
||||
# - Status and logs from dependabot are provided at
|
||||
# https://github.com/jupyterhub/jupyterhub/network/updates.
|
||||
#
|
||||
version: 2
|
||||
updates:
|
||||
# Maintain dependencies in our GitHub Workflows
|
||||
- package-ecosystem: github-actions
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: weekly
|
||||
time: "05:00"
|
||||
timezone: "Etc/UTC"
|
||||
56
.github/workflows/release.yml
vendored
56
.github/workflows/release.yml
vendored
@@ -32,18 +32,17 @@ jobs:
|
||||
build-release:
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/setup-python@v4
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: "3.9"
|
||||
python-version: 3.8
|
||||
|
||||
- uses: actions/setup-node@v3
|
||||
- uses: actions/setup-node@v1
|
||||
with:
|
||||
node-version: "14"
|
||||
|
||||
- name: install build requirements
|
||||
- name: install build package
|
||||
run: |
|
||||
npm install -g yarn
|
||||
pip install --upgrade pip
|
||||
pip install build
|
||||
pip freeze
|
||||
@@ -53,21 +52,28 @@ jobs:
|
||||
python -m build --sdist --wheel .
|
||||
ls -l dist
|
||||
|
||||
- name: verify sdist
|
||||
- name: verify wheel
|
||||
run: |
|
||||
./ci/check_sdist.py dist/jupyterhub-*.tar.gz
|
||||
|
||||
- name: verify data-files are installed where they are found
|
||||
run: |
|
||||
pip install dist/*.whl
|
||||
./ci/check_installed_data.py
|
||||
|
||||
- name: verify sdist can be installed without npm/yarn
|
||||
run: |
|
||||
docker run --rm -v $PWD/dist:/dist:ro docker.io/library/python:3.9-slim-bullseye bash -c 'pip install /dist/jupyterhub-*.tar.gz'
|
||||
cd dist
|
||||
pip install ./*.whl
|
||||
# verify data-files are installed where they are found
|
||||
cat <<EOF | python
|
||||
import os
|
||||
from jupyterhub._data import DATA_FILES_PATH
|
||||
print(f"DATA_FILES_PATH={DATA_FILES_PATH}")
|
||||
assert os.path.exists(DATA_FILES_PATH), DATA_FILES_PATH
|
||||
for subpath in (
|
||||
"templates/page.html",
|
||||
"static/css/style.min.css",
|
||||
"static/components/jquery/dist/jquery.js",
|
||||
):
|
||||
path = os.path.join(DATA_FILES_PATH, subpath)
|
||||
assert os.path.exists(path), path
|
||||
print("OK")
|
||||
EOF
|
||||
|
||||
# ref: https://github.com/actions/upload-artifact#readme
|
||||
- uses: actions/upload-artifact@v3
|
||||
- uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: jupyterhub-${{ github.sha }}
|
||||
path: "dist/*"
|
||||
@@ -102,16 +108,16 @@ jobs:
|
||||
echo "REGISTRY=localhost:5000/" >> $GITHUB_ENV
|
||||
fi
|
||||
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/checkout@v2
|
||||
|
||||
# Setup docker to build for multiple platforms, see:
|
||||
# https://github.com/docker/build-push-action/tree/v2.4.0#usage
|
||||
# https://github.com/docker/build-push-action/blob/v2.4.0/docs/advanced/multi-platform.md
|
||||
- name: Set up QEMU (for docker buildx)
|
||||
uses: docker/setup-qemu-action@e81a89b1732b9c48d79cd809d8d81d79c4647a18 # associated tag: v1.0.2
|
||||
uses: docker/setup-qemu-action@25f0500ff22e406f7191a2a8ba8cda16901ca018 # associated tag: v1.0.2
|
||||
|
||||
- name: Set up Docker Buildx (for multi-arch builds)
|
||||
uses: docker/setup-buildx-action@8c0edbc76e98fa90f69d9a2c020dcb50019dc325
|
||||
uses: docker/setup-buildx-action@2a4b53665e15ce7d7049afb11ff1f70ff1610609 # associated tag: v1.1.2
|
||||
with:
|
||||
# Allows pushing to registry on localhost:5000
|
||||
driver-opts: network=host
|
||||
@@ -149,7 +155,7 @@ jobs:
|
||||
branchRegex: ^\w[\w-.]*$
|
||||
|
||||
- name: Build and push jupyterhub
|
||||
uses: docker/build-push-action@c56af957549030174b10d6867f20e78cfd7debc5
|
||||
uses: docker/build-push-action@e1b7f96249f2e4c8e4ac1519b9608c0d48944a1f
|
||||
with:
|
||||
context: .
|
||||
platforms: linux/amd64,linux/arm64
|
||||
@@ -170,7 +176,7 @@ jobs:
|
||||
branchRegex: ^\w[\w-.]*$
|
||||
|
||||
- name: Build and push jupyterhub-onbuild
|
||||
uses: docker/build-push-action@c56af957549030174b10d6867f20e78cfd7debc5
|
||||
uses: docker/build-push-action@e1b7f96249f2e4c8e4ac1519b9608c0d48944a1f
|
||||
with:
|
||||
build-args: |
|
||||
BASE_IMAGE=${{ fromJson(steps.jupyterhubtags.outputs.tags)[0] }}
|
||||
@@ -191,7 +197,7 @@ jobs:
|
||||
branchRegex: ^\w[\w-.]*$
|
||||
|
||||
- name: Build and push jupyterhub-demo
|
||||
uses: docker/build-push-action@c56af957549030174b10d6867f20e78cfd7debc5
|
||||
uses: docker/build-push-action@e1b7f96249f2e4c8e4ac1519b9608c0d48944a1f
|
||||
with:
|
||||
build-args: |
|
||||
BASE_IMAGE=${{ fromJson(steps.onbuildtags.outputs.tags)[0] }}
|
||||
@@ -215,7 +221,7 @@ jobs:
|
||||
branchRegex: ^\w[\w-.]*$
|
||||
|
||||
- name: Build and push jupyterhub/singleuser
|
||||
uses: docker/build-push-action@c56af957549030174b10d6867f20e78cfd7debc5
|
||||
uses: docker/build-push-action@e1b7f96249f2e4c8e4ac1519b9608c0d48944a1f
|
||||
with:
|
||||
build-args: |
|
||||
JUPYTERHUB_VERSION=${{ github.ref_type == 'tag' && github.ref_name || format('git:{0}', github.sha) }}
|
||||
|
||||
16
.github/workflows/test-docs.yml
vendored
16
.github/workflows/test-docs.yml
vendored
@@ -15,13 +15,15 @@ on:
|
||||
- "docs/**"
|
||||
- "jupyterhub/_version.py"
|
||||
- "jupyterhub/scopes.py"
|
||||
- ".github/workflows/test-docs.yml"
|
||||
- ".github/workflows/*"
|
||||
- "!.github/workflows/test-docs.yml"
|
||||
push:
|
||||
paths:
|
||||
- "docs/**"
|
||||
- "jupyterhub/_version.py"
|
||||
- "jupyterhub/scopes.py"
|
||||
- ".github/workflows/test-docs.yml"
|
||||
- ".github/workflows/*"
|
||||
- "!.github/workflows/test-docs.yml"
|
||||
branches-ignore:
|
||||
- "dependabot/**"
|
||||
- "pre-commit-ci-update-config"
|
||||
@@ -38,24 +40,24 @@ jobs:
|
||||
validate-rest-api-definition:
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/checkout@v2
|
||||
|
||||
- name: Validate REST API definition
|
||||
uses: char0n/swagger-editor-validate@v1.3.2
|
||||
uses: char0n/swagger-editor-validate@182d1a5d26ff5c2f4f452c43bd55e2c7d8064003
|
||||
with:
|
||||
definition-file: docs/source/_static/rest-api.yml
|
||||
|
||||
test-docs:
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/setup-python@v4
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: "3.9"
|
||||
|
||||
- name: Install requirements
|
||||
run: |
|
||||
pip install -r docs/requirements.txt pytest
|
||||
pip install -r docs/requirements.txt pytest -e .
|
||||
|
||||
- name: pytest docs/
|
||||
run: |
|
||||
|
||||
66
.github/workflows/test-jsx.yml
vendored
66
.github/workflows/test-jsx.yml
vendored
@@ -19,9 +19,6 @@ on:
|
||||
- "**"
|
||||
workflow_dispatch:
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
|
||||
jobs:
|
||||
# The ./jsx folder contains React based source code files that are to compile
|
||||
# to share/jupyterhub/static/js/admin-react.js. The ./jsx folder includes
|
||||
@@ -32,8 +29,8 @@ jobs:
|
||||
timeout-minutes: 5
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/setup-node@v3
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions/setup-node@v1
|
||||
with:
|
||||
node-version: "14"
|
||||
|
||||
@@ -50,3 +47,62 @@ jobs:
|
||||
run: |
|
||||
cd jsx
|
||||
yarn test
|
||||
|
||||
# The ./jsx folder contains React based source files that are to compile to
|
||||
# share/jupyterhub/static/js/admin-react.js. This job makes sure that whatever
|
||||
# we have in jsx/src matches the compiled asset that we package and
|
||||
# distribute.
|
||||
#
|
||||
# This job's purpose is to make sure we don't forget to compile changes and to
|
||||
# verify nobody sneaks in a change in the hard to review compiled asset.
|
||||
#
|
||||
# NOTE: In the future we may want to stop version controlling the compiled
|
||||
# artifact and instead generate it whenever we package JupyterHub. If we
|
||||
# do this, we are required to setup node and compile the source code
|
||||
# more often, at the same time we could avoid having this check be made.
|
||||
#
|
||||
compile-jsx-admin-react:
|
||||
runs-on: ubuntu-20.04
|
||||
timeout-minutes: 5
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
- uses: actions/setup-node@v1
|
||||
with:
|
||||
node-version: "14"
|
||||
|
||||
- name: Install yarn
|
||||
run: |
|
||||
npm install -g yarn
|
||||
|
||||
- name: yarn
|
||||
run: |
|
||||
cd jsx
|
||||
yarn
|
||||
|
||||
- name: yarn build
|
||||
run: |
|
||||
cd jsx
|
||||
yarn build
|
||||
|
||||
- name: yarn place
|
||||
run: |
|
||||
cd jsx
|
||||
yarn place
|
||||
|
||||
- name: Verify compiled jsx/src matches version controlled artifact
|
||||
run: |
|
||||
if [[ `git status --porcelain=v1` ]]; then
|
||||
echo "The source code in ./jsx compiles to something different than found in ./share/jupyterhub/static/js/admin-react.js!"
|
||||
echo
|
||||
echo "Please re-compile the source code in ./jsx with the following commands:"
|
||||
echo
|
||||
echo "yarn"
|
||||
echo "yarn build"
|
||||
echo "yarn place"
|
||||
echo
|
||||
echo "See ./jsx/README.md for more details."
|
||||
exit 1
|
||||
else
|
||||
echo "Compilation of jsx/src to share/jupyterhub/static/js/admin-react.js didn't lead to changes."
|
||||
fi
|
||||
|
||||
78
.github/workflows/test.yml
vendored
78
.github/workflows/test.yml
vendored
@@ -29,10 +29,6 @@ env:
|
||||
# UTF-8 content may be interpreted as ascii and causes errors without this.
|
||||
LANG: C.UTF-8
|
||||
PYTEST_ADDOPTS: "--verbose --color=yes"
|
||||
SQLALCHEMY_WARN_20: "1"
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
|
||||
jobs:
|
||||
# Run "pytest jupyterhub/tests" in various configurations
|
||||
@@ -57,9 +53,9 @@ jobs:
|
||||
# Tests everything when JupyterHub works against a dedicated mysql or
|
||||
# postgresql server.
|
||||
#
|
||||
# legacy_notebook:
|
||||
# nbclassic:
|
||||
# Tests everything when the user instances are started with
|
||||
# the legacy notebook server instead of jupyter_server.
|
||||
# notebook instead of jupyter_server.
|
||||
#
|
||||
# ssl:
|
||||
# Tests everything using internal SSL connections instead of
|
||||
@@ -72,25 +68,21 @@ jobs:
|
||||
# NOTE: Since only the value of these parameters are presented in the
|
||||
# GitHub UI when the workflow run, we avoid using true/false as
|
||||
# values by instead duplicating the name to signal true.
|
||||
# Python versions available at:
|
||||
# https://github.com/actions/python-versions/blob/HEAD/versions-manifest.json
|
||||
include:
|
||||
- python: "3.7"
|
||||
- python: "3.6"
|
||||
oldest_dependencies: oldest_dependencies
|
||||
legacy_notebook: legacy_notebook
|
||||
- python: "3.8"
|
||||
legacy_notebook: legacy_notebook
|
||||
- python: "3.9"
|
||||
db: mysql
|
||||
- python: "3.10"
|
||||
db: postgres
|
||||
- python: "3.11"
|
||||
nbclassic: nbclassic
|
||||
- python: "3.6"
|
||||
subdomain: subdomain
|
||||
- python: "3.11"
|
||||
- python: "3.7"
|
||||
db: mysql
|
||||
- python: "3.7"
|
||||
ssl: ssl
|
||||
- python: "3.11"
|
||||
selenium: selenium
|
||||
- python: "3.11"
|
||||
- python: "3.8"
|
||||
db: postgres
|
||||
- python: "3.8"
|
||||
nbclassic: nbclassic
|
||||
- python: "3.9"
|
||||
main_dependencies: main_dependencies
|
||||
|
||||
steps:
|
||||
@@ -118,30 +110,29 @@ jobs:
|
||||
if [ "${{ matrix.jupyter_server }}" != "" ]; then
|
||||
echo "JUPYTERHUB_SINGLEUSER_APP=jupyterhub.tests.mockserverapp.MockServerApp" >> $GITHUB_ENV
|
||||
fi
|
||||
- uses: actions/checkout@v3
|
||||
# NOTE: actions/setup-node@v3 make use of a cache within the GitHub base
|
||||
- uses: actions/checkout@v2
|
||||
# NOTE: actions/setup-node@v1 make use of a cache within the GitHub base
|
||||
# environment and setup in a fraction of a second.
|
||||
- name: Install Node v14
|
||||
uses: actions/setup-node@v3
|
||||
uses: actions/setup-node@v1
|
||||
with:
|
||||
node-version: "14"
|
||||
- name: Install Javascript dependencies
|
||||
- name: Install Node dependencies
|
||||
run: |
|
||||
npm install
|
||||
npm install -g configurable-http-proxy yarn
|
||||
npm install -g configurable-http-proxy
|
||||
npm list
|
||||
|
||||
# NOTE: actions/setup-python@v4 make use of a cache within the GitHub base
|
||||
# NOTE: actions/setup-python@v2 make use of a cache within the GitHub base
|
||||
# environment and setup in a fraction of a second.
|
||||
- name: Install Python ${{ matrix.python }}
|
||||
uses: actions/setup-python@v4
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: "${{ matrix.python }}"
|
||||
|
||||
python-version: ${{ matrix.python }}
|
||||
- name: Install Python dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install -e ".[test]"
|
||||
pip install --upgrade . -r dev-requirements.txt
|
||||
|
||||
if [ "${{ matrix.oldest_dependencies }}" != "" ]; then
|
||||
# take any dependencies in requirements.txt such as tornado>=5.0
|
||||
@@ -153,11 +144,10 @@ jobs:
|
||||
|
||||
if [ "${{ matrix.main_dependencies }}" != "" ]; then
|
||||
pip install git+https://github.com/ipython/traitlets#egg=traitlets --force
|
||||
pip install --upgrade --pre sqlalchemy
|
||||
fi
|
||||
if [ "${{ matrix.legacy_notebook }}" != "" ]; then
|
||||
if [ "${{ matrix.nbclassic }}" != "" ]; then
|
||||
pip uninstall jupyter_server --yes
|
||||
pip install 'notebook<7'
|
||||
pip install notebook
|
||||
fi
|
||||
if [ "${{ matrix.db }}" == "mysql" ]; then
|
||||
pip install mysql-connector-python
|
||||
@@ -208,32 +198,20 @@ jobs:
|
||||
DB=postgres bash ci/docker-db.sh
|
||||
DB=postgres bash ci/init-db.sh
|
||||
fi
|
||||
- name: Setup Firefox
|
||||
if: matrix.selenium
|
||||
uses: browser-actions/setup-firefox@latest
|
||||
with:
|
||||
firefox-version: latest
|
||||
|
||||
- name: Setup Geckodriver
|
||||
if: matrix.selenium
|
||||
uses: browser-actions/setup-geckodriver@latest
|
||||
|
||||
- name: Configure selenium tests
|
||||
if: matrix.selenium
|
||||
run: echo "PYTEST_ADDOPTS=$PYTEST_ADDOPTS -m selenium" >> "${GITHUB_ENV}"
|
||||
|
||||
- name: Run pytest
|
||||
run: |
|
||||
pytest --maxfail=2 --cov=jupyterhub jupyterhub/tests
|
||||
|
||||
- uses: codecov/codecov-action@v3
|
||||
- name: Submit codecov report
|
||||
run: |
|
||||
codecov
|
||||
|
||||
docker-build:
|
||||
runs-on: ubuntu-20.04
|
||||
timeout-minutes: 20
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/checkout@v2
|
||||
|
||||
- name: build images
|
||||
run: |
|
||||
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@@ -10,7 +10,6 @@ docs/build
|
||||
docs/source/_static/rest-api
|
||||
docs/source/rbac/scope-table.md
|
||||
.ipynb_checkpoints
|
||||
jsx/build/
|
||||
# ignore config file at the top-level of the repo
|
||||
# but not sub-dirs
|
||||
/jupyterhub_config.py
|
||||
@@ -20,7 +19,6 @@ package-lock.json
|
||||
share/jupyterhub/static/components
|
||||
share/jupyterhub/static/css/style.min.css
|
||||
share/jupyterhub/static/css/style.min.css.map
|
||||
share/jupyterhub/static/js/admin-react.js*
|
||||
*.egg-info
|
||||
MANIFEST
|
||||
.coverage
|
||||
|
||||
@@ -11,42 +11,33 @@
|
||||
repos:
|
||||
# Autoformat: Python code, syntax patterns are modernized
|
||||
- repo: https://github.com/asottile/pyupgrade
|
||||
rev: v3.2.2
|
||||
rev: v2.32.1
|
||||
hooks:
|
||||
- id: pyupgrade
|
||||
args:
|
||||
- --py36-plus
|
||||
|
||||
# Autoformat: Python code
|
||||
- repo: https://github.com/PyCQA/autoflake
|
||||
rev: v2.0.0
|
||||
- repo: https://github.com/asottile/reorder_python_imports
|
||||
rev: v3.1.0
|
||||
hooks:
|
||||
- id: autoflake
|
||||
# args ref: https://github.com/PyCQA/autoflake#advanced-usage
|
||||
args:
|
||||
- --in-place
|
||||
|
||||
# Autoformat: Python code
|
||||
- repo: https://github.com/pycqa/isort
|
||||
rev: 5.10.1
|
||||
hooks:
|
||||
- id: isort
|
||||
- id: reorder-python-imports
|
||||
|
||||
# Autoformat: Python code
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 22.10.0
|
||||
rev: 22.3.0
|
||||
hooks:
|
||||
- id: black
|
||||
|
||||
# Autoformat: markdown, yaml, javascript (see the file .prettierignore)
|
||||
- repo: https://github.com/pre-commit/mirrors-prettier
|
||||
rev: v3.0.0-alpha.4
|
||||
rev: v2.6.2
|
||||
hooks:
|
||||
- id: prettier
|
||||
|
||||
# Autoformat and linting, misc. details
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v4.4.0
|
||||
rev: v4.2.0
|
||||
hooks:
|
||||
- id: end-of-file-fixer
|
||||
exclude: share/jupyterhub/static/js/admin-react.js
|
||||
@@ -56,6 +47,6 @@ repos:
|
||||
|
||||
# Linting: Python code (see the file .flake8)
|
||||
- repo: https://github.com/PyCQA/flake8
|
||||
rev: "6.0.0"
|
||||
rev: "4.0.1"
|
||||
hooks:
|
||||
- id: flake8
|
||||
|
||||
@@ -1,7 +1,3 @@
|
||||
# Configuration on how ReadTheDocs (RTD) builds our documentation
|
||||
# ref: https://readthedocs.org/projects/jupyterhub/
|
||||
# ref: https://docs.readthedocs.io/en/stable/config-file/v2.html
|
||||
#
|
||||
version: 2
|
||||
|
||||
sphinx:
|
||||
@@ -15,11 +11,10 @@ build:
|
||||
|
||||
python:
|
||||
install:
|
||||
- method: pip
|
||||
path: .
|
||||
- requirements: docs/requirements.txt
|
||||
|
||||
formats:
|
||||
# Adding htmlzip enables a Downloads section in the rendered website's RTD
|
||||
# menu where the html build can be downloaded. This doesn't require any
|
||||
# additional configuration in docs/source/conf.py.
|
||||
#
|
||||
- htmlzip
|
||||
- epub
|
||||
|
||||
133
CONTRIBUTING.md
133
CONTRIBUTING.md
@@ -6,9 +6,134 @@ you can follow the [Jupyter contributor guide](https://jupyter.readthedocs.io/en
|
||||
Make sure to also follow [Project Jupyter's Code of Conduct](https://github.com/jupyter/governance/blob/HEAD/conduct/code_of_conduct.md)
|
||||
for a friendly and welcoming collaborative environment.
|
||||
|
||||
Please see our documentation on
|
||||
## Setting up a development environment
|
||||
|
||||
- [Setting up a development install](https://jupyterhub.readthedocs.io/en/latest/contributing/setup.html)
|
||||
- [Testing JupyterHub and linting code](https://jupyterhub.readthedocs.io/en/latest/contributing/tests.html)
|
||||
<!--
|
||||
https://jupyterhub.readthedocs.io/en/stable/contributing/setup.html
|
||||
contains a lot of the same information. Should we merge the docs and
|
||||
just have this page link to that one?
|
||||
-->
|
||||
|
||||
If you need some help, feel free to ask on [Gitter](https://gitter.im/jupyterhub/jupyterhub) or [Discourse](https://discourse.jupyter.org/).
|
||||
JupyterHub requires Python >= 3.5 and nodejs.
|
||||
|
||||
As a Python project, a development install of JupyterHub follows standard practices for the basics (steps 1-2).
|
||||
|
||||
1. clone the repo
|
||||
```bash
|
||||
git clone https://github.com/jupyterhub/jupyterhub
|
||||
```
|
||||
2. do a development install with pip
|
||||
|
||||
```bash
|
||||
cd jupyterhub
|
||||
python3 -m pip install --editable .
|
||||
```
|
||||
|
||||
3. install the development requirements,
|
||||
which include things like testing tools
|
||||
|
||||
```bash
|
||||
python3 -m pip install -r dev-requirements.txt
|
||||
```
|
||||
|
||||
4. install configurable-http-proxy with npm:
|
||||
|
||||
```bash
|
||||
npm install -g configurable-http-proxy
|
||||
```
|
||||
|
||||
5. set up pre-commit hooks for automatic code formatting, etc.
|
||||
|
||||
```bash
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
You can also invoke the pre-commit hook manually at any time with
|
||||
|
||||
```bash
|
||||
pre-commit run
|
||||
```
|
||||
|
||||
## Contributing
|
||||
|
||||
JupyterHub has adopted automatic code formatting so you shouldn't
|
||||
need to worry too much about your code style.
|
||||
As long as your code is valid,
|
||||
the pre-commit hook should take care of how it should look.
|
||||
You can invoke the pre-commit hook by hand at any time with:
|
||||
|
||||
```bash
|
||||
pre-commit run
|
||||
```
|
||||
|
||||
which should run any autoformatting on your code
|
||||
and tell you about any errors it couldn't fix automatically.
|
||||
You may also install [black integration](https://github.com/psf/black#editor-integration)
|
||||
into your text editor to format code automatically.
|
||||
|
||||
If you have already committed files before setting up the pre-commit
|
||||
hook with `pre-commit install`, you can fix everything up using
|
||||
`pre-commit run --all-files`. You need to make the fixing commit
|
||||
yourself after that.
|
||||
|
||||
## Testing
|
||||
|
||||
It's a good idea to write tests to exercise any new features,
|
||||
or that trigger any bugs that you have fixed to catch regressions.
|
||||
|
||||
You can run the tests with:
|
||||
|
||||
```bash
|
||||
pytest -v
|
||||
```
|
||||
|
||||
in the repo directory. If you want to just run certain tests,
|
||||
check out the [pytest docs](https://pytest.readthedocs.io/en/latest/usage.html)
|
||||
for how pytest can be called.
|
||||
For instance, to test only spawner-related things in the REST API:
|
||||
|
||||
```bash
|
||||
pytest -v -k spawn jupyterhub/tests/test_api.py
|
||||
```
|
||||
|
||||
The tests live in `jupyterhub/tests` and are organized roughly into:
|
||||
|
||||
1. `test_api.py` tests the REST API
|
||||
2. `test_pages.py` tests loading the HTML pages
|
||||
|
||||
and other collections of tests for different components.
|
||||
When writing a new test, there should usually be a test of
|
||||
similar functionality already written and related tests should
|
||||
be added nearby.
|
||||
|
||||
The fixtures live in `jupyterhub/tests/conftest.py`. There are
|
||||
fixtures that can be used for JupyterHub components, such as:
|
||||
|
||||
- `app`: an instance of JupyterHub with mocked parts
|
||||
- `auth_state_enabled`: enables persisting auth_state (like authentication tokens)
|
||||
- `db`: a sqlite in-memory DB session
|
||||
- `io_loop`: a Tornado event loop
|
||||
- `event_loop`: a new asyncio event loop
|
||||
- `user`: creates a new temporary user
|
||||
- `admin_user`: creates a new temporary admin user
|
||||
- single user servers
|
||||
- `cleanup_after`: allows cleanup of single user servers between tests
|
||||
- mocked service
|
||||
- `MockServiceSpawner`: a spawner that mocks services for testing with a short poll interval
|
||||
- `mockservice`: mocked service with no external service url
|
||||
- `mockservice_url`: mocked service with a url to test external services
|
||||
|
||||
And fixtures to add functionality or spawning behavior:
|
||||
|
||||
- `admin_access`: grants admin access
|
||||
- `no_patience`: sets slow-spawning timeouts to zero
|
||||
- `slow_spawn`: enables the SlowSpawner (a spawner that takes a few seconds to start)
|
||||
- `never_spawn`: enables the NeverSpawner (a spawner that will never start)
|
||||
- `bad_spawn`: enables the BadSpawner (a spawner that fails immediately)
|
||||
- `slow_bad_spawn`: enables the SlowBadSpawner (a spawner that fails after a short delay)
|
||||
|
||||
To read more about fixtures check out the
|
||||
[pytest docs](https://docs.pytest.org/en/latest/fixture.html)
|
||||
for how to use the existing fixtures, and how to create new ones.
|
||||
|
||||
When in doubt, feel free to [ask](https://gitter.im/jupyterhub/jupyterhub).
|
||||
|
||||
@@ -21,7 +21,7 @@
|
||||
# your jupyterhub_config.py will be added automatically
|
||||
# from your docker directory.
|
||||
|
||||
ARG BASE_IMAGE=ubuntu:22.04
|
||||
ARG BASE_IMAGE=ubuntu:focal-20200729
|
||||
FROM $BASE_IMAGE AS builder
|
||||
|
||||
USER root
|
||||
@@ -35,14 +35,12 @@ RUN apt-get update \
|
||||
python3-dev \
|
||||
python3-pip \
|
||||
python3-pycurl \
|
||||
python3-venv \
|
||||
nodejs \
|
||||
npm \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN python3 -m pip install --upgrade setuptools pip build wheel
|
||||
RUN npm install --global yarn
|
||||
RUN python3 -m pip install --upgrade setuptools pip wheel
|
||||
|
||||
# copy everything except whats in .dockerignore, its a
|
||||
# compromise between needing to rebuild and maintaining
|
||||
@@ -52,7 +50,7 @@ WORKDIR /src/jupyterhub
|
||||
|
||||
# Build client component packages (they will be copied into ./share and
|
||||
# packaged with the built wheel.)
|
||||
RUN python3 -m build --wheel
|
||||
RUN python3 setup.py bdist_wheel
|
||||
RUN python3 -m pip wheel --wheel-dir wheelhouse dist/*.whl
|
||||
|
||||
|
||||
|
||||
@@ -8,7 +8,6 @@ include *requirements.txt
|
||||
include Dockerfile
|
||||
|
||||
graft onbuild
|
||||
graft jsx
|
||||
graft jupyterhub
|
||||
graft scripts
|
||||
graft share
|
||||
@@ -19,10 +18,6 @@ graft ci
|
||||
graft docs
|
||||
prune docs/node_modules
|
||||
|
||||
# Intermediate javascript files
|
||||
prune jsx/node_modules
|
||||
prune jsx/build
|
||||
|
||||
# prune some large unused files from components
|
||||
prune share/jupyterhub/static/components/bootstrap/dist/css
|
||||
exclude share/jupyterhub/static/components/bootstrap/dist/fonts/*.svg
|
||||
|
||||
@@ -190,7 +190,7 @@ this a good choice for **testing JupyterHub on your desktop or laptop**.
|
||||
|
||||
If you want to run docker on a computer that has a public IP then you should
|
||||
(as in MUST) **secure it with ssl** by adding ssl options to your docker
|
||||
configuration or by using an ssl enabled proxy.
|
||||
configuration or by using a ssl enabled proxy.
|
||||
|
||||
[Mounting volumes](https://docs.docker.com/engine/admin/volumes/volumes/) will
|
||||
allow you to **store data outside the docker image (host system) so it will be persistent**, even when you start
|
||||
|
||||
49
RELEASE.md
49
RELEASE.md
@@ -1,42 +1,39 @@
|
||||
# How to make a release
|
||||
|
||||
`jupyterhub` is a package available on [PyPI][] and [conda-forge][].
|
||||
These are instructions on how to make a release.
|
||||
`jupyterhub` is a package [available on
|
||||
PyPI](https://pypi.org/project/jupyterhub/) and
|
||||
[conda-forge](https://conda-forge.org/).
|
||||
These are instructions on how to make a release on PyPI.
|
||||
The PyPI release is done automatically by CI when a tag is pushed.
|
||||
|
||||
## Pre-requisites
|
||||
For you to follow along according to these instructions, you need:
|
||||
|
||||
- Push rights to [jupyterhub/jupyterhub][]
|
||||
- Push rights to [conda-forge/jupyterhub-feedstock][]
|
||||
- To have push rights to the [jupyterhub GitHub
|
||||
repository](https://github.com/jupyterhub/jupyterhub).
|
||||
|
||||
## Steps to make a release
|
||||
|
||||
1. Create a PR updating `docs/source/changelog.md` with [github-activity][] and
|
||||
continue only when its merged.
|
||||
|
||||
```shell
|
||||
pip install github-activity
|
||||
|
||||
github-activity --heading-level=3 jupyterhub/jupyterhub
|
||||
```
|
||||
|
||||
1. Checkout main and make sure it is up to date.
|
||||
|
||||
```shell
|
||||
ORIGIN=${ORIGIN:-origin} # set to the canonical remote, e.g. 'upstream' if 'origin' is not the official repo
|
||||
git checkout main
|
||||
git fetch origin main
|
||||
git reset --hard origin/main
|
||||
git fetch $ORIGIN main
|
||||
git reset --hard $ORIGIN/main
|
||||
```
|
||||
|
||||
1. Update the version, make commits, and push a git tag with `tbump`.
|
||||
1. Make sure `docs/source/changelog.md` is up-to-date.
|
||||
[github-activity][] can help with this.
|
||||
|
||||
1. Update the version with `tbump`.
|
||||
You can see what will happen without making any changes with `tbump --dry-run ${VERSION}`
|
||||
|
||||
```shell
|
||||
pip install tbump
|
||||
tbump --dry-run ${VERSION}
|
||||
|
||||
tbump ${VERSION}
|
||||
```
|
||||
|
||||
Following this, the [CI system][] will build and publish a release.
|
||||
This will tag and publish a release,
|
||||
which will be finished on CI.
|
||||
|
||||
1. Reset the version back to dev, e.g. `2.1.0.dev` after releasing `2.0.0`
|
||||
|
||||
@@ -45,11 +42,9 @@ These are instructions on how to make a release.
|
||||
```
|
||||
|
||||
1. Following the release to PyPI, an automated PR should arrive to
|
||||
[conda-forge/jupyterhub-feedstock][] with instructions.
|
||||
[conda-forge/jupyterhub-feedstock][],
|
||||
check for the tests to succeed on this PR and then merge it to successfully
|
||||
update the package for `conda` on the conda-forge channel.
|
||||
|
||||
[pypi]: https://pypi.org/project/jupyterhub/
|
||||
[conda-forge]: https://anaconda.org/conda-forge/jupyterhub
|
||||
[jupyterhub/jupyterhub]: https://github.com/jupyterhub/jupyterhub
|
||||
[github-activity]: https://github.com/choldgraf/github-activity
|
||||
[conda-forge/jupyterhub-feedstock]: https://github.com/conda-forge/jupyterhub-feedstock
|
||||
[github-activity]: https://github.com/executablebooks/github-activity
|
||||
[ci system]: https://github.com/jupyterhub/jupyterhub/actions/workflows/release.yml
|
||||
|
||||
@@ -1,35 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# Check that installed package contains everything we expect
|
||||
|
||||
|
||||
from pathlib import Path
|
||||
|
||||
import jupyterhub
|
||||
from jupyterhub._data import DATA_FILES_PATH
|
||||
|
||||
print("Checking jupyterhub._data", end=" ")
|
||||
print(f"DATA_FILES_PATH={DATA_FILES_PATH}", end=" ")
|
||||
DATA_FILES_PATH = Path(DATA_FILES_PATH)
|
||||
assert DATA_FILES_PATH.is_dir(), DATA_FILES_PATH
|
||||
for subpath in (
|
||||
"templates/page.html",
|
||||
"static/css/style.min.css",
|
||||
"static/components/jquery/dist/jquery.js",
|
||||
"static/js/admin-react.js",
|
||||
):
|
||||
path = DATA_FILES_PATH / subpath
|
||||
assert path.is_file(), path
|
||||
|
||||
print("OK")
|
||||
|
||||
print("Checking package_data", end=" ")
|
||||
jupyterhub_path = Path(jupyterhub.__file__).parent.resolve()
|
||||
for subpath in (
|
||||
"alembic.ini",
|
||||
"alembic/versions/833da8570507_rbac.py",
|
||||
"event-schemas/server-actions/v1.yaml",
|
||||
):
|
||||
path = jupyterhub_path / subpath
|
||||
assert path.is_file(), path
|
||||
|
||||
print("OK")
|
||||
@@ -1,27 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# Check that sdist contains everything we expect
|
||||
|
||||
import sys
|
||||
import tarfile
|
||||
|
||||
expected_files = [
|
||||
"docs/requirements.txt",
|
||||
"jsx/package.json",
|
||||
"package.json",
|
||||
"README.md",
|
||||
]
|
||||
|
||||
assert len(sys.argv) == 2, "Expected one file"
|
||||
print(f"Checking {sys.argv[1]}")
|
||||
|
||||
tar = tarfile.open(name=sys.argv[1], mode="r:gz")
|
||||
try:
|
||||
# Remove leading jupyterhub-VERSION/
|
||||
filelist = {f.partition('/')[2] for f in tar.getnames()}
|
||||
finally:
|
||||
tar.close()
|
||||
|
||||
for e in expected_files:
|
||||
assert e in filelist, f"{e} not found"
|
||||
|
||||
print("OK")
|
||||
@@ -22,7 +22,7 @@ if [[ "$DB" == "mysql" ]]; then
|
||||
# ref server: https://hub.docker.com/_/mysql/
|
||||
# ref client: https://dev.mysql.com/doc/refman/5.7/en/setting-environment-variables.html
|
||||
#
|
||||
DOCKER_RUN_ARGS="-p 3306:3306 --env MYSQL_ALLOW_EMPTY_PASSWORD=1 mysql:8.0"
|
||||
DOCKER_RUN_ARGS="-p 3306:3306 --env MYSQL_ALLOW_EMPTY_PASSWORD=1 mysql:5.7"
|
||||
READINESS_CHECK="mysql --user root --execute \q"
|
||||
elif [[ "$DB" == "postgres" ]]; then
|
||||
# Environment variables can influence both the postgresql server in the
|
||||
@@ -36,7 +36,7 @@ elif [[ "$DB" == "postgres" ]]; then
|
||||
# used by the postgresql client psql, so we configure the user based on how
|
||||
# we want to connect.
|
||||
#
|
||||
DOCKER_RUN_ARGS="-p 5432:5432 --env "POSTGRES_USER=${PGUSER}" --env "POSTGRES_PASSWORD=${PGPASSWORD}" postgres:15.1"
|
||||
DOCKER_RUN_ARGS="-p 5432:5432 --env "POSTGRES_USER=${PGUSER}" --env "POSTGRES_PASSWORD=${PGPASSWORD}" postgres:9.5"
|
||||
READINESS_CHECK="psql --command \q"
|
||||
else
|
||||
echo '$DB must be mysql or postgres'
|
||||
|
||||
@@ -19,9 +19,8 @@ else
|
||||
fi
|
||||
|
||||
# Configure a set of databases in the database server for upgrade tests
|
||||
# this list must be in sync with versions in test_db.py:test_upgrade
|
||||
set -x
|
||||
for SUFFIX in '' _upgrade_110 _upgrade_122 _upgrade_130 _upgrade_150 _upgrade_211; do
|
||||
for SUFFIX in '' _upgrade_100 _upgrade_122 _upgrade_130; do
|
||||
$SQL_CLIENT "DROP DATABASE jupyterhub${SUFFIX};" 2>/dev/null || true
|
||||
$SQL_CLIENT "CREATE DATABASE jupyterhub${SUFFIX} ${EXTRA_CREATE_DATABASE_ARGS:-};"
|
||||
done
|
||||
|
||||
22
dev-requirements.txt
Normal file
22
dev-requirements.txt
Normal file
@@ -0,0 +1,22 @@
|
||||
-r requirements.txt
|
||||
# temporary pin of attrs for jsonschema 0.3.0a1
|
||||
# seems to be a pip bug
|
||||
attrs>=17.4.0
|
||||
beautifulsoup4
|
||||
codecov
|
||||
coverage
|
||||
cryptography
|
||||
html5lib # needed for beautifulsoup
|
||||
jupyterlab >=3
|
||||
mock
|
||||
pre-commit
|
||||
pytest>=3.3
|
||||
pytest-asyncio; python_version < "3.7"
|
||||
pytest-asyncio>=0.17; python_version >= "3.7"
|
||||
pytest-cov
|
||||
requests-mock
|
||||
tbump
|
||||
# blacklist urllib3 releases affected by https://github.com/urllib3/urllib3/issues/1683
|
||||
# I *think* this should only affect testing, not production
|
||||
urllib3!=1.25.4,!=1.25.5
|
||||
virtualenv
|
||||
@@ -1,11 +1,9 @@
|
||||
## What is Dockerfile.alpine
|
||||
|
||||
Dockerfile.alpine contains the base image for jupyterhub. It does not work independently, but only as part of a full jupyterhub cluster
|
||||
Dockerfile.alpine contains base image for jupyterhub. It does not work independently, but only as part of a full jupyterhub cluster
|
||||
|
||||
## How to use it?
|
||||
|
||||
You will need:
|
||||
|
||||
1. A running configurable-http-proxy, whose API is accessible.
|
||||
2. A jupyterhub_config file.
|
||||
3. Authentication and other libraries required by the specific jupyterhub_config file.
|
||||
@@ -17,6 +15,6 @@ You will need:
|
||||
- put both containers on the same network (e.g. docker network create jupyterhub; docker run ... --net jupyterhub)
|
||||
- tell jupyterhub where CHP is (e.g. c.ConfigurableHTTPProxy.api_url = 'http://chp:8001')
|
||||
- tell jupyterhub not to start the proxy itself (c.ConfigurableHTTPProxy.should_start = False)
|
||||
- Use a dummy authenticator for ease of testing. Update following in jupyterhub_config file
|
||||
- Use dummy authenticator for ease of testing. Update following in jupyterhub_config file
|
||||
- c.JupyterHub.authenticator_class = 'dummyauthenticator.DummyAuthenticator'
|
||||
- c.DummyAuthenticator.password = "your strong password"
|
||||
|
||||
@@ -4,11 +4,6 @@ from jupyterhub._data import DATA_FILES_PATH
|
||||
|
||||
print(f"DATA_FILES_PATH={DATA_FILES_PATH}")
|
||||
|
||||
for sub_path in (
|
||||
"templates",
|
||||
"static/components",
|
||||
"static/css/style.min.css",
|
||||
"static/js/admin-react.js",
|
||||
):
|
||||
for sub_path in ("templates", "static/components", "static/css/style.min.css"):
|
||||
path = os.path.join(DATA_FILES_PATH, sub_path)
|
||||
assert os.path.exists(path), path
|
||||
|
||||
@@ -63,9 +63,6 @@ scopes: source/rbac/scope-table.md
|
||||
source/rbac/scope-table.md: source/rbac/generate-scope-table.py
|
||||
python3 source/rbac/generate-scope-table.py
|
||||
|
||||
# If the pre-requisites for the html target is updated, also update the Read The
|
||||
# Docs section in docs/source/conf.py.
|
||||
#
|
||||
html: metrics scopes
|
||||
$(SPHINXBUILD) -b html $(ALLSPHINXOPTS) $(BUILDDIR)/html
|
||||
@echo
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import os
|
||||
from os.path import join
|
||||
|
||||
from pytablewriter import RstSimpleTableWriter
|
||||
from pytablewriter.style import Style
|
||||
|
||||
@@ -1,21 +1,12 @@
|
||||
# We install the jupyterhub package to help autodoc-traits inspect it and
|
||||
# generate documentation.
|
||||
#
|
||||
# FIXME: If there is a way for this requirements.txt file to pass a flag that
|
||||
# the build system can intercept to not build the javascript artifacts,
|
||||
# then do so so. That would mean that installing the documentation can
|
||||
# avoid needing node/npm installed.
|
||||
#
|
||||
--editable .
|
||||
-r ../requirements.txt
|
||||
|
||||
alabaster_jupyterhub
|
||||
autodoc-traits
|
||||
myst-parser
|
||||
pre-commit
|
||||
pydata-sphinx-theme
|
||||
pytablewriter>=0.56
|
||||
ruamel.yaml
|
||||
sphinx>=4
|
||||
sphinx>=1.7
|
||||
sphinx-copybutton
|
||||
sphinx-jsonschema
|
||||
sphinxext-opengraph
|
||||
sphinxext-rediraffe
|
||||
|
||||
@@ -6,7 +6,7 @@ info:
|
||||
description: The REST API for JupyterHub
|
||||
license:
|
||||
name: BSD-3-Clause
|
||||
version: 3.1.1
|
||||
version: 2.3.0
|
||||
servers:
|
||||
- url: /hub/api
|
||||
security:
|
||||
@@ -139,16 +139,6 @@ paths:
|
||||
If unspecified, use api_page_default_limit.
|
||||
schema:
|
||||
type: number
|
||||
- name: include_stopped_servers
|
||||
in: query
|
||||
description: |
|
||||
Include stopped servers in user model(s).
|
||||
Added in JupyterHub 3.0.
|
||||
Allows retrieval of information about stopped servers,
|
||||
such as activity and state fields.
|
||||
schema:
|
||||
type: boolean
|
||||
allowEmptyValue: true
|
||||
responses:
|
||||
200:
|
||||
description: The Hub's user list
|
||||
@@ -570,19 +560,7 @@ paths:
|
||||
description: A note attached to the token for future bookkeeping
|
||||
roles:
|
||||
type: array
|
||||
description: |
|
||||
A list of role names from which to derive scopes.
|
||||
This is a shortcut for assigning collections of scopes;
|
||||
Tokens do not retain role assignment.
|
||||
(Changed in 3.0: roles are immediately resolved to scopes
|
||||
instead of stored on roles.)
|
||||
items:
|
||||
type: string
|
||||
scopes:
|
||||
type: array
|
||||
description: |
|
||||
A list of scopes that the token should have.
|
||||
(new in JupyterHub 3.0).
|
||||
description: A list of role names that the token should have
|
||||
items:
|
||||
type: string
|
||||
required: false
|
||||
@@ -1170,11 +1148,7 @@ components:
|
||||
format: date-time
|
||||
servers:
|
||||
type: array
|
||||
description: |
|
||||
The servers for this user.
|
||||
By default: only includes _active_ servers.
|
||||
Changed in 3.0: if `?include_stopped_servers` parameter is specified,
|
||||
stopped servers will be included as well.
|
||||
description: The active servers for this user.
|
||||
items:
|
||||
$ref: "#/components/schemas/Server"
|
||||
auth_state:
|
||||
@@ -1196,15 +1170,6 @@ components:
|
||||
description: |
|
||||
Whether the server is ready for traffic.
|
||||
Will always be false when any transition is pending.
|
||||
stopped:
|
||||
type: boolean
|
||||
description: |
|
||||
Whether the server is stopped. Added in JupyterHub 3.0,
|
||||
and only useful when using the `?include_stopped_servers`
|
||||
request parameter.
|
||||
Now that stopped servers may be included (since JupyterHub 3.0),
|
||||
this is the simplest way to select stopped servers.
|
||||
Always equivalent to `not (ready or pending)`.
|
||||
pending:
|
||||
type: string
|
||||
description: |
|
||||
@@ -1349,16 +1314,7 @@ components:
|
||||
description: The service that owns the token (undefined of owned by a user)
|
||||
roles:
|
||||
type: array
|
||||
description:
|
||||
Deprecated in JupyterHub 3, always an empty list. Tokens have
|
||||
'scopes' starting from JupyterHub 3.
|
||||
items:
|
||||
type: string
|
||||
scopes:
|
||||
type: array
|
||||
description:
|
||||
List of scopes this token has been assigned. New in JupyterHub
|
||||
3. In JupyterHub 2.x, tokens were assigned 'roles' insead of scopes.
|
||||
description: The names of roles this token has
|
||||
items:
|
||||
type: string
|
||||
note:
|
||||
@@ -1414,9 +1370,6 @@ components:
|
||||
inherit:
|
||||
Everything that the token-owning entity can access _(metascope
|
||||
for tokens)_
|
||||
admin-ui:
|
||||
Access the admin page. Permission to take actions via the admin
|
||||
page granted separately.
|
||||
admin:users:
|
||||
Read, write, create and delete users and their authentication
|
||||
state, not including their servers or tokens.
|
||||
|
||||
@@ -1,308 +0,0 @@
|
||||
# Capacity planning
|
||||
|
||||
General capacity planning advice for JupyterHub is hard to give,
|
||||
because it depends almost entirely on what your users are doing,
|
||||
and what JupyterHub users do varies _wildly_ in terms of resource consumption.
|
||||
|
||||
**There is no single answer to "I have X users, what resources do I need?" or "How many users can I support with this machine?"**
|
||||
|
||||
Here are three _typical_ Jupyter use patterns that require vastly different resources:
|
||||
|
||||
- **Learning**: negligible resources because computation is mostly idle,
|
||||
e.g. students learning programming for the first time
|
||||
- **Production code**: very intense, sustained load, e.g. training machine learning models
|
||||
- **Bursting**: _mostly_ idle, but needs a lot of resources for short periods of time
|
||||
(interactive research often looks like this)
|
||||
|
||||
But just because there's no single answer doesn't mean we can't help.
|
||||
So we have gathered here some useful information to help you make your decisions
|
||||
about what resources you need based on how your users work,
|
||||
including the relative invariants in terms of resources that JupyterHub itself needs.
|
||||
|
||||
## JupyterHub infrastructure
|
||||
|
||||
JupyterHub consists of a few components that are always running.
|
||||
These take up very little resources,
|
||||
especially relative to the resources consumed by users when you have more than a few.
|
||||
|
||||
As an example, an instance of mybinder.org (running JupyterHub 1.5.0),
|
||||
running with typically ~100-150 users has:
|
||||
|
||||
| Component | CPU (mean/peak) | Memory (mean/peak) |
|
||||
| --------- | --------------- | ------------------ |
|
||||
| Hub | 4% / 13% | (230 MB / 260 MB) |
|
||||
| Proxy | 6% / 13% | (47 MB / 65 MB) |
|
||||
|
||||
So it would be pretty generous to allocate ~25% of one CPU core
|
||||
and ~500MB of RAM to overall JupyterHub infrastructure.
|
||||
|
||||
The rest is going to be up to your users.
|
||||
Per-user overhead from JupyterHub is typically negligible
|
||||
up to at least a few hundred concurrent active users.
|
||||
|
||||
```[figure} ../images/mybinder-hub-components-cpu-memory.png
|
||||
JupyterHub component resource usage for mybinder.org.
|
||||
```
|
||||
|
||||
## Factors to consider
|
||||
|
||||
### Static vs elastic resources
|
||||
|
||||
A big factor in planning resources is:
|
||||
**how much does it cost to change your mind?**
|
||||
If you are using a single shared machine with local storage,
|
||||
migrating to a new one because it turns out your users don't fit might be very costly.
|
||||
You will have to get a new machine, set it up, and maybe even migrate user data.
|
||||
|
||||
On the other hand, if you are using ephemeral resources,
|
||||
such as node pools in Kubernetes,
|
||||
changing resource types costs close to nothing
|
||||
because nodes can automatically be added or removed as needed.
|
||||
|
||||
Take that cost into account when you are picking how much memory or cpu to allocate to users.
|
||||
|
||||
Static resources (like [the-littlest-jupyterhub][]) provide for more **stable, predictable costs**,
|
||||
but elastic resources (like [zero-to-jupyterhub][]) tend to provide **lower overall costs**
|
||||
(especially when deployed with monitoring allowing cost optimizations over time),
|
||||
but which are **less predictable**.
|
||||
|
||||
[the-littlest-jupyterhub]: https://the-littlest-jupyterhub.readthedocs.io
|
||||
|
||||
[zero-to-jupyterhub]: https://zero-to-jupyterhub.readthedocs.io
|
||||
|
||||
(limits-requests)=
|
||||
|
||||
### Limit vs Request for resources
|
||||
|
||||
Many scheduling tools like Kubernetes have two separate ways of allocating resources to users.
|
||||
A **Request** or **Reservation** describes how much resources are _set aside_ for each user.
|
||||
Often, this doesn't have any practical effect other than deciding when a given machine is considered 'full'.
|
||||
If you are using expandable resources like an autoscaling Kubernetes cluster,
|
||||
a new node must be launched and added to the pool if you 'request' more resources than fit on currently running nodes (a cluster **scale-up event**).
|
||||
If you are running on a single VM, this describes how many users you can run at the same time, full stop.
|
||||
|
||||
A **Limit**, on the other hand, enforces a limit to how much resources any given user can consume.
|
||||
For more information on what happens when users try to exceed their limits, see [](oversubscription).
|
||||
|
||||
In the strictest, safest case, you can have these two numbers be the same.
|
||||
That means that each user is _limited_ to fit within the resources allocated to it.
|
||||
This avoids **[oversubscription](oversubscription)** of resources (allowing use of more than you have available),
|
||||
at the expense (in a literal, this-costs-money sense) of reserving lots of usually-idle capacity.
|
||||
|
||||
However, you often find that a small fraction of users use more resources than others.
|
||||
In this case you may give users limits that _go beyond the amount of resources requested_.
|
||||
This is called **oversubscribing** the resources available to users.
|
||||
|
||||
Having a gap between the request and the limit means you can fit a number of _typical_ users on a node (based on the request),
|
||||
but still limit how much a runaway user can gobble up for themselves.
|
||||
|
||||
(oversubscription)=
|
||||
|
||||
### Oversubscribed CPU is okay, running out of memory is bad
|
||||
|
||||
An important consideration when assigning resources to users is: **What happens when users need more than I've given them?**
|
||||
|
||||
A good summary to keep in mind:
|
||||
|
||||
> When tasks don't get enough CPU, things are slow.
|
||||
> When they don't get enough memory, things are broken.
|
||||
|
||||
This means it's **very important that users have enough memory**,
|
||||
but much less important that they always have exclusive access to all the CPU they can use.
|
||||
|
||||
This relates to [Limits and Requests](limits-requests),
|
||||
because these are the consequences of your limits and/or requests not matching what users actually try to use.
|
||||
|
||||
A table of mismatched resource allocation situations and their consequences:
|
||||
|
||||
| issue | consequence |
|
||||
| -------------------------------------------------------- | ------------------------------------------------------------------------------------- |
|
||||
| Requests too high | Unnecessarily high cost and/or low capacity. |
|
||||
| CPU limit too low | Poor performance experienced by users |
|
||||
| CPU oversubscribed (too-low request + too-high limit) | Poor performance across the system; may crash, if severe |
|
||||
| Memory limit too low | Servers killed by Out-of-Memory Killer (OOM); lost work for users |
|
||||
| Memory oversubscribed (too-low request + too-high limit) | System memory exhaustion - all kinds of hangs and crashes and weird errors. Very bad. |
|
||||
|
||||
Note that the 'oversubscribed' problem case is where the request is lower than _typical_ usage,
|
||||
meaning that the total reserved resources isn't enough for the total _actual_ consumption.
|
||||
This doesn't mean that _all_ your users exceed the request,
|
||||
just that the _limit_ gives enough room for the _average_ user to exceed the request.
|
||||
|
||||
All of these considerations are important _per node_.
|
||||
Larger nodes means more users per node, and therefore more users to average over.
|
||||
It also means more chances for multiple outliers on the same node.
|
||||
|
||||
### Example case for oversubscribing memory
|
||||
|
||||
Take for example, this system and sampling of user behavior:
|
||||
|
||||
- System memory = 8G
|
||||
- memory request = 1G, limit = 3G
|
||||
- typical 'heavy' user: 2G
|
||||
- typical 'light' user: 0.5G
|
||||
|
||||
This will assign 8 users to those 8G of RAM (remember: only requests are used for deciding when a machine is 'full').
|
||||
As long as the total of 8 users _actual_ usage is under 8G, everything is fine.
|
||||
But the _limit_ allows a total of 24G to be used,
|
||||
which would be a mess if everyone used their full limit.
|
||||
But _not_ everyone uses the full limit, which is the point!
|
||||
|
||||
This pattern is fine if 1/8 of your users are 'heavy' because _typical_ usage will be ~0.7G,
|
||||
and your total usage will be ~5G (`1 × 2 + 7 × 0.5 = 5.5`).
|
||||
|
||||
But if _50%_ of your users are 'heavy' you have a problem because that means your users will be trying to use 10G (`4 × 2 + 4 × 0.5 = 10`),
|
||||
which you don't have.
|
||||
|
||||
You can make guesses at these numbers, but the only _real_ way to get them is to measure (see [](measuring)).
|
||||
|
||||
### CPU:memory ratio
|
||||
|
||||
Most of the time, you'll find that only one resource is the limiting factor for your users.
|
||||
Most often it's memory, but for certain tasks, it could be CPU (or even GPUs).
|
||||
|
||||
Many cloud deployments have just one or a few fixed ratios of cpu to memory
|
||||
(e.g. 'general purpose', 'high memory', and 'high cpu').
|
||||
Setting your secondary resource allocation according to this ratio
|
||||
after selecting the more important limit results in a balanced resource allocation.
|
||||
|
||||
For instance, some of Google Cloud's ratios are:
|
||||
|
||||
| node type | GB RAM / CPU core |
|
||||
| ----------- | ----------------- |
|
||||
| n2-highmem | 8 |
|
||||
| n2-standard | 4 |
|
||||
| n2-highcpu | 1 |
|
||||
|
||||
(idleness)=
|
||||
|
||||
### Idleness
|
||||
|
||||
Jupyter being an interactive tool means people tend to spend a lot more time reading and thinking than actually running resource-intensive code.
|
||||
This significantly affects how much _cpu_ resources a typical active user needs,
|
||||
but often does not significantly affect the _memory_.
|
||||
|
||||
Ways to think about this:
|
||||
|
||||
- More idle users means unused CPU.
|
||||
This generally means setting your CPU _limit_ higher than your CPU _request_.
|
||||
- What do your users do when they _are_ running code?
|
||||
Is it typically single-threaded local computation in a notebook?
|
||||
If so, there's little reason to set a limit higher than 1 CPU core.
|
||||
- Do typical computations take a long time, or just a few seconds?
|
||||
Longer typical computations means it's more likely for users to be trying to use the CPU at the same moment,
|
||||
suggesting a higher _request_.
|
||||
- Even with idle users, parallel computation adds up quickly - one user fully loading 4 cores and 3 using almost nothing still averages to more than a full CPU core per user.
|
||||
- Long-running intense computations suggest higher requests.
|
||||
|
||||
Again, using mybinder.org as an example—we run around 100 users on 8-core nodes,
|
||||
and still see fairly _low_ overall CPU usage on each user node.
|
||||
The limit here is actually Kubernetes' pods per node, not memory _or_ CPU.
|
||||
This is likely a extreme case, as many Binder users come from clicking links on webpages
|
||||
without any actual intention of running code.
|
||||
|
||||
```[figure} ../images/mybinder-load5.png
|
||||
mybinder.org node CPU usage is low with 50-150 users sharing just 8 cores
|
||||
```
|
||||
|
||||
### Concurrent users and culling idle servers
|
||||
|
||||
Related to [][idleness], all of these resource consumptions and limits are calculated based on **concurrently active users**,
|
||||
not total users.
|
||||
You might have 10,000 users of your JupyterHub deployment, but only 100 of them running at any given time.
|
||||
That 100 is the main number you need to use for your capacity planning.
|
||||
JupyterHub costs scale very little based on the number of _total_ users,
|
||||
up to a point.
|
||||
|
||||
There are two important definitions for **active user**:
|
||||
|
||||
- Are they _actually_ there (i.e. a human interacting with Jupyter, or running code that might be )
|
||||
- Is their server running (this is where resource reservations and limits are actually applied)
|
||||
|
||||
Connecting those two definitions (how long are servers running if their humans aren't using them) is an important area of deployment configuration, usually implemented via the [JupyterHub idle culler service][idle-culler].
|
||||
|
||||
[idle-culler]: https://github.com/jupyterhub/jupyterhub-idle-culler
|
||||
|
||||
There are a lot of considerations when it comes to culling idle users that will depend:
|
||||
|
||||
- How much does it save me to shut down user servers? (e.g. keeping an elastic cluster small, or keeping a fixed-size deployment available to active users)
|
||||
- How much does it cost my users to have their servers shut down? (e.g. lost work if shutdown prematurely)
|
||||
- How easy do I want it to be for users to keep their servers running? (e.g. Do they want to run unattended simulations overnight? Do you want them to?)
|
||||
|
||||
Like many other things in this guide, there are many correct answers leading to different configuration choices.
|
||||
For more detail on culling configuration and considerations, consult the [JupyterHub idle culler documentation][idle-culler].
|
||||
|
||||
## More tips
|
||||
|
||||
### Start strict and generous, then measure
|
||||
|
||||
A good tip, in general, is to give your users as much resources as you can afford that you think they _might_ use.
|
||||
Then, use resource usage metrics like prometheus to analyze what your users _actually_ need,
|
||||
and tune accordingly.
|
||||
Remember: **Limits affect your user experience and stability. Requests mostly affect your costs**.
|
||||
|
||||
For example, a sensible starting point (lacking any other information) might be:
|
||||
|
||||
```yaml
|
||||
request:
|
||||
cpu: 0.5
|
||||
mem: 2G
|
||||
limit:
|
||||
cpu: 1
|
||||
mem: 2G
|
||||
```
|
||||
|
||||
(more memory if significant computations are likely - machine learning models, data analysis, etc.)
|
||||
|
||||
Some actions
|
||||
|
||||
- If you see out-of-memory killer events, increase the limit (or talk to your users!)
|
||||
- If you see typical memory well below your limit, reduce the request (but not the limit)
|
||||
- If _nobody_ uses that much memory, reduce your limit
|
||||
- If CPU is your limiting scheduling factor and your CPUs are mostly idle,
|
||||
reduce the cpu request (maybe even to 0!).
|
||||
- If CPU usage continues to be low, increase the limit to 2 or 4 to allow bursts of parallel execution.
|
||||
|
||||
(measuring)=
|
||||
|
||||
### Measuring user resource consumption
|
||||
|
||||
It is _highly_ recommended to deploy monitoring services such as [Prometheus][]
|
||||
and [Grafana][] to get a view of your users' resource usage.
|
||||
This is the only way to truly know what your users need.
|
||||
|
||||
JupyterHub has some experimental [grafana dashboards][] you can use as a starting point,
|
||||
to keep an eye on your resource usage.
|
||||
Here are some sample charts from (again from mybinder.org),
|
||||
showing >90% of users using less than 10% CPU and 200MB,
|
||||
but a few outliers near the limit of 1 CPU and 2GB of RAM.
|
||||
This is the kind of information you can use to tune your requests and limits.
|
||||
|
||||

|
||||
|
||||
[prometheus]: https://prometheus.io
|
||||
[grafana]: https://grafana.com
|
||||
[grafana dashboards]: https://github.com/jupyterhub/grafana-dashboards
|
||||
|
||||
### Measuring costs
|
||||
|
||||
Measuring costs may be as important as measuring your users activity.
|
||||
If you are using a cloud provider, you can often use cost thresholds and quotas to instruct them to notify you if your costs are too high,
|
||||
e.g. "Have AWS send me an email if I hit X spending trajectory on week 3 of the month."
|
||||
You can then use this information to tune your resources based on what you can afford.
|
||||
You can mix this information with user resource consumption to figure out if you have a problem,
|
||||
e.g. "my users really do need X resources, but I can only afford to give them 80% of X."
|
||||
This information may prove useful when asking your budget-approving folks for more funds.
|
||||
|
||||
### Additional resources
|
||||
|
||||
There are lots of other resources for cost and capacity planning that may be specific to JupyterHub and/or your cloud provider.
|
||||
|
||||
Here are some useful links to other resources
|
||||
|
||||
- [Zero to JupyterHub](https://zero-to-jupyterhub.readthedocs.io) documentation on
|
||||
- [projecting costs](https://zero-to-jupyterhub.readthedocs.io/en/latest/administrator/cost.html)
|
||||
- [configuring user resources](https://zero-to-jupyterhub.readthedocs.io/en/latest/jupyterhub/customizing/user-resources.html)
|
||||
- Cloud platform cost calculators:
|
||||
- [Google Cloud](https://cloud.google.com/products/calculator/)
|
||||
- [Amazon AWS](https://calculator.s3.amazonaws.com)
|
||||
- [Microsoft Azure](https://azure.microsoft.com/en-us/pricing/calculator/)
|
||||
@@ -1,33 +1,33 @@
|
||||
# Interpreting common log messages
|
||||
|
||||
When debugging errors and outages, looking at the logs emitted by
|
||||
JupyterHub is very helpful. This document intends to describe some common
|
||||
log messages, what they mean and what are the most common causes that generated them, as well as some possible ways to fix them.
|
||||
JupyterHub is very helpful. This document tries to document some common
|
||||
log messages, and what they mean.
|
||||
|
||||
## Failing suspected API request to not-running server
|
||||
|
||||
### Example
|
||||
|
||||
Your logs might be littered with lines that look scary
|
||||
Your logs might be littered with lines that might look slightly scary
|
||||
|
||||
```
|
||||
[W 2022-03-10 17:25:19.774 JupyterHub base:1349] Failing suspected API request to not-running server: /hub/user/<user-name>/api/metrics/v1
|
||||
```
|
||||
|
||||
### Cause
|
||||
|
||||
This likely means that the user's server has stopped running but they
|
||||
still have a browser tab open. For example, you might have 3 tabs open and you shut
|
||||
the server down via one.
|
||||
Another possible reason could be that you closed your laptop and the server was culled for inactivity, then reopened the laptop!
|
||||
However, the client-side code (JupyterLab, Classic Notebook, etc) doesn't interpret the shut-down server and continues to make some API requests.
|
||||
### Most likely cause
|
||||
|
||||
This likely means is that the user's server has stopped running but they
|
||||
still have a browser tab open. For example, you might have 3 tabs open, and shut
|
||||
your server down via one. Or you closed your laptop, your server was
|
||||
culled for inactivity, and then you reopen your laptop again! The
|
||||
client side code (JupyterLab, Classic Notebook, etc) does not know
|
||||
yet that the server is dead, and continues to make some API requests.
|
||||
JupyterHub's architecture means that the proxy routes all requests that
|
||||
don't go to a running user server to the hub process itself. The hub
|
||||
process then explicitly returns a failure response, so the client knows
|
||||
that the server is not running anymore. This is used by JupyterLab to
|
||||
inform the user that the server is not running anymore, and provide an option
|
||||
to restart it.
|
||||
tell you your server is not running anymore, and offer you the option
|
||||
to let you restart it.
|
||||
|
||||
Most commonly, you'll see this in reference to the `/api/metrics/v1`
|
||||
URL, used by [jupyter-resource-usage](https://github.com/jupyter-server/jupyter-resource-usage).
|
||||
@@ -47,9 +47,9 @@ This log message is benign, and there is usually no action for you to take.
|
||||
### Cause
|
||||
|
||||
JupyterHub requires the `jupyterhub` python package installed inside the image or
|
||||
environment, the user server starts in. This message indicates that the version of
|
||||
environment the user server starts in. This message indicates that the version of
|
||||
the `jupyterhub` package installed inside the user image or environment is not
|
||||
the same as the JupyterHub server's version itself. This is not necessarily always a
|
||||
the same version as the JupyterHub server itself. This is not necessarily always a
|
||||
problem - some version drift is mostly acceptable, and the only two known cases of
|
||||
breakage are across the 0.7 and 2.0 version releases. In those cases, issues pop
|
||||
up immediately after upgrading your version of JupyterHub, so **always check the JupyterHub
|
||||
@@ -67,6 +67,6 @@ aligned, rather than as an indicator of an existing problem.
|
||||
### Actions you can take
|
||||
|
||||
Upgrade the version of the `jupyterhub` package in your user environment or image
|
||||
so that it matches the version of JupyterHub running your JupyterHub server! If you
|
||||
so it matches the version of JupyterHub running your JupyterHub server! If you
|
||||
are using the [zero-to-jupyterhub](https://z2jh.jupyter.org) helm chart, you can find the appropriate
|
||||
version of the `jupyterhub` package to install in your user image [here](https://jupyterhub.github.io/helm-chart/)
|
||||
|
||||
@@ -6,34 +6,34 @@ JupyterHub offers easy upgrade pathways between minor versions. This
|
||||
document describes how to do these upgrades.
|
||||
|
||||
If you are using :ref:`a JupyterHub distribution <index/distributions>`, you
|
||||
should consult the distribution's documentation on how to upgrade. This documentation is
|
||||
for those who have set up their JupyterHub without using a distribution.
|
||||
should consult the distribution's documentation on how to upgrade. This
|
||||
document is if you have set up your own JupyterHub without using a
|
||||
distribution.
|
||||
|
||||
This documentation is lengthy because it is quite detailed. Most likely, upgrading
|
||||
It is long because is pretty detailed! Most likely, upgrading
|
||||
JupyterHub is painless, quick and with minimal user interruption.
|
||||
|
||||
The steps are discussed in detail, so if you get stuck at any step you can always refer to this guide.
|
||||
|
||||
Read the Changelog
|
||||
==================
|
||||
|
||||
The `changelog <../changelog.md>`_ contains information on what has
|
||||
changed with the new JupyterHub release and any deprecation warnings.
|
||||
The `changelog <../changelog.html>`_ contains information on what has
|
||||
changed with the new JupyterHub release, and any deprecation warnings.
|
||||
Read these notes to familiarize yourself with the coming changes. There
|
||||
might be new releases of the authenticators & spawners you use, so
|
||||
might be new releases of authenticators & spawners you are using, so
|
||||
read the changelogs for those too!
|
||||
|
||||
Notify your users
|
||||
=================
|
||||
|
||||
If you use the default configuration where ``configurable-http-proxy``
|
||||
If you are using the default configuration where ``configurable-http-proxy``
|
||||
is managed by JupyterHub, your users will see service disruption during
|
||||
the upgrade process. You should notify them, and pick a time to do the
|
||||
upgrade where they will be least disrupted.
|
||||
|
||||
If you use a different proxy or run ``configurable-http-proxy``
|
||||
If you are using a different proxy, or running ``configurable-http-proxy``
|
||||
independent of JupyterHub, your users will be able to continue using notebook
|
||||
servers they had already launched, but will not be able to launch new servers or sign in.
|
||||
servers they had already launched, but will not be able to launch new servers
|
||||
nor sign in.
|
||||
|
||||
|
||||
Backup database & config
|
||||
@@ -41,37 +41,37 @@ Backup database & config
|
||||
|
||||
Before doing an upgrade, it is critical to back up:
|
||||
|
||||
#. Your JupyterHub database (SQLite by default, or MySQL / Postgres if you used those).
|
||||
If you use SQLite (the default), you should backup the ``jupyterhub.sqlite`` file.
|
||||
|
||||
#. Your JupyterHub database (sqlite by default, or MySQL / Postgres
|
||||
if you used those). If you are using sqlite (the default), you
|
||||
should backup the ``jupyterhub.sqlite`` file.
|
||||
#. Your ``jupyterhub_config.py`` file.
|
||||
|
||||
#. Your users' home directories. This is unlikely to be affected directly by
|
||||
a JupyterHub upgrade, but we recommend a backup since user data is critical.
|
||||
#. Your user's home directories. This is unlikely to be affected directly by
|
||||
a JupyterHub upgrade, but we recommend a backup since user data is very
|
||||
critical.
|
||||
|
||||
|
||||
Shut down JupyterHub
|
||||
====================
|
||||
Shutdown JupyterHub
|
||||
===================
|
||||
|
||||
Shut down the JupyterHub process. This would vary depending on how you
|
||||
have set up JupyterHub to run. It is most likely using a process
|
||||
Shutdown the JupyterHub process. This would vary depending on how you
|
||||
have set up JupyterHub to run. Most likely, it is using a process
|
||||
supervisor of some sort (``systemd`` or ``supervisord`` or even ``docker``).
|
||||
Use the supervisor-specific command to stop the JupyterHub process.
|
||||
Use the supervisor specific command to stop the JupyterHub process.
|
||||
|
||||
Upgrade JupyterHub packages
|
||||
===========================
|
||||
|
||||
There are two environments where the ``jupyterhub`` package is installed:
|
||||
|
||||
#. The *hub environment*: where the JupyterHub server process
|
||||
#. The *hub environment*, which is where the JupyterHub server process
|
||||
runs. This is started with the ``jupyterhub`` command, and is what
|
||||
people generally think of as JupyterHub.
|
||||
|
||||
#. The *notebook user environments*: where the user notebook
|
||||
#. The *notebook user environments*. This is where the user notebook
|
||||
servers are launched from, and is probably custom to your own
|
||||
installation. This could be just one environment (different from the
|
||||
hub environment) that is shared by all users, one environment
|
||||
per user, or the same environment as the hub environment. The hub
|
||||
per user, or same environment as the hub environment. The hub
|
||||
launched the ``jupyterhub-singleuser`` command in this environment,
|
||||
which in turn starts the notebook server.
|
||||
|
||||
@@ -92,8 +92,10 @@ with:
|
||||
|
||||
conda install -c conda-forge jupyterhub==<version>
|
||||
|
||||
Where ``<version>`` is the version of JupyterHub you are upgrading to.
|
||||
|
||||
You should also check for new releases of the authenticator & spawner you
|
||||
are using. You might wish to upgrade those packages, too, along with JupyterHub
|
||||
are using. You might wish to upgrade those packages too along with JupyterHub,
|
||||
or upgrade them separately.
|
||||
|
||||
Upgrade JupyterHub database
|
||||
@@ -107,7 +109,7 @@ database. From the hub environment, in the same directory as your
|
||||
|
||||
jupyterhub upgrade-db
|
||||
|
||||
This should find the location of your database, and run the necessary upgrades
|
||||
This should find the location of your database, and run necessary upgrades
|
||||
for it.
|
||||
|
||||
SQLite database disadvantages
|
||||
@@ -116,11 +118,11 @@ SQLite database disadvantages
|
||||
SQLite has some disadvantages when it comes to upgrading JupyterHub. These
|
||||
are:
|
||||
|
||||
- ``upgrade-db`` may not work, and you may need to delete your database
|
||||
- ``upgrade-db`` may not work, and you may need delete your database
|
||||
and start with a fresh one.
|
||||
- ``downgrade-db`` **will not** work if you want to rollback to an
|
||||
earlier version, so backup the ``jupyterhub.sqlite`` file before
|
||||
upgrading.
|
||||
upgrading
|
||||
|
||||
What happens if I delete my database?
|
||||
-------------------------------------
|
||||
@@ -135,10 +137,10 @@ resides only in the Hub database includes:
|
||||
If the following conditions are true, you should be fine clearing the
|
||||
Hub database and starting over:
|
||||
|
||||
- users specified in the config file, or login using an external
|
||||
- users specified in config file, or login using an external
|
||||
authentication provider (Google, GitHub, LDAP, etc)
|
||||
- user servers are stopped during the upgrade
|
||||
- don't mind causing users to log in again after the upgrade
|
||||
- user servers are stopped during upgrade
|
||||
- don't mind causing users to login again after upgrade
|
||||
|
||||
Start JupyterHub
|
||||
================
|
||||
@@ -146,7 +148,7 @@ Start JupyterHub
|
||||
Once the database upgrade is completed, start the ``jupyterhub``
|
||||
process again.
|
||||
|
||||
#. Log in and start the server to make sure things work as
|
||||
#. Log-in and start the server to make sure things work as
|
||||
expected.
|
||||
#. Check the logs for any errors or deprecation warnings. You
|
||||
might have to update your ``jupyterhub_config.py`` file to
|
||||
|
||||
File diff suppressed because one or more lines are too long
@@ -1,70 +1,70 @@
|
||||
# Configuration file for Sphinx to build our documentation to HTML.
|
||||
#
|
||||
# Configuration reference: https://www.sphinx-doc.org/en/master/usage/configuration.html
|
||||
#
|
||||
import contextlib
|
||||
import datetime
|
||||
import io
|
||||
import os
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
from docutils import nodes
|
||||
from sphinx.directives.other import SphinxDirective
|
||||
# Set paths
|
||||
sys.path.insert(0, os.path.abspath('.'))
|
||||
|
||||
import jupyterhub
|
||||
from jupyterhub.app import JupyterHub
|
||||
# -- General configuration ------------------------------------------------
|
||||
|
||||
# -- Project information -----------------------------------------------------
|
||||
# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
|
||||
#
|
||||
project = "JupyterHub"
|
||||
author = "Project Jupyter Contributors"
|
||||
copyright = f"{datetime.date.today().year}, {author}"
|
||||
version = "%i.%i" % jupyterhub.version_info[:2]
|
||||
release = jupyterhub.__version__
|
||||
# Minimal Sphinx version
|
||||
needs_sphinx = '1.4'
|
||||
|
||||
|
||||
# -- General Sphinx configuration --------------------------------------------
|
||||
# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
|
||||
#
|
||||
# Sphinx extension modules
|
||||
extensions = [
|
||||
"sphinx.ext.autodoc",
|
||||
"sphinx.ext.intersphinx",
|
||||
"sphinx.ext.napoleon",
|
||||
"autodoc_traits",
|
||||
"sphinx_copybutton",
|
||||
"sphinx-jsonschema",
|
||||
"sphinxext.opengraph",
|
||||
"sphinxext.rediraffe",
|
||||
"myst_parser",
|
||||
'sphinx.ext.autodoc',
|
||||
'sphinx.ext.intersphinx',
|
||||
'sphinx.ext.napoleon',
|
||||
'autodoc_traits',
|
||||
'sphinx_copybutton',
|
||||
'sphinx-jsonschema',
|
||||
'myst_parser',
|
||||
]
|
||||
root_doc = "index"
|
||||
source_suffix = [".md", ".rst"]
|
||||
# default_role let's use use `foo` instead of ``foo`` in rST
|
||||
default_role = "literal"
|
||||
|
||||
|
||||
# -- MyST configuration ------------------------------------------------------
|
||||
# ref: https://myst-parser.readthedocs.io/en/latest/configuration.html
|
||||
#
|
||||
myst_heading_anchors = 2
|
||||
myst_enable_extensions = [
|
||||
"colon_fence",
|
||||
"deflist",
|
||||
'colon_fence',
|
||||
'deflist',
|
||||
]
|
||||
# The master toctree document.
|
||||
master_doc = 'index'
|
||||
|
||||
# General information about the project.
|
||||
project = 'JupyterHub'
|
||||
copyright = '2016, Project Jupyter team'
|
||||
author = 'Project Jupyter team'
|
||||
|
||||
# -- Custom directives to generate documentation -----------------------------
|
||||
# ref: https://myst-parser.readthedocs.io/en/latest/syntax/roles-and-directives.html
|
||||
#
|
||||
# We define custom directives to help us generate documentation using Python on
|
||||
# demand when referenced from our documentation files.
|
||||
#
|
||||
# Autopopulate version
|
||||
from os.path import dirname
|
||||
|
||||
# Create a temp instance of JupyterHub for use by two separate directive classes
|
||||
# to get the output from using the "--generate-config" and "--help-all" CLI
|
||||
# flags respectively.
|
||||
#
|
||||
docs = dirname(dirname(__file__))
|
||||
root = dirname(docs)
|
||||
sys.path.insert(0, root)
|
||||
|
||||
import jupyterhub
|
||||
|
||||
# The short X.Y version.
|
||||
version = '%i.%i' % jupyterhub.version_info[:2]
|
||||
# The full version, including alpha/beta/rc tags.
|
||||
release = jupyterhub.__version__
|
||||
|
||||
language = None
|
||||
exclude_patterns = []
|
||||
pygments_style = 'sphinx'
|
||||
todo_include_todos = False
|
||||
|
||||
# Set the default role so we can use `foo` instead of ``foo``
|
||||
default_role = 'literal'
|
||||
|
||||
# -- Config -------------------------------------------------------------
|
||||
from jupyterhub.app import JupyterHub
|
||||
from docutils import nodes
|
||||
from sphinx.directives.other import SphinxDirective
|
||||
from contextlib import redirect_stdout
|
||||
from io import StringIO
|
||||
|
||||
# create a temp instance of JupyterHub just to get the output of the generate-config
|
||||
# and help --all commands.
|
||||
jupyterhub_app = JupyterHub()
|
||||
|
||||
|
||||
@@ -81,8 +81,8 @@ class ConfigDirective(SphinxDirective):
|
||||
# The generated configuration file for this version
|
||||
generated_config = jupyterhub_app.generate_config_file()
|
||||
# post-process output
|
||||
home_dir = os.environ["HOME"]
|
||||
generated_config = generated_config.replace(home_dir, "$HOME", 1)
|
||||
home_dir = os.environ['HOME']
|
||||
generated_config = generated_config.replace(home_dir, '$HOME', 1)
|
||||
par = nodes.literal_block(text=generated_config)
|
||||
return [par]
|
||||
|
||||
@@ -98,55 +98,39 @@ class HelpAllDirective(SphinxDirective):
|
||||
|
||||
def run(self):
|
||||
# The output of the help command for this version
|
||||
buffer = io.StringIO()
|
||||
with contextlib.redirect_stdout(buffer):
|
||||
jupyterhub_app.print_help("--help-all")
|
||||
buffer = StringIO()
|
||||
with redirect_stdout(buffer):
|
||||
jupyterhub_app.print_help('--help-all')
|
||||
all_help = buffer.getvalue()
|
||||
# post-process output
|
||||
home_dir = os.environ["HOME"]
|
||||
all_help = all_help.replace(home_dir, "$HOME", 1)
|
||||
home_dir = os.environ['HOME']
|
||||
all_help = all_help.replace(home_dir, '$HOME', 1)
|
||||
par = nodes.literal_block(text=all_help)
|
||||
return [par]
|
||||
|
||||
|
||||
def setup(app):
|
||||
app.add_css_file("custom.css")
|
||||
app.add_directive("jupyterhub-generate-config", ConfigDirective)
|
||||
app.add_directive("jupyterhub-help-all", HelpAllDirective)
|
||||
app.add_css_file('custom.css')
|
||||
app.add_directive('jupyterhub-generate-config', ConfigDirective)
|
||||
app.add_directive('jupyterhub-help-all', HelpAllDirective)
|
||||
|
||||
|
||||
# -- Read The Docs -----------------------------------------------------------
|
||||
#
|
||||
# Since RTD runs sphinx-build directly without running "make html", we run the
|
||||
# pre-requisite steps for "make html" from here if needed.
|
||||
#
|
||||
if os.environ.get("READTHEDOCS"):
|
||||
docs = os.path.dirname(os.path.dirname(__file__))
|
||||
subprocess.check_call(["make", "metrics", "scopes"], cwd=docs)
|
||||
source_suffix = ['.rst', '.md']
|
||||
# source_encoding = 'utf-8-sig'
|
||||
|
||||
# -- Options for HTML output ----------------------------------------------
|
||||
|
||||
# -- Spell checking ----------------------------------------------------------
|
||||
# ref: https://sphinxcontrib-spelling.readthedocs.io/en/latest/customize.html#configuration-options
|
||||
#
|
||||
# The "sphinxcontrib.spelling" extension is optionally enabled if its available.
|
||||
#
|
||||
try:
|
||||
import sphinxcontrib.spelling # noqa
|
||||
except ImportError:
|
||||
pass
|
||||
else:
|
||||
extensions.append("sphinxcontrib.spelling")
|
||||
spelling_word_list_filename = "spelling_wordlist.txt"
|
||||
# The theme to use for HTML and HTML Help pages.
|
||||
html_theme = 'pydata_sphinx_theme'
|
||||
|
||||
html_logo = '_static/images/logo/logo.png'
|
||||
html_favicon = '_static/images/logo/favicon.ico'
|
||||
|
||||
# -- Options for HTML output -------------------------------------------------
|
||||
# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
|
||||
#
|
||||
html_logo = "_static/images/logo/logo.png"
|
||||
html_favicon = "_static/images/logo/favicon.ico"
|
||||
html_static_path = ["_static"]
|
||||
# Paths that contain custom static files (such as style sheets)
|
||||
html_static_path = ['_static']
|
||||
|
||||
htmlhelp_basename = 'JupyterHubdoc'
|
||||
|
||||
html_theme = "pydata_sphinx_theme"
|
||||
html_theme_options = {
|
||||
"icon_links": [
|
||||
{
|
||||
@@ -163,53 +147,111 @@ html_theme_options = {
|
||||
"use_edit_page_button": True,
|
||||
"navbar_align": "left",
|
||||
}
|
||||
|
||||
html_context = {
|
||||
"github_user": "jupyterhub",
|
||||
"github_repo": "jupyterhub",
|
||||
"github_version": "main",
|
||||
"doc_path": "docs/source",
|
||||
"doc_path": "docs",
|
||||
}
|
||||
|
||||
# -- Options for LaTeX output ---------------------------------------------
|
||||
|
||||
# -- Options for linkcheck builder -------------------------------------------
|
||||
# ref: https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-the-linkcheck-builder
|
||||
#
|
||||
linkcheck_ignore = [
|
||||
r"(.*)github\.com(.*)#", # javascript based anchors
|
||||
r"(.*)/#%21(.*)/(.*)", # /#!forum/jupyter - encoded anchor edge case
|
||||
r"https://github.com/[^/]*$", # too many github usernames / searches in changelog
|
||||
"https://github.com/jupyterhub/jupyterhub/pull/", # too many PRs in changelog
|
||||
"https://github.com/jupyterhub/jupyterhub/compare/", # too many comparisons in changelog
|
||||
]
|
||||
linkcheck_anchors_ignore = [
|
||||
"/#!",
|
||||
"/#%21",
|
||||
latex_elements = {
|
||||
# 'papersize': 'letterpaper',
|
||||
# 'pointsize': '10pt',
|
||||
# 'preamble': '',
|
||||
# 'figure_align': 'htbp',
|
||||
}
|
||||
|
||||
# Grouping the document tree into LaTeX files. List of tuples
|
||||
# (source start file, target name, title,
|
||||
# author, documentclass [howto, manual, or own class]).
|
||||
latex_documents = [
|
||||
(
|
||||
master_doc,
|
||||
'JupyterHub.tex',
|
||||
'JupyterHub Documentation',
|
||||
'Project Jupyter team',
|
||||
'manual',
|
||||
)
|
||||
]
|
||||
|
||||
# latex_logo = None
|
||||
# latex_use_parts = False
|
||||
# latex_show_pagerefs = False
|
||||
# latex_show_urls = False
|
||||
# latex_appendices = []
|
||||
# latex_domain_indices = True
|
||||
|
||||
|
||||
# -- manual page output -------------------------------------------------
|
||||
|
||||
# One entry per manual page. List of tuples
|
||||
# (source start file, name, description, authors, manual section).
|
||||
man_pages = [(master_doc, 'jupyterhub', 'JupyterHub Documentation', [author], 1)]
|
||||
|
||||
# man_show_urls = False
|
||||
|
||||
|
||||
# -- Texinfo output -----------------------------------------------------
|
||||
|
||||
# Grouping the document tree into Texinfo files. List of tuples
|
||||
# (source start file, target name, title, author,
|
||||
# dir menu entry, description, category)
|
||||
texinfo_documents = [
|
||||
(
|
||||
master_doc,
|
||||
'JupyterHub',
|
||||
'JupyterHub Documentation',
|
||||
author,
|
||||
'JupyterHub',
|
||||
'One line description of project.',
|
||||
'Miscellaneous',
|
||||
)
|
||||
]
|
||||
|
||||
# texinfo_appendices = []
|
||||
# texinfo_domain_indices = True
|
||||
# texinfo_show_urls = 'footnote'
|
||||
# texinfo_no_detailmenu = False
|
||||
|
||||
|
||||
# -- Epub output --------------------------------------------------------
|
||||
|
||||
# Bibliographic Dublin Core info.
|
||||
epub_title = project
|
||||
epub_author = author
|
||||
epub_publisher = author
|
||||
epub_copyright = copyright
|
||||
|
||||
# A list of files that should not be packed into the epub file.
|
||||
epub_exclude_files = ['search.html']
|
||||
|
||||
# -- Intersphinx ----------------------------------------------------------
|
||||
|
||||
# -- Intersphinx -------------------------------------------------------------
|
||||
# ref: https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#configuration
|
||||
#
|
||||
intersphinx_mapping = {
|
||||
"python": ("https://docs.python.org/3/", None),
|
||||
"tornado": ("https://www.tornadoweb.org/en/stable/", None),
|
||||
'python': ('https://docs.python.org/3/', None),
|
||||
'tornado': ('https://www.tornadoweb.org/en/stable/', None),
|
||||
}
|
||||
# -- Options for the opengraph extension -------------------------------------
|
||||
# ref: https://github.com/wpilibsuite/sphinxext-opengraph#options
|
||||
#
|
||||
# ogp_site_url is set automatically by RTD
|
||||
ogp_image = "_static/logo.png"
|
||||
ogp_use_first_image = True
|
||||
|
||||
# -- Read The Docs --------------------------------------------------------
|
||||
|
||||
# -- Options for the rediraffe extension -------------------------------------
|
||||
# ref: https://github.com/wpilibsuite/sphinxext-rediraffe#readme
|
||||
#
|
||||
# This extensions help us relocated content without breaking links. If a
|
||||
# document is moved internally, a redirect like should be configured below to
|
||||
# help us not break links.
|
||||
#
|
||||
rediraffe_branch = "main"
|
||||
rediraffe_redirects = {
|
||||
# "old-file": "new-folder/new-file-name",
|
||||
}
|
||||
on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
|
||||
if on_rtd:
|
||||
# readthedocs.org uses their theme by default, so no need to specify it
|
||||
# build both metrics and rest-api, since RTD doesn't run make
|
||||
from subprocess import check_call as sh
|
||||
|
||||
sh(['make', 'metrics', 'scopes'], cwd=docs)
|
||||
|
||||
# -- Spell checking -------------------------------------------------------
|
||||
|
||||
try:
|
||||
import sphinxcontrib.spelling
|
||||
except ImportError:
|
||||
pass
|
||||
else:
|
||||
extensions.append("sphinxcontrib.spelling")
|
||||
|
||||
spelling_word_list_filename = 'spelling_wordlist.txt'
|
||||
|
||||
@@ -1,27 +0,0 @@
|
||||
# Community communication channels
|
||||
|
||||
We use different channels of communication for different purposes. Whichever one you use will depend on what kind of communication you want to engage in.
|
||||
|
||||
## Discourse (recommended)
|
||||
|
||||
We use [Discourse](https://discourse.jupyter.org) for online discussions and support questions.
|
||||
You can ask questions here if you are a first-time contributor to the JupyterHub project.
|
||||
Everyone in the Jupyter community is welcome to bring ideas and questions there.
|
||||
|
||||
We recommend that you first use our Discourse as all past and current discussions on it are archived and searchable. Thus, all discussions remain useful and accessible to the whole community.
|
||||
|
||||
## Gitter
|
||||
|
||||
We use [our Gitter channel](https://gitter.im/jupyterhub/jupyterhub) for online, real-time text chat; a place for more ephemeral discussions. When you're not on Discourse, you can stop here to have other discussions on the fly.
|
||||
|
||||
## Github Issues
|
||||
|
||||
[Github issues](https://docs.github.com/en/issues/tracking-your-work-with-issues/about-issues) are used for most long-form project discussions, bug reports and feature requests.
|
||||
|
||||
- Issues related to a specific authenticator or spawner should be opened in the appropriate repository for the authenticator or spawner.
|
||||
- If you are using a specific JupyterHub distribution (such as [Zero to JupyterHub on Kubernetes](http://github.com/jupyterhub/zero-to-jupyterhub-k8s) or [The Littlest JupyterHub](http://github.com/jupyterhub/the-littlest-jupyterhub/)), you should open issues directly in their repository.
|
||||
- If you cannot find a repository to open your issue in, do not worry! Open the issue in the [main JupyterHub repository](https://github.com/jupyterhub/jupyterhub/) and our community will help you figure it out.
|
||||
|
||||
```{note}
|
||||
Our community is distributed across the world in various timezones, so please be patient if you do not get a response immediately!
|
||||
```
|
||||
30
docs/source/contributing/community.rst
Normal file
30
docs/source/contributing/community.rst
Normal file
@@ -0,0 +1,30 @@
|
||||
.. _contributing/community:
|
||||
|
||||
================================
|
||||
Community communication channels
|
||||
================================
|
||||
|
||||
We use `Discourse <https://discourse.jupyter.org>` for online discussion.
|
||||
Everyone in the Jupyter community is welcome to bring ideas and questions there.
|
||||
In addition, we use `Gitter <https://gitter.im>`_ for online, real-time text chat,
|
||||
a place for more ephemeral discussions.
|
||||
The primary Gitter channel for JupyterHub is `jupyterhub/jupyterhub <https://gitter.im/jupyterhub/jupyterhub>`_.
|
||||
Gitter isn't archived or searchable, so we recommend going to discourse first
|
||||
to make sure that discussions are most useful and accessible to the community.
|
||||
Remember that our community is distributed across the world in various
|
||||
timezones, so be patient if you do not get an answer immediately!
|
||||
|
||||
GitHub issues are used for most long-form project discussions, bug reports
|
||||
and feature requests. Issues related to a specific authenticator or
|
||||
spawner should be directed to the appropriate repository for the
|
||||
authenticator or spawner. If you are using a specific JupyterHub
|
||||
distribution (such as `Zero to JupyterHub on Kubernetes <http://github.com/jupyterhub/zero-to-jupyterhub-k8s>`_
|
||||
or `The Littlest JupyterHub <http://github.com/jupyterhub/the-littlest-jupyterhub/>`_),
|
||||
you should open issues directly in their repository. If you can not
|
||||
find a repository to open your issue in, do not worry! Create it in the `main
|
||||
JupyterHub repository <https://github.com/jupyterhub/jupyterhub/>`_ and our
|
||||
community will help you figure it out.
|
||||
|
||||
A `mailing list <https://groups.google.com/forum/#!forum/jupyter>`_ for all
|
||||
of Project Jupyter exists, along with one for `teaching with Jupyter
|
||||
<https://groups.google.com/forum/#!forum/jupyter-education>`_.
|
||||
@@ -5,7 +5,7 @@ Contributing Documentation
|
||||
==========================
|
||||
|
||||
Documentation is often more important than code. This page helps
|
||||
you get set up on how to contribute to JupyterHub's documentation.
|
||||
you get set up on how to contribute documentation to JupyterHub.
|
||||
|
||||
Building documentation locally
|
||||
==============================
|
||||
@@ -18,7 +18,7 @@ stored under the ``docs/source`` directory) and converts it into various
|
||||
formats for people to read. To make sure the documentation you write or
|
||||
change renders correctly, it is good practice to test it locally.
|
||||
|
||||
#. Make sure you have successfully completed :ref:`contributing/setup`.
|
||||
#. Make sure you have successfuly completed :ref:`contributing/setup`.
|
||||
|
||||
#. Install the packages required to build the docs.
|
||||
|
||||
@@ -27,7 +27,7 @@ change renders correctly, it is good practice to test it locally.
|
||||
python3 -m pip install -r docs/requirements.txt
|
||||
|
||||
#. Build the html version of the docs. This is the most commonly used
|
||||
output format, so verifying it renders correctly is usually good
|
||||
output format, so verifying it renders as you should is usually good
|
||||
enough.
|
||||
|
||||
.. code-block:: bash
|
||||
@@ -44,14 +44,8 @@ change renders correctly, it is good practice to test it locally.
|
||||
|
||||
.. tip::
|
||||
|
||||
**On Windows**, you can open a file from the terminal with ``start <path-to-file>``.
|
||||
|
||||
**On macOS**, you can do the same with ``open <path-to-file>``.
|
||||
|
||||
**On Linux**, you can do the same with ``xdg-open <path-to-file>``.
|
||||
|
||||
After opening index.html in your browser you can just refresh the page whenever
|
||||
you rebuild the docs via ``make html``
|
||||
On macOS, you can open a file from the terminal with ``open <path-to-file>``.
|
||||
On Linux, you can do the same with ``xdg-open <path-to-file>``.
|
||||
|
||||
|
||||
.. _contributing/docs/conventions:
|
||||
|
||||
@@ -4,7 +4,7 @@ This roadmap collects "next steps" for JupyterHub. It is about creating a
|
||||
shared understanding of the project's vision and direction amongst
|
||||
the community of users, contributors, and maintainers.
|
||||
The goal is to communicate priorities and upcoming release plans.
|
||||
It is not aimed at limiting contributions to what is listed here.
|
||||
It is not a aimed at limiting contributions to what is listed here.
|
||||
|
||||
## Using the roadmap
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@ Setting up a development install
|
||||
System requirements
|
||||
===================
|
||||
|
||||
JupyterHub can only run on macOS or Linux operating systems. If you are
|
||||
JupyterHub can only run on MacOS or Linux operating systems. If you are
|
||||
using Windows, we recommend using `VirtualBox <https://virtualbox.org>`_
|
||||
or a similar system to run `Ubuntu Linux <https://ubuntu.com>`_ for
|
||||
development.
|
||||
@@ -15,27 +15,25 @@ development.
|
||||
Install Python
|
||||
--------------
|
||||
|
||||
JupyterHub is written in the `Python <https://python.org>`_ programming language and
|
||||
requires you have at least version 3.6 installed locally. If you haven’t
|
||||
JupyterHub is written in the `Python <https://python.org>`_ programming language, and
|
||||
requires you have at least version 3.5 installed locally. If you haven’t
|
||||
installed Python before, the recommended way to install it is to use
|
||||
`Miniconda <https://conda.io/miniconda.html>`_. Remember to get the ‘Python 3’ version,
|
||||
`miniconda <https://conda.io/miniconda.html>`_. Remember to get the ‘Python 3’ version,
|
||||
and **not** the ‘Python 2’ version!
|
||||
|
||||
Install nodejs
|
||||
--------------
|
||||
|
||||
`NodeJS 12+ <https://nodejs.org/en/>`_ is required for building some JavaScript components.
|
||||
``configurable-http-proxy``, the default proxy implementation for JupyterHub, is written in Javascript.
|
||||
If you have not installed NodeJS before, we recommend installing it in the ``miniconda`` environment you set up for Python.
|
||||
You can do so with ``conda install nodejs``.
|
||||
|
||||
Many in the Jupyter community use [``nvm``](https://github.com/nvm-sh/nvm) to
|
||||
managing node dependencies.
|
||||
``configurable-http-proxy``, the default proxy implementation for
|
||||
JupyterHub, is written in Javascript to run on `NodeJS
|
||||
<https://nodejs.org/en/>`_. If you have not installed nodejs before, we
|
||||
recommend installing it in the ``miniconda`` environment you set up for
|
||||
Python. You can do so with ``conda install nodejs``.
|
||||
|
||||
Install git
|
||||
-----------
|
||||
|
||||
JupyterHub uses `Git <https://git-scm.com>`_ & `GitHub <https://github.com>`_
|
||||
JupyterHub uses `git <https://git-scm.com>`_ & `GitHub <https://github.com>`_
|
||||
for development & collaboration. You need to `install git
|
||||
<https://git-scm.com/book/en/v2/Getting-Started-Installing-Git>`_ to work on
|
||||
JupyterHub. We also recommend getting a free account on GitHub.com.
|
||||
@@ -43,11 +41,13 @@ JupyterHub. We also recommend getting a free account on GitHub.com.
|
||||
Setting up a development install
|
||||
================================
|
||||
|
||||
When developing JupyterHub, you would need to make changes and be able to instantly view the results of the changes. To achieve that, a developer install is required.
|
||||
When developing JupyterHub, you need to make changes to the code & see
|
||||
their effects quickly. You need to do a developer install to make that
|
||||
happen.
|
||||
|
||||
.. note:: This guide does not attempt to dictate *how* development
|
||||
environments should be isolated since that is a personal preference and can
|
||||
be achieved in many ways, for example, `tox`, `conda`, `docker`, etc. See this
|
||||
environements should be isolated since that is a personal preference and can
|
||||
be achieved in many ways, for example `tox`, `conda`, `docker`, etc. See this
|
||||
`forum thread <https://discourse.jupyter.org/t/thoughts-on-using-tox/3497>`_ for
|
||||
a more detailed discussion.
|
||||
|
||||
@@ -66,7 +66,7 @@ When developing JupyterHub, you would need to make changes and be able to instan
|
||||
|
||||
python -V
|
||||
|
||||
This should return a version number greater than or equal to 3.6.
|
||||
This should return a version number greater than or equal to 3.5.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
@@ -74,51 +74,53 @@ When developing JupyterHub, you would need to make changes and be able to instan
|
||||
|
||||
This should return a version number greater than or equal to 5.0.
|
||||
|
||||
3. Install ``configurable-http-proxy`` (required to run and test the default JupyterHub configuration) and ``yarn`` (required to build some components):
|
||||
3. Install ``configurable-http-proxy``. This is required to run
|
||||
JupyterHub.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
npm install -g configurable-http-proxy yarn
|
||||
npm install -g configurable-http-proxy
|
||||
|
||||
If you get an error that says ``Error: EACCES: permission denied``, you might need to prefix the command with ``sudo``.
|
||||
``sudo`` may be required to perform a system-wide install.
|
||||
If you do not have access to sudo, you may instead run the following commands:
|
||||
If you get an error that says ``Error: EACCES: permission denied``,
|
||||
you might need to prefix the command with ``sudo``. If you do not
|
||||
have access to sudo, you may instead run the following commands:
|
||||
|
||||
.. code:: bash
|
||||
|
||||
npm install configurable-http-proxy yarn
|
||||
npm install configurable-http-proxy
|
||||
export PATH=$PATH:$(pwd)/node_modules/.bin
|
||||
|
||||
The second line needs to be run every time you open a new terminal.
|
||||
|
||||
If you are using conda you can instead run:
|
||||
4. Install the python packages required for JupyterHub development.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
conda install configurable-http-proxy yarn
|
||||
python3 -m pip install -r dev-requirements.txt
|
||||
python3 -m pip install -r requirements.txt
|
||||
|
||||
4. Install an editable version of JupyterHub and its requirements for
|
||||
development and testing. This lets you edit JupyterHub code in a text editor
|
||||
& restart the JupyterHub process to see your code changes immediately.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
python3 -m pip install --editable ".[test]"
|
||||
|
||||
5. Set up a database.
|
||||
5. Setup a database.
|
||||
|
||||
The default database engine is ``sqlite`` so if you are just trying
|
||||
to get up and running quickly for local development that should be
|
||||
available via `Python <https://docs.python.org/3.5/library/sqlite3.html>`__.
|
||||
available via `python <https://docs.python.org/3.5/library/sqlite3.html>`__.
|
||||
See :doc:`/reference/database` for details on other supported databases.
|
||||
|
||||
6. You are now ready to start JupyterHub!
|
||||
6. Install the development version of JupyterHub. This lets you edit
|
||||
JupyterHub code in a text editor & restart the JupyterHub process to
|
||||
see your code changes immediately.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
python3 -m pip install --editable .
|
||||
|
||||
7. You are now ready to start JupyterHub!
|
||||
|
||||
.. code:: bash
|
||||
|
||||
jupyterhub
|
||||
|
||||
7. You can access JupyterHub from your browser at
|
||||
8. You can access JupyterHub from your browser at
|
||||
``http://localhost:8000`` now.
|
||||
|
||||
Happy developing!
|
||||
@@ -126,12 +128,12 @@ Happy developing!
|
||||
Using DummyAuthenticator & SimpleLocalProcessSpawner
|
||||
====================================================
|
||||
|
||||
To simplify testing of JupyterHub, it is helpful to use
|
||||
To simplify testing of JupyterHub, it’s helpful to use
|
||||
:class:`~jupyterhub.auth.DummyAuthenticator` instead of the default JupyterHub
|
||||
authenticator and SimpleLocalProcessSpawner instead of the default spawner.
|
||||
|
||||
There is a sample configuration file that does this in
|
||||
``testing/jupyterhub_config.py``. To launch JupyterHub with this
|
||||
``testing/jupyterhub_config.py``. To launch jupyterhub with this
|
||||
configuration:
|
||||
|
||||
.. code:: bash
|
||||
@@ -147,14 +149,14 @@ JupyterHub as.
|
||||
|
||||
DummyAuthenticator allows you to log in with any username & password,
|
||||
while SimpleLocalProcessSpawner allows you to start servers without having to
|
||||
create a Unix user for each JupyterHub user. Together, these make it
|
||||
create a unix user for each JupyterHub user. Together, these make it
|
||||
much easier to test JupyterHub.
|
||||
|
||||
Tip: If you are working on parts of JupyterHub that are common to all
|
||||
authenticators & spawners, we recommend using both DummyAuthenticator &
|
||||
SimpleLocalProcessSpawner. If you are working on just authenticator-related
|
||||
SimpleLocalProcessSpawner. If you are working on just authenticator related
|
||||
parts, use only SimpleLocalProcessSpawner. Similarly, if you are working on
|
||||
just spawner-related parts, use only DummyAuthenticator.
|
||||
just spawner related parts, use only DummyAuthenticator.
|
||||
|
||||
Troubleshooting
|
||||
===============
|
||||
@@ -184,4 +186,3 @@ development updates, with:
|
||||
|
||||
python3 setup.py js # fetch updated client-side js
|
||||
python3 setup.py css # recompile CSS from LESS sources
|
||||
python3 setup.py jsx # build React admin app
|
||||
|
||||
@@ -1,24 +1,25 @@
|
||||
.. _contributing/tests:
|
||||
|
||||
===================================
|
||||
Testing JupyterHub and linting code
|
||||
===================================
|
||||
==================
|
||||
Testing JupyterHub
|
||||
==================
|
||||
|
||||
Unit testing helps to validate that JupyterHub works the way we think it does,
|
||||
Unit test help validate that JupyterHub works the way we think it does,
|
||||
and continues to do so when changes occur. They also help communicate
|
||||
precisely what we expect our code to do.
|
||||
|
||||
JupyterHub uses `pytest <https://pytest.org>`_ for all the tests. You
|
||||
can find them under the `jupyterhub/tests <https://github.com/jupyterhub/jupyterhub/tree/main/jupyterhub/tests>`_ directory in the git repository.
|
||||
JupyterHub uses `pytest <https://pytest.org>`_ for all our tests. You
|
||||
can find them under ``jupyterhub/tests`` directory in the git repository.
|
||||
|
||||
Running the tests
|
||||
==================
|
||||
|
||||
#. Make sure you have completed :ref:`contributing/setup`.
|
||||
Once you are done, you would be able to run ``jupyterhub`` from the command line and access it from your web browser.
|
||||
This ensures that the dev environment is properly set up for tests to run.
|
||||
#. Make sure you have completed :ref:`contributing/setup`. You should be able
|
||||
to start ``jupyterhub`` from the commandline & access it from your
|
||||
web browser. This ensures that the dev environment is properly set
|
||||
up for tests to run.
|
||||
|
||||
#. You can run all tests in JupyterHub
|
||||
#. You can run all tests in JupyterHub
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
@@ -26,7 +27,7 @@ Running the tests
|
||||
|
||||
This should display progress as it runs all the tests, printing
|
||||
information about any test failures as they occur.
|
||||
|
||||
|
||||
If you wish to confirm test coverage the run tests with the `--cov` flag:
|
||||
|
||||
.. code-block:: bash
|
||||
@@ -53,51 +54,9 @@ Running the tests
|
||||
you would run:
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
|
||||
pytest -v jupyterhub/tests/test_api.py::test_shutdown
|
||||
|
||||
For more details, refer to the `pytest usage documentation <https://pytest.readthedocs.io/en/latest/usage.html>`_.
|
||||
|
||||
Test organisation
|
||||
=================
|
||||
|
||||
The tests live in ``jupyterhub/tests`` and are organized roughly into:
|
||||
|
||||
#. ``test_api.py`` tests the REST API
|
||||
#. ``test_pages.py`` tests loading the HTML pages
|
||||
|
||||
and other collections of tests for different components.
|
||||
When writing a new test, there should usually be a test of
|
||||
similar functionality already written and related tests should
|
||||
be added nearby.
|
||||
|
||||
The fixtures live in ``jupyterhub/tests/conftest.py``. There are
|
||||
fixtures that can be used for JupyterHub components, such as:
|
||||
|
||||
- ``app``: an instance of JupyterHub with mocked parts
|
||||
- ``auth_state_enabled``: enables persisting auth_state (like authentication tokens)
|
||||
- ``db``: a sqlite in-memory DB session
|
||||
- ``io_loop```: a Tornado event loop
|
||||
- ``event_loop``: a new asyncio event loop
|
||||
- ``user``: creates a new temporary user
|
||||
- ``admin_user``: creates a new temporary admin user
|
||||
- single user servers
|
||||
- ``cleanup_after``: allows cleanup of single user servers between tests
|
||||
- mocked service
|
||||
- ``MockServiceSpawner``: a spawner that mocks services for testing with a short poll interval
|
||||
- ``mockservice```: mocked service with no external service url
|
||||
- ``mockservice_url``: mocked service with a url to test external services
|
||||
|
||||
And fixtures to add functionality or spawning behavior:
|
||||
|
||||
- ``admin_access``: grants admin access
|
||||
- ``no_patience```: sets slow-spawning timeouts to zero
|
||||
- ``slow_spawn``: enables the SlowSpawner (a spawner that takes a few seconds to start)
|
||||
- ``never_spawn``: enables the NeverSpawner (a spawner that will never start)
|
||||
- ``bad_spawn``: enables the BadSpawner (a spawner that fails immediately)
|
||||
- ``slow_bad_spawn``: enables the SlowBadSpawner (a spawner that fails after a short delay)
|
||||
|
||||
Refer to the `pytest fixtures documentation <https://pytest.readthedocs.io/en/latest/fixture.html>`_ to learn how to use fixtures that exists already and to create new ones.
|
||||
|
||||
Troubleshooting Test Failures
|
||||
=============================
|
||||
@@ -105,34 +64,5 @@ Troubleshooting Test Failures
|
||||
All the tests are failing
|
||||
-------------------------
|
||||
|
||||
Make sure you have completed all the steps in :ref:`contributing/setup` successfully, and are able to access JupyterHub from your browser at http://localhost:8000 after starting ``jupyterhub`` in your command line.
|
||||
|
||||
|
||||
Code formatting and linting
|
||||
===========================
|
||||
|
||||
JupyterHub automatically enforces code formatting. This means that pull requests
|
||||
with changes breaking this formatting will receive a commit from pre-commit.ci
|
||||
automatically.
|
||||
|
||||
To automatically format code locally, you can install pre-commit and register a
|
||||
*git hook* to automatically check with pre-commit before you make a commit if
|
||||
the formatting is okay.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
pip install pre-commit
|
||||
pre-commit install --install-hooks
|
||||
|
||||
To run pre-commit manually you would do:
|
||||
|
||||
.. code:: bash
|
||||
|
||||
# check for changes to code not yet committed
|
||||
pre-commit run
|
||||
|
||||
# check for changes also in already committed code
|
||||
pre-commit run --all-files
|
||||
|
||||
You may also install `black integration <https://github.com/psf/black#editor-integration>`_
|
||||
into your text editor to format code automatically.
|
||||
Make sure you have completed all the steps in :ref:`contributing/setup` successfully, and
|
||||
can launch ``jupyterhub`` from the terminal.
|
||||
|
||||
@@ -120,4 +120,3 @@ contribution on JupyterHub:
|
||||
- yuvipanda
|
||||
- zoltan-fedor
|
||||
- zonca
|
||||
- Neeraj Natu
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
Event logging and telemetry
|
||||
===========================
|
||||
Eventlogging and Telemetry
|
||||
==========================
|
||||
|
||||
JupyterHub can be configured to record structured events from a running server using Jupyter's `Telemetry System`_. The types of events that JupyterHub emits are defined by `JSON schemas`_ listed at the bottom of this page_.
|
||||
|
||||
@@ -15,7 +15,7 @@ Event logging is handled by its ``Eventlog`` object. This leverages Python's sta
|
||||
|
||||
To begin recording events, you'll need to set two configurations:
|
||||
|
||||
1. ``handlers``: tells the EventLog *where* to route your events. This trait is a list of Python logging handlers that route events to the event log file.
|
||||
1. ``handlers``: tells the EventLog *where* to route your events. This trait is a list of Python logging handlers that route events to
|
||||
2. ``allows_schemas``: tells the EventLog *which* events should be recorded. No events are emitted by default; all recorded events must be listed here.
|
||||
|
||||
Here's a basic example:
|
||||
|
||||
@@ -97,7 +97,7 @@ easy to do with RStudio too.
|
||||
|
||||
### University of Illinois
|
||||
|
||||
- https://datascience.business.illinois.edu (currently down; checked 10/26/22)
|
||||
- https://datascience.business.illinois.edu (currently down; checked 04/26/19)
|
||||
|
||||
### IllustrisTNG Simulation Project
|
||||
|
||||
@@ -126,7 +126,7 @@ easy to do with RStudio too.
|
||||
|
||||
### Penn State University
|
||||
|
||||
- [Press release](https://news.psu.edu/story/523093/2018/05/24/new-open-source-web-apps-available-students-and-faculty): "New open-source web apps available for students and faculty"
|
||||
- [Press release](https://news.psu.edu/story/523093/2018/05/24/new-open-source-web-apps-available-students-and-faculty): "New open-source web apps available for students and faculty" (but Hub is currently down; checked 04/26/19)
|
||||
|
||||
### University of Rochester CIRC
|
||||
|
||||
@@ -156,13 +156,13 @@ easy to do with RStudio too.
|
||||
### Elucidata
|
||||
|
||||
- What's new in Jupyter Notebooks @[Elucidata](https://elucidata.io/):
|
||||
- [Using Jupyter Notebooks with Jupyterhub on GCP, managed by GKE](https://medium.com/elucidata/why-you-should-be-using-a-jupyter-notebook-8385a4ccd93d)
|
||||
- Using Jupyter Notebooks with Jupyterhub on GCP, managed by GKE - https://medium.com/elucidata/why-you-should-be-using-a-jupyter-notebook-8385a4ccd93d
|
||||
|
||||
## Service Providers
|
||||
|
||||
### AWS
|
||||
|
||||
- [Run Jupyter Notebook and JupyterHub on Amazon EMR](https://aws.amazon.com/blogs/big-data/running-jupyter-notebook-and-jupyterhub-on-amazon-emr/)
|
||||
- [running-jupyter-notebook-and-jupyterhub-on-amazon-emr](https://aws.amazon.com/blogs/big-data/running-jupyter-notebook-and-jupyterhub-on-amazon-emr/)
|
||||
|
||||
### Google Cloud Platform
|
||||
|
||||
@@ -175,12 +175,12 @@ easy to do with RStudio too.
|
||||
|
||||
### Microsoft Azure
|
||||
|
||||
- [Azure Data Science Virtual Machine release notes](https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-data-science-linux-dsvm-intro)
|
||||
- https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-data-science-linux-dsvm-intro
|
||||
|
||||
### Rackspace Carina
|
||||
|
||||
- https://getcarina.com/blog/learning-how-to-whale/
|
||||
- http://carolynvanslyck.com/talk/carina/jupyterhub/#/ (but carolynvanslyck is currently down; checked 10/26/22)
|
||||
- http://carolynvanslyck.com/talk/carina/jupyterhub/#/
|
||||
|
||||
### Hadoop
|
||||
|
||||
@@ -189,14 +189,13 @@ easy to do with RStudio too.
|
||||
## Miscellaneous
|
||||
|
||||
- https://medium.com/@ybarraud/setting-up-jupyterhub-with-sudospawner-and-anaconda-844628c0dbee#.rm3yt87e1
|
||||
- [Mailing list UT deployment](https://groups.google.com/forum/#!topic/jupyter/nkPSEeMr8c0)
|
||||
- [JupyterHub setup on Centos](https://gist.github.com/johnrc/604971f7d41ebf12370bf5729bf3e0a4)
|
||||
- [Deploy JupyterHub to Docker Swarm](https://jupyterhub.surge.sh/#/welcome)
|
||||
- https://groups.google.com/forum/#!topic/jupyter/nkPSEeMr8c0 Mailing list UT deployment
|
||||
- JupyterHub setup on Centos https://gist.github.com/johnrc/604971f7d41ebf12370bf5729bf3e0a4
|
||||
- Deploy JupyterHub to Docker Swarm https://jupyterhub.surge.sh/#/welcome
|
||||
- http://www.laketide.com/building-your-lab-part-3/
|
||||
- http://estrellita.hatenablog.com/entry/2015/07/31/083202
|
||||
- http://www.walkingrandomly.com/?p=5734
|
||||
- https://wrdrd.com/docs/consulting/education-technology
|
||||
- https://bitbucket.org/jackhale/fenics-jupyter
|
||||
- [LinuxCluster blog](https://linuxcluster.wordpress.com/category/application/jupyterhub/)
|
||||
- [Network Technology](https://arnesund.com/tag/jupyterhub/)
|
||||
- [Spark Cluster on OpenStack with Multi-User Jupyter Notebook](https://arnesund.com/2015/09/21/spark-cluster-on-openstack-with-multi-user-jupyter-notebook/)
|
||||
- [Network Technology](https://arnesund.com/tag/jupyterhub/) [Spark Cluster on OpenStack with Multi-User Jupyter Notebook](https://arnesund.com/2015/09/21/spark-cluster-on-openstack-with-multi-user-jupyter-notebook/)
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
# Authentication and User Basics
|
||||
|
||||
The default Authenticator uses [PAM][] (Pluggable Authentication Module) to authenticate system users with
|
||||
The default Authenticator uses [PAM][] to authenticate system users with
|
||||
their username and password. With the default Authenticator, any user
|
||||
with an account and password on the system will be allowed to login.
|
||||
|
||||
## Create a set of allowed users (`allowed_users`)
|
||||
## Create a set of allowed users
|
||||
|
||||
You can restrict which users are allowed to login with a set,
|
||||
`Authenticator.allowed_users`:
|
||||
@@ -25,7 +25,7 @@ If this configuration value is not set, then **all authenticated users will be a
|
||||
```{note}
|
||||
As of JupyterHub 2.0, the full permissions of `admin_users`
|
||||
should not be required.
|
||||
Instead, you can assign [roles](define-role-target) to users or groups
|
||||
Instead, you can assign [roles][] to users or groups
|
||||
with only the scopes they require.
|
||||
```
|
||||
|
||||
@@ -42,10 +42,10 @@ c.Authenticator.admin_users = {'mal', 'zoe'}
|
||||
Users in the admin set are automatically added to the user `allowed_users` set,
|
||||
if they are not already present.
|
||||
|
||||
Each Authenticator may have different ways of determining whether a user is an
|
||||
administrator. By default, JupyterHub uses the PAMAuthenticator which provides the
|
||||
Each authenticator may have different ways of determining whether a user is an
|
||||
administrator. By default JupyterHub uses the PAMAuthenticator which provides the
|
||||
`admin_groups` option and can set administrator status based on a user
|
||||
group. For example, we can let any user in the `wheel` group be an admin:
|
||||
group. For example we can let any user in the `wheel` group be admin:
|
||||
|
||||
```python
|
||||
c.PAMAuthenticator.admin_groups = {'wheel'}
|
||||
@@ -57,12 +57,12 @@ Since the default `JupyterHub.admin_access` setting is `False`, the admins
|
||||
do not have permission to log in to the single user notebook servers
|
||||
owned by _other users_. If `JupyterHub.admin_access` is set to `True`,
|
||||
then admins have permission to log in _as other users_ on their
|
||||
respective machines for debugging. **As a courtesy, you should make
|
||||
respective machines, for debugging. **As a courtesy, you should make
|
||||
sure your users know if admin_access is enabled.**
|
||||
|
||||
## Add or remove users from the Hub
|
||||
|
||||
Users can be added to and removed from the Hub via the admin
|
||||
Users can be added to and removed from the Hub via either the admin
|
||||
panel or the REST API. When a user is **added**, the user will be
|
||||
automatically added to the `allowed_users` set and database. Restarting the Hub
|
||||
will not require manually updating the `allowed_users` set in your config file,
|
||||
@@ -76,12 +76,12 @@ fresh.
|
||||
|
||||
## Use LocalAuthenticator to create system users
|
||||
|
||||
The `LocalAuthenticator` is a special kind of Authenticator that has
|
||||
The `LocalAuthenticator` is a special kind of authenticator that has
|
||||
the ability to manage users on the local system. When you try to add a
|
||||
new user to the Hub, a `LocalAuthenticator` will check if the user
|
||||
already exists. If you set the configuration value, `create_system_users`,
|
||||
to `True` in the configuration file, the `LocalAuthenticator` has
|
||||
the ability to add users to the system. The setting in the config
|
||||
the privileges to add users to the system. The setting in the config
|
||||
file is:
|
||||
|
||||
```python
|
||||
@@ -91,7 +91,7 @@ c.LocalAuthenticator.create_system_users = True
|
||||
Adding a user to the Hub that doesn't already exist on the system will
|
||||
result in the Hub creating that user via the system `adduser` command
|
||||
line tool. This option is typically used on hosted deployments of
|
||||
JupyterHub to avoid the need to manually create all your users before
|
||||
JupyterHub, to avoid the need to manually create all your users before
|
||||
launching the service. This approach is not recommended when running
|
||||
JupyterHub in situations where JupyterHub users map directly onto the
|
||||
system's UNIX users.
|
||||
@@ -101,25 +101,25 @@ system's UNIX users.
|
||||
JupyterHub's [OAuthenticator][] currently supports the following
|
||||
popular services:
|
||||
|
||||
- [Auth0](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.auth0.html#module-oauthenticator.auth0)
|
||||
- [Azure AD](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.azuread.html#module-oauthenticator.azuread)
|
||||
- [Bitbucket](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.bitbucket.html#module-oauthenticator.bitbucket)
|
||||
- [CILogon](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.cilogon.html#module-oauthenticator.cilogon)
|
||||
- [GitHub](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.github.html#module-oauthenticator.github)
|
||||
- [GitLab](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.gitlab.html#module-oauthenticator.gitlab)
|
||||
- [Globus](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.globus.html#module-oauthenticator.globus)
|
||||
- [Google](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.google.html#module-oauthenticator.google)
|
||||
- [MediaWiki](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.mediawiki.html#module-oauthenticator.mediawiki)
|
||||
- [Okpy](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.okpy.html#module-oauthenticator.okpy)
|
||||
- [OpenShift](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.openshift.html#module-oauthenticator.openshift)
|
||||
- Auth0
|
||||
- Azure AD
|
||||
- Bitbucket
|
||||
- CILogon
|
||||
- GitHub
|
||||
- GitLab
|
||||
- Globus
|
||||
- Google
|
||||
- MediaWiki
|
||||
- Okpy
|
||||
- OpenShift
|
||||
|
||||
A [generic implementation](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.generic.html#module-oauthenticator.generic), which you can use for OAuth authentication
|
||||
A generic implementation, which you can use for OAuth authentication
|
||||
with any provider, is also available.
|
||||
|
||||
## Use DummyAuthenticator for testing
|
||||
|
||||
The `DummyAuthenticator` is a simple Authenticator that
|
||||
allows for any username or password unless a global password has been set. If
|
||||
The `DummyAuthenticator` is a simple authenticator that
|
||||
allows for any username/password unless a global password has been set. If
|
||||
set, it will allow for any username as long as the correct password is provided.
|
||||
To set a global password, add this to the config file:
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Configuration Basics
|
||||
|
||||
This section contains basic information about configuring settings for a JupyterHub
|
||||
The section contains basic information about configuring settings for a JupyterHub
|
||||
deployment. The [Technical Reference](../reference/index)
|
||||
documentation provides additional details.
|
||||
|
||||
@@ -49,7 +49,7 @@ that Jupyter uses.
|
||||
|
||||
## Configure using command line options
|
||||
|
||||
To display all command line options that are available for configuration run the following command:
|
||||
To display all command line options that are available for configuration:
|
||||
|
||||
```bash
|
||||
jupyterhub --help-all
|
||||
@@ -77,11 +77,11 @@ jupyterhub --Spawner.notebook_dir='~/assignments'
|
||||
## Configure for various deployment environments
|
||||
|
||||
The default authentication and process spawning mechanisms can be replaced, and
|
||||
specific [authenticators](authenticators-users-basics) and
|
||||
[spawners](spawners-basics) can be set in the configuration file.
|
||||
specific [authenticators](./authenticators-users-basics) and
|
||||
[spawners](./spawners-basics) can be set in the configuration file.
|
||||
This enables JupyterHub to be used with a variety of authentication methods or
|
||||
process control and deployment environments. [Some examples](../reference/config-examples),
|
||||
meant as illustrations, are:
|
||||
meant as illustration, are:
|
||||
|
||||
- Using GitHub OAuth instead of PAM with [OAuthenticator](https://github.com/jupyterhub/oauthenticator)
|
||||
- Spawning single-user servers with Docker, using the [DockerSpawner](https://github.com/jupyterhub/dockerspawner)
|
||||
|
||||
@@ -16,8 +16,7 @@ to come to _your server_ and look at the exact same file.
|
||||
In most circumstances, this is forbidden by permissions because the person you share with does not have access to your server.
|
||||
What actually happens when someone visits this URL will depend on whether your server is running and other factors.
|
||||
|
||||
**But what is our actual goal?**
|
||||
|
||||
But what is our actual goal?
|
||||
A typical situation is that you have some shared or common filesystem,
|
||||
such that the same path corresponds to the same document
|
||||
(either the exact same document or another copy of it).
|
||||
|
||||
@@ -8,16 +8,10 @@ broken down by their roles within organizations.
|
||||
### Is it appropriate for adoption within a larger institutional context?
|
||||
|
||||
Yes! JupyterHub has been used at-scale for large pools of users, as well
|
||||
as complex and high-performance computing.
|
||||
For example,
|
||||
|
||||
- UC Berkeley uses
|
||||
JupyterHub for its Data Science Education Program courses (serving over
|
||||
3,000 students).
|
||||
- The Pangeo project uses JupyterHub to provide access
|
||||
to scalable cloud computing with Dask.
|
||||
|
||||
JupyterHub is stable and customizable
|
||||
as complex and high-performance computing. For example, UC Berkeley uses
|
||||
JupyterHub for its Data Science Education Program courses (serving over
|
||||
3,000 students). The Pangeo project uses JupyterHub to provide access
|
||||
to scalable cloud computing with Dask. JupyterHub is stable and customizable
|
||||
to the use-cases of large organizations.
|
||||
|
||||
### I keep hearing about Jupyter Notebook, JupyterLab, and now JupyterHub. What’s the difference?
|
||||
@@ -32,7 +26,7 @@ Here is a quick breakdown of these three tools:
|
||||
has several extensions that are tailored for using Jupyter Notebooks, as well as extensions
|
||||
for other parts of the data science stack.
|
||||
- **JupyterHub** is an application that manages interactive computing sessions for **multiple users**.
|
||||
It also connects users with infrastructure they wish to access. It can provide
|
||||
It also connects them with infrastructure those users wish to access. It can provide
|
||||
remote access to Jupyter Notebooks and JupyterLab for many people.
|
||||
|
||||
## For management
|
||||
@@ -41,7 +35,7 @@ Here is a quick breakdown of these three tools:
|
||||
|
||||
JupyterHub provides a shared platform for data science and collaboration.
|
||||
It allows users to utilize familiar data science workflows (such as the scientific Python stack,
|
||||
the R tidyverse, and Jupyter Notebooks) on institutional infrastructure. It also gives administrators
|
||||
the R tidyverse, and Jupyter Notebooks) on institutional infrastructure. It also allows administrators
|
||||
some control over access to resources, security, environments, and authentication.
|
||||
|
||||
### Is JupyterHub mature? Why should we trust it?
|
||||
@@ -84,7 +78,7 @@ gives administrators more control over their setup and hardware.
|
||||
|
||||
Because JupyterHub is an open-source, community-driven tool, it can be extended and
|
||||
modified to fit an institution's needs. It plays nicely with the open source data science
|
||||
stack, and can serve a variety of computing environments, user interfaces, and
|
||||
stack, and can serve a variety of computing enviroments, user interfaces, and
|
||||
computational hardware. It can also be deployed anywhere - on enterprise cloud infrastructure, on
|
||||
High-Performance-Computing machines, on local hardware, or even on a single laptop, which
|
||||
is not possible with most other tools for shared interactive computing.
|
||||
@@ -105,12 +99,12 @@ that we currently suggest are:
|
||||
guide that runs on Kubernetes. Better for larger or dynamic user groups (50-10,000) or more complex
|
||||
compute/data needs.
|
||||
- [The Littlest JupyterHub](https://tljh.jupyter.org) is a lightweight JupyterHub that runs on a single
|
||||
machine (in the cloud or under your desk). Better for smaller user groups (4-80) or more
|
||||
single machine (in the cloud or under your desk). Better for smaller user groups (4-80) or more
|
||||
lightweight computational resources.
|
||||
|
||||
### Does JupyterHub run well in the cloud?
|
||||
|
||||
**Yes** - most deployments of JupyterHub are run via cloud infrastructure and on a variety of cloud providers.
|
||||
Yes - most deployments of JupyterHub are run via cloud infrastructure and on a variety of cloud providers.
|
||||
Depending on the distribution of JupyterHub that you'd like to use, you can also connect your JupyterHub
|
||||
deployment with a number of other cloud-native services so that users have access to other resources from
|
||||
their interactive computing sessions.
|
||||
@@ -124,8 +118,7 @@ as more resources are needed - allowing you to utilize the benefits of a flexibl
|
||||
|
||||
### Is JupyterHub secure?
|
||||
|
||||
The short answer: yes.
|
||||
JupyterHub as a standalone application has been battle-tested at an institutional
|
||||
The short answer: yes. JupyterHub as a standalone application has been battle-tested at an institutional
|
||||
level for several years, and makes a number of "default" security decisions that are reasonable for most
|
||||
users.
|
||||
|
||||
@@ -141,11 +134,11 @@ in these cases, and the security of your JupyterHub deployment will often depend
|
||||
|
||||
If you are worried about security, don't hesitate to reach out to the JupyterHub community in the
|
||||
[Jupyter Community Forum](https://discourse.jupyter.org/c/jupyterhub). This community of practice has many
|
||||
individuals with experience running secure JupyterHub deployments and will be very glad to help you out.
|
||||
individuals with experience running secure JupyterHub deployments.
|
||||
|
||||
### Does JupyterHub provide computing or data infrastructure?
|
||||
|
||||
**No** - JupyterHub manages user sessions and can _control_ computing infrastructure, but it does not provide these
|
||||
No - JupyterHub manages user sessions and can _control_ computing infrastructure, but it does not provide these
|
||||
things itself. You are expected to run JupyterHub on your own infrastructure (local or in the cloud). Moreover,
|
||||
JupyterHub has no internal concept of "data", but is designed to be able to communicate with data repositories
|
||||
(again, either locally or remotely) for use within interactive computing sessions.
|
||||
@@ -198,7 +191,7 @@ complex computing infrastructures from the interactive sessions of a JupyterHub.
|
||||
This is highly configurable by the administrator. If you wish for your users to have simple
|
||||
data analytics environments for prototyping and light data exploring, you can restrict their
|
||||
memory and CPU based on the resources that you have available. If you'd like your JupyterHub
|
||||
to serve as a gateway to high-performance computing or data resources, you may increase the
|
||||
to serve as a gateway to high-performance compute or data resources, you may increase the
|
||||
resources available on user machines, or connect them with computing infrastructures elsewhere.
|
||||
|
||||
### Can I customize the look and feel of a JupyterHub?
|
||||
|
||||
@@ -41,9 +41,9 @@ port.
|
||||
|
||||
## Set the Proxy's REST API communication URL (optional)
|
||||
|
||||
By default, the proxy's REST API listens on port 8081 of `localhost` only.
|
||||
The Hub service talks to the proxy via a REST API on a secondary port.
|
||||
The REST API URL (hostname and port) can be configured separately and override the default settings.
|
||||
By default, this REST API listens on port 8001 of `localhost` only.
|
||||
The Hub service talks to the proxy via a REST API on a secondary port. The
|
||||
API URL can be configured separately to override the default settings.
|
||||
|
||||
### Set api_url
|
||||
|
||||
|
||||
@@ -5,17 +5,17 @@ Security settings
|
||||
|
||||
You should not run JupyterHub without SSL encryption on a public network.
|
||||
|
||||
Security is the most important aspect of configuring Jupyter.
|
||||
Three (3) configuration settings are the main aspects of security configuration:
|
||||
Security is the most important aspect of configuring Jupyter. Three
|
||||
configuration settings are the main aspects of security configuration:
|
||||
|
||||
1. :ref:`SSL encryption <ssl-encryption>` (to enable HTTPS)
|
||||
2. :ref:`Cookie secret <cookie-secret>` (a key for encrypting browser cookies)
|
||||
3. Proxy :ref:`authentication token <authentication-token>` (used for the Hub and
|
||||
other services to authenticate to the Proxy)
|
||||
|
||||
The Hub hashes all secrets (e.g. auth tokens) before storing them in its
|
||||
The Hub hashes all secrets (e.g., auth tokens) before storing them in its
|
||||
database. A loss of control over read-access to the database should have
|
||||
minimal impact on your deployment. If your database has been compromised, it
|
||||
minimal impact on your deployment; if your database has been compromised, it
|
||||
is still a good idea to revoke existing tokens.
|
||||
|
||||
.. _ssl-encryption:
|
||||
@@ -31,7 +31,7 @@ Using an SSL certificate
|
||||
|
||||
This will require you to obtain an official, trusted SSL certificate or create a
|
||||
self-signed certificate. Once you have obtained and installed a key and
|
||||
certificate, you need to specify their locations in the ``jupyterhub_config.py``
|
||||
certificate you need to specify their locations in the ``jupyterhub_config.py``
|
||||
configuration file as follows:
|
||||
|
||||
.. code-block:: python
|
||||
@@ -72,13 +72,13 @@ would be the needed configuration:
|
||||
If SSL termination happens outside of the Hub
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
In certain cases, for example, if the hub is running behind a reverse proxy, and
|
||||
In certain cases, for example if the hub is running behind a reverse proxy, and
|
||||
`SSL termination is being provided by NGINX <https://www.nginx.com/resources/admin-guide/nginx-ssl-termination/>`_,
|
||||
it is reasonable to run the hub without SSL.
|
||||
|
||||
To achieve this, remove ``c.JupyterHub.ssl_key`` and ``c.JupyterHub.ssl_cert``
|
||||
from your configuration (setting them to ``None`` or an empty string does not
|
||||
have the same effect, and will result in an error).
|
||||
To achieve this, simply omit the configuration settings
|
||||
``c.JupyterHub.ssl_key`` and ``c.JupyterHub.ssl_cert``
|
||||
(setting them to ``None`` does not have the same effect, and is an error).
|
||||
|
||||
.. _authentication-token:
|
||||
|
||||
@@ -92,7 +92,7 @@ use an auth token.
|
||||
|
||||
The value of this token should be a random string (for example, generated by
|
||||
``openssl rand -hex 32``). You can store it in the configuration file or an
|
||||
environment variable.
|
||||
environment variable
|
||||
|
||||
Generating and storing token in the configuration file
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
@@ -118,8 +118,8 @@ This environment variable needs to be visible to the Hub and Proxy.
|
||||
Default if token is not set
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
If you do not set the Proxy authentication token, the Hub will generate a random
|
||||
key itself. This means that any time you restart the Hub, you **must also
|
||||
If you don't set the Proxy authentication token, the Hub will generate a random
|
||||
key itself, which means that any time you restart the Hub you **must also
|
||||
restart the Proxy**. If the proxy is a subprocess of the Hub, this should happen
|
||||
automatically (this is the default configuration).
|
||||
|
||||
@@ -128,7 +128,7 @@ automatically (this is the default configuration).
|
||||
Cookie secret
|
||||
-------------
|
||||
|
||||
The cookie secret is an encryption key, used to encrypt the browser cookies,
|
||||
The cookie secret is an encryption key, used to encrypt the browser cookies
|
||||
which are used for authentication. Three common methods are described for
|
||||
generating and configuring the cookie secret.
|
||||
|
||||
@@ -136,8 +136,8 @@ Generating and storing as a cookie secret file
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
The cookie secret should be 32 random bytes, encoded as hex, and is typically
|
||||
stored in a ``jupyterhub_cookie_secret`` file. Below, is an example command to generate the
|
||||
``jupyterhub_cookie_secret`` file:
|
||||
stored in a ``jupyterhub_cookie_secret`` file. An example command to generate the
|
||||
``jupyterhub_cookie_secret`` file is:
|
||||
|
||||
.. code-block:: bash
|
||||
|
||||
@@ -155,7 +155,7 @@ The location of the ``jupyterhub_cookie_secret`` file can be specified in the
|
||||
|
||||
If the cookie secret file doesn't exist when the Hub starts, a new cookie
|
||||
secret is generated and stored in the file. The file must not be readable by
|
||||
``group`` or ``other``, otherwise the server won't start. The recommended permissions
|
||||
``group`` or ``other`` or the server won't start. The recommended permissions
|
||||
for the cookie secret file are ``600`` (owner-only rw).
|
||||
|
||||
Generating and storing as an environment variable
|
||||
@@ -176,13 +176,19 @@ the Hub starts.
|
||||
Generating and storing as a binary string
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
You can also set the cookie secret, as a binary string,
|
||||
in the configuration file (``jupyterhub_config.py``) itself:
|
||||
You can also set the cookie secret in the configuration file
|
||||
itself, ``jupyterhub_config.py``, as a binary string:
|
||||
|
||||
.. code-block:: python
|
||||
|
||||
c.JupyterHub.cookie_secret = bytes.fromhex('64 CHAR HEX STRING')
|
||||
|
||||
|
||||
.. important::
|
||||
|
||||
If the cookie secret value changes for the Hub, all single-user notebook
|
||||
servers must also be restarted.
|
||||
|
||||
.. _cookies:
|
||||
|
||||
Cookies used by JupyterHub authentication
|
||||
@@ -198,7 +204,7 @@ jupyterhub-hub-login
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This is the login token used when visiting Hub-served pages that are
|
||||
protected by authentication, such as the main home, the spawn form, etc.
|
||||
protected by authentication such as the main home, the spawn form, etc.
|
||||
If this cookie is set, then the user is logged in.
|
||||
|
||||
Resetting the Hub cookie secret effectively revokes this cookie.
|
||||
@@ -209,7 +215,7 @@ jupyterhub-user-<username>
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This is the cookie used for authenticating with a single-user server.
|
||||
It is set by the single-user server, after OAuth with the Hub.
|
||||
It is set by the single-user server after OAuth with the Hub.
|
||||
|
||||
Effectively the same as ``jupyterhub-hub-login``, but for the
|
||||
single-user server instead of the Hub. It contains an OAuth access token,
|
||||
@@ -218,13 +224,14 @@ which is checked with the Hub to authenticate the browser.
|
||||
Each OAuth access token is associated with a session id (see ``jupyterhub-session-id`` section
|
||||
below).
|
||||
|
||||
To avoid hitting the Hub on every request, the authentication response is cached.
|
||||
The cache key is comprised of both the token and session id, to avoid a stale cache.
|
||||
To avoid hitting the Hub on every request, the authentication response
|
||||
is cached. And to avoid a stale cache the cache key is comprised of both
|
||||
the token and session id.
|
||||
|
||||
Resetting the Hub cookie secret effectively revokes this cookie.
|
||||
|
||||
This cookie is restricted to the path ``/user/<username>``,
|
||||
to ensure that only the user’s server receives it.
|
||||
This cookie is restricted to the path ``/user/<username>``, so that
|
||||
only the user’s server receives it.
|
||||
|
||||
jupyterhub-session-id
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
@@ -232,9 +239,9 @@ jupyterhub-session-id
|
||||
This is a random string, meaningless in itself, and the only cookie
|
||||
shared by the Hub and single-user servers.
|
||||
|
||||
Its sole purpose is to coordinate the logout of the multiple OAuth cookies.
|
||||
Its sole purpose is to coordinate logout of the multiple OAuth cookies.
|
||||
|
||||
This cookie is set to ``/`` so all endpoints can receive it, clear it, etc.
|
||||
This cookie is set to ``/`` so all endpoints can receive it, or clear it, etc.
|
||||
|
||||
jupyterhub-user-<username>-oauth-state
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
@@ -244,7 +251,7 @@ It is only set while OAuth between the single-user server and the Hub
|
||||
is processing.
|
||||
|
||||
If you use your browser development tools, you should see this cookie
|
||||
for a very brief moment before you are logged in,
|
||||
for a very brief moment before your are logged in,
|
||||
with an expiration date shorter than ``jupyterhub-hub-login`` or
|
||||
``jupyterhub-user-<username>``.
|
||||
|
||||
|
||||
@@ -24,7 +24,7 @@ Hub via the REST API.
|
||||
|
||||
## API Token basics
|
||||
|
||||
### Step 1: Generate an API token
|
||||
### Create an API token
|
||||
|
||||
To run such an external service, an API token must be created and
|
||||
provided to the service.
|
||||
@@ -43,12 +43,12 @@ generating an API token is available from the JupyterHub user interface:
|
||||
|
||||

|
||||
|
||||
### Step 2: Pass environment variable with token to the Hub
|
||||
### Pass environment variable with token to the Hub
|
||||
|
||||
In the case of `cull_idle_servers`, it is passed as the environment
|
||||
variable called `JUPYTERHUB_API_TOKEN`.
|
||||
|
||||
### Step 3: Use API tokens for services and tasks that require external access
|
||||
### Use API tokens for services and tasks that require external access
|
||||
|
||||
While API tokens are often associated with a specific user, API tokens
|
||||
can be used by services that require external access for activities
|
||||
@@ -62,12 +62,12 @@ c.JupyterHub.services = [
|
||||
]
|
||||
```
|
||||
|
||||
### Step 4: Restart JupyterHub
|
||||
### Restart JupyterHub
|
||||
|
||||
Upon restarting JupyterHub, you should see a message like below in the
|
||||
logs:
|
||||
|
||||
```none
|
||||
```
|
||||
Adding API token for <username>
|
||||
```
|
||||
|
||||
@@ -78,15 +78,16 @@ single-user servers, and only cookies can be used for authentication.
|
||||
0.8 supports using JupyterHub API tokens to authenticate to single-user
|
||||
servers.
|
||||
|
||||
## How to configure the idle culler to run as a Hub-Managed Service
|
||||
## Configure the idle culler to run as a Hub-Managed Service
|
||||
|
||||
### Step 1: Install the idle culler:
|
||||
Install the idle culler:
|
||||
|
||||
```
|
||||
pip install jupyterhub-idle-culler
|
||||
```
|
||||
|
||||
### Step 2: In `jupyterhub_config.py`, add the following dictionary for the `idle-culler` Service to the `c.JupyterHub.services` list:
|
||||
In `jupyterhub_config.py`, add the following dictionary for the
|
||||
`idle-culler` Service to the `c.JupyterHub.services` list:
|
||||
|
||||
```python
|
||||
c.JupyterHub.services = [
|
||||
@@ -126,7 +127,7 @@ It now needs the scopes:
|
||||
- `admin:servers` to start/stop servers
|
||||
```
|
||||
|
||||
## How to run `cull-idle` manually as a standalone script
|
||||
## Run `cull-idle` manually as a standalone script
|
||||
|
||||
Now you can run your script by providing it
|
||||
the API token and it will authenticate through the REST API to
|
||||
|
||||
@@ -1,12 +1,12 @@
|
||||
# Spawners and single-user notebook servers
|
||||
|
||||
A Spawner starts each single-user notebook server. Since the single-user server is an instance of `jupyter notebook`, an entire separate
|
||||
multi-process application, many aspects of that server can be configured and there are a lot
|
||||
Since the single-user server is an instance of `jupyter notebook`, an entire separate
|
||||
multi-process application, there are many aspects of that server that can be configured, and a lot
|
||||
of ways to express that configuration.
|
||||
|
||||
At the JupyterHub level, you can set some values on the Spawner. The simplest of these is
|
||||
`Spawner.notebook_dir`, which lets you set the root directory for a user's server. This root
|
||||
notebook directory is the highest-level directory users will be able to access in the notebook
|
||||
notebook directory is the highest level directory users will be able to access in the notebook
|
||||
dashboard. In this example, the root notebook directory is set to `~/notebooks`, where `~` is
|
||||
expanded to the user's home directory.
|
||||
|
||||
@@ -20,7 +20,7 @@ You can also specify extra command line arguments to the notebook server with:
|
||||
c.Spawner.args = ['--debug', '--profile=PHYS131']
|
||||
```
|
||||
|
||||
This could be used to set the user's default page for the single-user server:
|
||||
This could be used to set the users default page for the single user server:
|
||||
|
||||
```python
|
||||
c.Spawner.args = ['--NotebookApp.default_url=/notebooks/Welcome.ipynb']
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 1.1 MiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 1017 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 607 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 1.8 MiB |
@@ -9,7 +9,6 @@ well as other information relevant to running your own JupyterHub over time.
|
||||
:maxdepth: 2
|
||||
|
||||
troubleshooting
|
||||
admin/capacity-planning
|
||||
admin/upgrading
|
||||
admin/log-messages
|
||||
changelog
|
||||
|
||||
@@ -1,32 +1,32 @@
|
||||
==========
|
||||
JupyterHub
|
||||
==========
|
||||
`JupyterHub`_ is the best way to serve `Jupyter notebook`_ for multiple users.
|
||||
Because JupyterHub manages a separate Jupyter environment for each user,
|
||||
it can be used in a class of students, a corporate data science group, or a scientific
|
||||
|
||||
`JupyterHub`_ is the best way to serve `Jupyter notebook`_ for multiple users.
|
||||
It can be used in a class of students, a corporate data science group or scientific
|
||||
research group. It is a multi-user **Hub** that spawns, manages, and proxies multiple
|
||||
instances of the single-user `Jupyter notebook`_ server.
|
||||
|
||||
JupyterHub offers distributions for different use cases. As of now, you can find two main cases:
|
||||
To make life easier, JupyterHub has distributions. Be sure to
|
||||
take a look at them before continuing with the configuration of the broad
|
||||
original system of `JupyterHub`_. Today, you can find two main cases:
|
||||
|
||||
1. `The Littlest JupyterHub <https://github.com/jupyterhub/the-littlest-jupyterhub>`__ distribution is suitable if you need a small number of users (1-100) and a single server with a simple environment.
|
||||
2. `Zero to JupyterHub with Kubernetes <https://github.com/jupyterhub/zero-to-jupyterhub-k8s>`__ allows you to deploy dynamic servers on the cloud if you need even more users.
|
||||
1. If you need a simple case for a small amount of users (0-100) and single server
|
||||
take a look at
|
||||
`The Littlest JupyterHub <https://github.com/jupyterhub/the-littlest-jupyterhub>`__ distribution.
|
||||
2. If you need to allow for even more users, a dynamic amount of servers can be used on a cloud,
|
||||
take a look at the `Zero to JupyterHub with Kubernetes <https://github.com/jupyterhub/zero-to-jupyterhub-k8s>`__ .
|
||||
|
||||
|
||||
JupyterHub can be used in a collaborative environment by both both small (0-100 users) and
|
||||
large teams (more than 100 users) such as a class of students, corporate data science group
|
||||
or scientific research group. It has distributions which are developed to serve the needs of
|
||||
each of these teams respectively.
|
||||
|
||||
JupyterHub is made up of four subsystems:
|
||||
Four subsystems make up JupyterHub:
|
||||
|
||||
* a **Hub** (tornado process) that is the heart of JupyterHub
|
||||
* a **configurable http proxy** (node-http-proxy) that receives the requests from the client's browser
|
||||
* multiple **single-user Jupyter notebook servers** (Python/IPython/tornado) that are monitored by Spawners
|
||||
* an **authentication class** that manages how users can access the system
|
||||
|
||||
Additionally, optional configurations can be added through a `config.py` file and manage users
|
||||
kernels on an admin panel. A simplification of the whole system is displayed in the figure below:
|
||||
|
||||
Besides these central pieces, you can add optional configurations through a `config.py` file and manage users kernels on an admin panel. A simplification of the whole system can be seen in the figure below:
|
||||
|
||||
.. image:: images/jhub-fluxogram.jpeg
|
||||
:alt: JupyterHub subsystems
|
||||
@@ -56,22 +56,17 @@ Contents
|
||||
Distributions
|
||||
-------------
|
||||
|
||||
A JupyterHub **distribution** is tailored
|
||||
towards a particular set of use cases. These are generally easier
|
||||
to set up than setting up JupyterHub from scratch, assuming they fit your use case.
|
||||
A JupyterHub **distribution** is tailored towards a particular set of
|
||||
use cases. These are generally easier to set up than setting up
|
||||
JupyterHub from scratch, assuming they fit your use case.
|
||||
|
||||
Today, you can find two main use cases:
|
||||
The two popular ones are:
|
||||
|
||||
1. If you need a simple case for a small amount of users (0-100) and single server
|
||||
take a look at
|
||||
`The Littlest JupyterHub <https://github.com/jupyterhub/the-littlest-jupyterhub>`__ distribution.
|
||||
2. If you need to allow for a larger number of machines and users,
|
||||
a dynamic amount of servers can be used on a cloud,
|
||||
take a look at the `Zero to JupyterHub with Kubernetes <https://github.com/jupyterhub/zero-to-jupyterhub-k8s>`__ distribution.
|
||||
This distribution runs JupyterHub on top of `Kubernetes <https://k8s.io>`_.
|
||||
|
||||
*It is important to evaluate these distributions before you can continue with the
|
||||
configuration of JupyterHub*.
|
||||
* `Zero to JupyterHub on Kubernetes <http://z2jh.jupyter.org>`_, for
|
||||
running JupyterHub on top of `Kubernetes <https://k8s.io>`_. This
|
||||
can scale to large number of machines & users.
|
||||
* `The Littlest JupyterHub <http://tljh.jupyter.org>`_, for an easy
|
||||
to set up & run JupyterHub supporting 1-100 users on a single machine.
|
||||
|
||||
Installation Guide
|
||||
------------------
|
||||
@@ -124,12 +119,13 @@ RBAC Reference
|
||||
Contributing
|
||||
------------
|
||||
|
||||
We welcome you to contribute to JupyterHub in ways that are most exciting
|
||||
& useful to you. We value documentation, testing, bug reporting & code equally
|
||||
We want you to contribute to JupyterHub in ways that are most exciting
|
||||
& useful to you. We value documentation, testing, bug reporting & code equally,
|
||||
and are glad to have your contributions in whatever form you wish :)
|
||||
|
||||
Our `Code of Conduct <https://github.com/jupyter/governance/blob/HEAD/conduct/code_of_conduct.md>`_ and `reporting guidelines <https://github.com/jupyter/governance/blob/HEAD/conduct/reporting_online.md>`_
|
||||
help keep our community welcoming to as many people as possible.
|
||||
Our `Code of Conduct <https://github.com/jupyter/governance/blob/HEAD/conduct/code_of_conduct.md>`_
|
||||
(`reporting guidelines <https://github.com/jupyter/governance/blob/HEAD/conduct/reporting_online.md>`_)
|
||||
helps keep our community welcoming to as many people as possible.
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
@@ -153,9 +149,9 @@ Indices and tables
|
||||
|
||||
Questions? Suggestions?
|
||||
=======================
|
||||
All questions and suggestions are welcome. Please feel free to use our `Jupyter Discourse Forum <https://discourse.jupyter.org/>`_ to contact our team.
|
||||
|
||||
Looking forward to hearing from you!
|
||||
- `Jupyter mailing list <https://groups.google.com/forum/#!forum/jupyter>`_
|
||||
- `Jupyter website <https://jupyter.org>`_
|
||||
|
||||
.. _JupyterHub: https://github.com/jupyterhub/jupyterhub
|
||||
.. _Jupyter notebook: https://jupyter-notebook.readthedocs.io/en/latest/
|
||||
|
||||
@@ -1,69 +1,49 @@
|
||||
Install JupyterHub with Docker
|
||||
==============================
|
||||
Using Docker
|
||||
============
|
||||
|
||||
.. important::
|
||||
|
||||
The JupyterHub `docker image <https://hub.docker.com/r/jupyterhub/jupyterhub/>`_ is the fastest way to set up Jupyterhub in your local development environment.
|
||||
We highly recommend following the `Zero to JupyterHub`_ tutorial for
|
||||
installing JupyterHub.
|
||||
|
||||
Alternate installation using Docker
|
||||
-----------------------------------
|
||||
|
||||
A ready to go `docker image <https://hub.docker.com/r/jupyterhub/jupyterhub/>`_
|
||||
gives a straightforward deployment of JupyterHub.
|
||||
|
||||
.. note::
|
||||
|
||||
This ``jupyterhub/jupyterhub`` docker image is only an image for running
|
||||
the Hub service itself. It does not provide the other Jupyter components,
|
||||
such as Notebook installation, which are needed by the single-user servers.
|
||||
To run the single-user servers, which may be on the same system as the Hub or
|
||||
not, `JupyterLab <https://jupyterlab.readthedocs.io/>`_ or Jupyter Notebook must be installed.
|
||||
not, Jupyter Notebook version 4 or greater must be installed.
|
||||
|
||||
Starting JupyterHub with docker
|
||||
-------------------------------
|
||||
|
||||
.. important::
|
||||
We strongly recommend that you follow the `Zero to JupyterHub`_ tutorial to
|
||||
install JupyterHub.
|
||||
|
||||
|
||||
Prerequisites
|
||||
-------------
|
||||
You should have `Docker`_ installed on a Linux/Unix based system.
|
||||
The JupyterHub docker image can be started with the following command::
|
||||
|
||||
|
||||
Run the Docker Image
|
||||
--------------------
|
||||
|
||||
To pull the latest JupyterHub image and start the `jupyterhub` container, run this command in your terminal.
|
||||
::
|
||||
|
||||
docker run -d -p 8000:8000 --name jupyterhub jupyterhub/jupyterhub jupyterhub
|
||||
|
||||
This command will create a container named ``jupyterhub`` that you can
|
||||
**stop and resume** with ``docker stop/start``.
|
||||
|
||||
This command exposes the Jupyter container on port:8000. Navigate to `http://localhost:8000` in a web browser to access the JupyterHub console.
|
||||
|
||||
You can stop and resume the container by running `docker stop` and `docker start` respectively.
|
||||
::
|
||||
|
||||
# find the container id
|
||||
docker ps
|
||||
|
||||
# stop the running container
|
||||
docker stop <container-id>
|
||||
|
||||
# resume the paused container
|
||||
docker start <container-id>
|
||||
|
||||
The Hub service will be listening on all interfaces at port 8000, which makes
|
||||
this a good choice for **testing JupyterHub on your desktop or laptop**.
|
||||
|
||||
If you want to run docker on a computer that has a public IP then you should
|
||||
(as in MUST) **secure it with ssl** by adding ssl options to your docker
|
||||
configuration or using an ssl enabled proxy.
|
||||
configuration or using a ssl enabled proxy.
|
||||
|
||||
`Mounting volumes <https://docs.docker.com/engine/admin/volumes/volumes/>`_
|
||||
enables you to persist and store the data generated by the docker container, even when you stop the container.
|
||||
The persistent data can be stored on the host system, outside the container.
|
||||
`Mounting volumes <https://docs.docker.com/engine/admin/volumes/volumes/>`_
|
||||
will allow you to store data outside the docker image (host system) so it will
|
||||
be persistent, even when you start a new image.
|
||||
|
||||
|
||||
Create System Users
|
||||
-------------------
|
||||
|
||||
Spawn a root shell in your docker container by running this command in the terminal.::
|
||||
|
||||
docker exec -it jupyterhub bash
|
||||
|
||||
The created accounts will be used for authentication in JupyterHub's default
|
||||
The command ``docker exec -it jupyterhub bash`` will spawn a root shell in your
|
||||
docker container. You can use the root shell to **create system users in the container**.
|
||||
These accounts will be used for authentication in JupyterHub's default
|
||||
configuration.
|
||||
|
||||
.. _Zero to JupyterHub: https://zero-to-jupyterhub.readthedocs.io/en/latest/
|
||||
.. _Docker: https://www.docker.com/
|
||||
|
||||
@@ -4,7 +4,7 @@
|
||||
|
||||
Before installing JupyterHub, you will need:
|
||||
|
||||
- a Linux/Unix-based system
|
||||
- a Linux/Unix based system
|
||||
- [Python](https://www.python.org/downloads/) 3.6 or greater. An understanding
|
||||
of using [`pip`](https://pip.pypa.io) or
|
||||
[`conda`](https://conda.io/docs/get-started.html) for
|
||||
@@ -80,7 +80,7 @@ To start the Hub server, run the command:
|
||||
jupyterhub
|
||||
```
|
||||
|
||||
Visit `http://localhost:8000` in your browser, and sign in with your Unix
|
||||
Visit `http://localhost:8000` in your browser, and sign in with your unix
|
||||
credentials.
|
||||
|
||||
To **allow multiple users to sign in** to the Hub server, you must start
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
(RBAC)=
|
||||
|
||||
# JupyterHub RBAC
|
||||
|
||||
Role Based Access Control (RBAC) in JupyterHub serves to provide fine grained control of access to Jupyterhub's API resources.
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
(roles)=
|
||||
|
||||
# Roles
|
||||
|
||||
JupyterHub provides four (4) roles that are available by default:
|
||||
JupyterHub provides four roles that are available by default:
|
||||
|
||||
```{admonition} **Default roles**
|
||||
- `user` role provides a {ref}`default user scope <default-user-scope-target>` `self` that grants access to the user's own resources.
|
||||
@@ -11,11 +13,11 @@ JupyterHub provides four (4) roles that are available by default:
|
||||
**These roles cannot be deleted.**
|
||||
```
|
||||
|
||||
We call these 'default' roles because they are available by default and have a default collection of scopes.
|
||||
However, you can define the scopes associated with each role (excluding the admin role) to suit your needs,
|
||||
These default roles have a default collection of scopes,
|
||||
but you can define the scopes associated with each role (excluding admin) to suit your needs,
|
||||
as seen [below](overriding-default-roles).
|
||||
|
||||
The `user`, `admin`, and `token` roles, by default, all preserve the permissions prior to Role-based Access Control (RBAC).
|
||||
The `user`, `admin`, and `token` roles by default all preserve the permissions prior to RBAC.
|
||||
Only the `server` role is changed from pre-2.0, to reduce its permissions to activity-only
|
||||
instead of the default of a full access token.
|
||||
|
||||
@@ -25,20 +27,21 @@ Roles can be assigned to the following entities:
|
||||
- Users
|
||||
- Services
|
||||
- Groups
|
||||
- Tokens
|
||||
|
||||
An entity can have zero, one, or multiple roles, and there are no restrictions on which roles can be assigned to which entity. Roles can be added to or removed from entities at any time.
|
||||
|
||||
**Users** \
|
||||
When a new user gets created, they are assigned their default role, `user`. Additionally, if the user is created with admin privileges (via `c.Authenticator.admin_users` in `jupyterhub_config.py` or `admin: true` via API), they will be also granted `admin` role. If existing user's admin status changes via API or `jupyterhub_config.py`, their default role will be updated accordingly (after next startup for the latter).
|
||||
When a new user gets created, they are assigned their default role `user`. Additionaly, if the user is created with admin privileges (via `c.Authenticator.admin_users` in `jupyterhub_config.py` or `admin: true` via API), they will be also granted `admin` role. If existing user's admin status changes via API or `jupyterhub_config.py`, their default role will be updated accordingly (after next startup for the latter).
|
||||
|
||||
**Services** \
|
||||
Services do not have a default role. Services without roles have no access to the guarded API end-points. So, most services will require assignment of a role in order to function.
|
||||
Services do not have a default role. Services without roles have no access to the guarded API end-points, so most services will require assignment of a role in order to function.
|
||||
|
||||
**Groups** \
|
||||
A group does not require any role, and has no roles by default. If a user is a member of a group, they automatically inherit any of the group's permissions (see {ref}`resolving-roles-scopes-target` for more details). This is useful for assigning a set of common permissions to several users.
|
||||
|
||||
**Tokens** \
|
||||
A token’s permissions are evaluated based on their owning entity. Since a token is always issued for a user or service, it can never have more permissions than its owner. If no specific scopes are requested for a new token, the token is assigned the scopes of the `token` role.
|
||||
A token’s permissions are evaluated based on their owning entity. Since a token is always issued for a user or service, it can never have more permissions than its owner. If no specific role is requested for a new token, the token is assigned the `token` role.
|
||||
|
||||
(define-role-target)=
|
||||
|
||||
@@ -111,7 +114,7 @@ In case the role with a certain name already exists in the database, its definit
|
||||
|
||||
(overriding-default-roles)=
|
||||
|
||||
### Overriding Default Roles
|
||||
### Overriding default roles
|
||||
|
||||
Role definitions can include those of the "default" roles listed above (admin excluded),
|
||||
if the default scopes associated with those roles do not suit your deployment.
|
||||
@@ -152,7 +155,7 @@ c.JupyterHub.load_roles = [
|
||||
|
||||
(removing-roles-target)=
|
||||
|
||||
## Removing Roles
|
||||
## Removing roles
|
||||
|
||||
Only the entities present in the role definition in the `jupyterhub_config.py` remain the role bearers. If a user, service or group is removed from the role definition, they will lose the role on the next startup.
|
||||
|
||||
|
||||
@@ -72,31 +72,13 @@ Requested resources are filtered based on the filter of the corresponding scope.
|
||||
|
||||
In case a user resource is being accessed, any scopes with _group_ filters will be expanded to filters for each _user_ in those groups.
|
||||
|
||||
(self-referencing-filters)=
|
||||
|
||||
### Self-referencing filters
|
||||
|
||||
There are some 'shortcut' filters,
|
||||
which can be applied to all scopes,
|
||||
that filter based on the entities associated with the request.
|
||||
### `!user` filter
|
||||
|
||||
The `!user` filter is a special horizontal filter that strictly refers to the **"owner only"** scopes, where _owner_ is a user entity. The filter resolves internally into `!user=<ownerusername>` ensuring that only the owner's resources may be accessed through the associated scopes.
|
||||
|
||||
For example, the `server` role assigned by default to server tokens contains `access:servers!user` and `users:activity!user` scopes. This allows the token to access and post activity of only the servers owned by the token owner.
|
||||
|
||||
:::{versionadded} 3.0
|
||||
`!service` and `!server` filters.
|
||||
:::
|
||||
|
||||
In addition to `!user`, _tokens_ may have filters `!service`
|
||||
or `!server`, which expand similarly to `!service=servicename`
|
||||
and `!server=servername`.
|
||||
This only applies to tokens issued via the OAuth flow.
|
||||
In these cases, the name is the _issuing_ entity (a service or single-user server),
|
||||
so that access can be restricted to the issuing service,
|
||||
e.g. `access:servers!server` would grant access only to the server that requested the token.
|
||||
|
||||
These filters can be applied to any scope.
|
||||
The filter can be applied to any scope.
|
||||
|
||||
(vertical-filtering-target)=
|
||||
|
||||
@@ -132,170 +114,11 @@ There are four exceptions to the general {ref}`scope conventions <scope-conventi
|
||||
|
||||
```
|
||||
|
||||
:::{versionadded} 3.0
|
||||
The `admin-ui` scope is added to explicitly grant access to the admin page,
|
||||
rather than combining `admin:users` and `admin:servers` permissions.
|
||||
This means a deployment can enable the admin page with only a subset of functionality enabled.
|
||||
|
||||
Note that this means actions to take _via_ the admin UI
|
||||
and access _to_ the admin UI are separated.
|
||||
For example, it generally doesn't make sense to grant
|
||||
`admin-ui` without at least `list:users` for at least some subset of users.
|
||||
|
||||
For example:
|
||||
|
||||
```python
|
||||
c.JupyterHub.load_roles = [
|
||||
{
|
||||
"name": "instructor-data8",
|
||||
"scopes": [
|
||||
# access to the admin page
|
||||
"admin-ui",
|
||||
# list users in the class group
|
||||
"list:users!group=students-data8",
|
||||
# start/stop servers for users in the class
|
||||
"admin:servers!group=students-data8",
|
||||
# access servers for users in the class
|
||||
"access:servers!group=students-data8",
|
||||
],
|
||||
"group": ["instructors-data8"],
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
will grant instructors in the data8 course permission to:
|
||||
|
||||
1. view the admin UI
|
||||
2. see students in the class (but not all users)
|
||||
3. start/stop/access servers for users in the class
|
||||
4. but _not_ permission to administer the users themselves (e.g. change their permissions, etc.)
|
||||
:::
|
||||
|
||||
```{Caution}
|
||||
Note that only the {ref}`horizontal filtering <horizontal-filtering-target>` can be added to scopes to customize them. \
|
||||
Metascopes `self` and `all`, `<resource>`, `<resource>:<subresource>`, `read:<resource>`, `admin:<resource>`, and `access:<resource>` scopes are predefined and cannot be changed otherwise.
|
||||
```
|
||||
|
||||
(custom-scopes)=
|
||||
|
||||
### Custom scopes
|
||||
|
||||
:::{versionadded} 3.0
|
||||
:::
|
||||
|
||||
JupyterHub 3.0 introduces support for custom scopes.
|
||||
Services that use JupyterHub for authentication and want to implement their own granular access may define additional _custom_ scopes and assign them to users with JupyterHub roles.
|
||||
|
||||
% Note: keep in sync with pattern/description in jupyterhub/scopes.py
|
||||
|
||||
Custom scope names must start with `custom:`
|
||||
and contain only lowercase ascii letters, numbers, hyphen, underscore, colon, and asterisk (`-_:*`).
|
||||
The part after `custom:` must start with a letter or number.
|
||||
Scopes may not end with a hyphen or colon.
|
||||
|
||||
The only strict requirement is that a custom scope definition must have a `description`.
|
||||
It _may_ also have `subscopes` if you are defining multiple scopes that have a natural hierarchy,
|
||||
|
||||
For example:
|
||||
|
||||
```python
|
||||
c.JupyterHub.custom_scopes = {
|
||||
"custom:myservice:read": {
|
||||
"description": "read-only access to myservice",
|
||||
},
|
||||
"custom:myservice:write": {
|
||||
"description": "write access to myservice",
|
||||
# write permission implies read permission
|
||||
"subscopes": [
|
||||
"custom:myservice:read",
|
||||
],
|
||||
},
|
||||
}
|
||||
|
||||
c.JupyterHub.load_roles = [
|
||||
# graders have read-only access to the service
|
||||
{
|
||||
"name": "service-user",
|
||||
"groups": ["graders"],
|
||||
"scopes": [
|
||||
"custom:myservice:read",
|
||||
"access:service!service=myservice",
|
||||
],
|
||||
},
|
||||
# instructors have read and write access to the service
|
||||
{
|
||||
"name": "service-admin",
|
||||
"groups": ["instructors"],
|
||||
"scopes": [
|
||||
"custom:myservice:write",
|
||||
"access:service!service=myservice",
|
||||
],
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
In the above configuration, two scopes are defined:
|
||||
|
||||
- `custom:myservice:read` grants read-only access to the service, and
|
||||
- `custom:myservice:write` grants write access to the service
|
||||
- write access _implies_ read access via the `subscope`
|
||||
|
||||
These custom scopes are assigned to two groups via `roles`:
|
||||
|
||||
- users in the group `graders` are granted read access to the service
|
||||
- users in the group `instructors` are
|
||||
- both are granted _access_ to the service via `access:service!service=myservice`
|
||||
|
||||
When the service completes OAuth, it will retrieve the user model from `/hub/api/user`.
|
||||
This model includes a `scopes` field which is a list of authorized scope for the request,
|
||||
which can be used.
|
||||
|
||||
```python
|
||||
def require_scope(scope):
|
||||
"""decorator to require a scope to perform an action"""
|
||||
def wrapper(func):
|
||||
@functools.wraps(func)
|
||||
def wrapped_func(request):
|
||||
user = fetch_hub_api_user(request.token)
|
||||
if scope not in user["scopes"]:
|
||||
raise HTTP403(f"Requires scope {scope}")
|
||||
else:
|
||||
return func()
|
||||
return wrapper
|
||||
|
||||
@require_scope("custom:myservice:read")
|
||||
async def read_something(request):
|
||||
...
|
||||
|
||||
@require_scope("custom:myservice:write")
|
||||
async def write_something(request):
|
||||
...
|
||||
```
|
||||
|
||||
If you use {class}`~.HubOAuthenticated`, this check is performed automatically
|
||||
against the `.hub_scopes` attribute of each Handler
|
||||
(the default is populated from `$JUPYTERHUB_OAUTH_ACCESS_SCOPES` and usually `access:services!service=myservice`).
|
||||
|
||||
:::{versionchanged} 3.0
|
||||
The JUPYTERHUB_OAUTH_SCOPES environment variable is deprecated and renamed to JUPYTERHUB_OAUTH_ACCESS_SCOPES,
|
||||
to avoid ambiguity with JUPYTERHUB_OAUTH_CLIENT_ALLOWED_SCOPES
|
||||
:::
|
||||
|
||||
```python
|
||||
from tornado import web
|
||||
from jupyterhub.services.auth import HubOAuthenticated
|
||||
|
||||
class MyHandler(HubOAuthenticated, BaseHandler):
|
||||
hub_scopes = ["custom:myservice:read"]
|
||||
|
||||
@web.authenticated
|
||||
def get(self):
|
||||
...
|
||||
```
|
||||
|
||||
Existing scope filters (`!user=`, etc.) may be applied to custom scopes.
|
||||
Custom scope _filters_ are NOT supported.
|
||||
|
||||
### Scopes and APIs
|
||||
|
||||
The scopes are also listed in the [](../reference/rest-api.rst) documentation. Each API endpoint has a list of scopes which can be used to access the API; if no scopes are listed, the API is not authenticated and can be accessed without any permissions (i.e., no scopes).
|
||||
|
||||
@@ -1,67 +1,48 @@
|
||||
# Technical Implementation
|
||||
|
||||
[Roles](roles) are stored in the database, where they are associated with users, services, and groups. Roles can be added or modified as explained in the {ref}`define-role-target` section. Users, services, groups, and tokens can gain, change, and lose roles. This is currently achieved via `jupyterhub_config.py` (see {ref}`define-role-target`) and will be made available via API in the future. The latter will allow for changing a user's role, and thereby its permissions, without the need to restart JupyterHub.
|
||||
Roles are stored in the database, where they are associated with users, services, etc., and can be added or modified as explained in {ref}`define-role-target` section. Users, services, groups, and tokens can gain, change, and lose roles. This is currently achieved via `jupyterhub_config.py` (see {ref}`define-role-target`) and will be made available via API in future. The latter will allow for changing a token's role, and thereby its permissions, without the need to issue a new token.
|
||||
|
||||
Roles and scopes utilities can be found in `roles.py` and `scopes.py` modules. Scope variables take on five different formats that are reflected throughout the utilities via specific nomenclature:
|
||||
Roles and scopes utilities can be found in `roles.py` and `scopes.py` modules. Scope variables take on five different formats which is reflected throughout the utilities via specific nomenclature:
|
||||
|
||||
```{admonition} **Scope variable nomenclature**
|
||||
:class: tip
|
||||
- _scopes_ \
|
||||
List of scopes that may contain abbreviations (used in role definitions). E.g., `["users:activity!user", "self"]`.
|
||||
List of scopes with abbreviations (used in role definitions). E.g., `["users:activity!user"]`.
|
||||
- _expanded scopes_ \
|
||||
Set of fully expanded scopes without abbreviations (i.e., resolved metascopes, filters, and subscopes). E.g., `{"users:activity!user=charlie", "read:users:activity!user=charlie"}`.
|
||||
Set of expanded scopes without abbreviations (i.e., resolved metascopes, filters and subscopes). E.g., `{"users:activity!user=charlie", "read:users:activity!user=charlie"}`.
|
||||
- _parsed scopes_ \
|
||||
Dictionary representation of expanded scopes. E.g., `{"users:activity": {"user": ["charlie"]}, "read:users:activity": {"users": ["charlie"]}}`.
|
||||
Dictionary JSON like format of expanded scopes. E.g., `{"users:activity": {"user": ["charlie"]}, "read:users:activity": {"users": ["charlie"]}}`.
|
||||
- _intersection_ \
|
||||
Set of expanded scopes as intersection of 2 expanded scope sets.
|
||||
- _identify scopes_ \
|
||||
Set of expanded scopes needed for identity (whoami) endpoints.
|
||||
Set of expanded scopes needed for identify (whoami) endpoints.
|
||||
```
|
||||
|
||||
(resolving-roles-scopes-target)=
|
||||
|
||||
## Resolving roles and scopes
|
||||
|
||||
**Resolving roles** involves determining which roles a user, service, or group has, extracting the list of scopes from each role and combining them into a single set of scopes.
|
||||
**Resolving roles** refers to determining which roles a user, service, token, or group has, extracting the list of scopes from each role and combining them into a single set of scopes.
|
||||
|
||||
**Resolving scopes** involves expanding scopes into all their possible subscopes (_expanded scopes_), parsing them into the format used for access evaluation (_parsed scopes_) and, if applicable, comparing two sets of scopes (_intersection_). All procedures take into account the scope hierarchy, {ref}`vertical <vertical-filtering-target>` and {ref}`horizontal filtering <horizontal-filtering-target>`, limiting or elevated permissions (`read:<resource>` or `admin:<resource>`, respectively), and metascopes.
|
||||
**Resolving scopes** involves expanding scopes into all their possible subscopes (_expanded scopes_), parsing them into format used for access evaluation (_parsed scopes_) and, if applicable, comparing two sets of scopes (_intersection_). All procedures take into account the scope hierarchy, {ref}`vertical <vertical-filtering-target>` and {ref}`horizontal filtering <horizontal-filtering-target>`, limiting or elevated permissions (`read:<resource>` or `admin:<resource>`, respectively), and metascopes.
|
||||
|
||||
Roles and scopes are resolved on several occasions, for example when requesting an API token with specific scopes or when making an API request. The following sections provide more details.
|
||||
Roles and scopes are resolved on several occasions, for example when requesting an API token with specific roles or making an API request. The following sections provide more details.
|
||||
|
||||
(requesting-api-token-target)=
|
||||
|
||||
### Requesting API token with specific scopes
|
||||
### Requesting API token with specific roles
|
||||
|
||||
:::{versionchanged} 3.0
|
||||
API tokens have _scopes_ instead of roles,
|
||||
so that their permissions cannot be updated.
|
||||
API tokens grant access to JupyterHub's APIs. The RBAC framework allows for requesting tokens with specific existing roles. To date, it is only possible to add roles to a token through the _POST /users/:name/tokens_ API where the roles can be specified in the token parameters body (see [](../reference/rest-api.rst)).
|
||||
|
||||
You may still request roles for a token,
|
||||
but those roles will be evaluated to the corresponding _scopes_ immediately.
|
||||
RBAC adds several steps into the token issue flow.
|
||||
|
||||
Prior to 3.0, tokens stored _roles_,
|
||||
which meant their scopes were resolved on each request.
|
||||
:::
|
||||
If no roles are requested, the token is issued with the default `token` role (providing the requester is allowed to create the token).
|
||||
|
||||
API tokens grant access to JupyterHub's APIs. The [RBAC framework](./index.md) allows for requesting tokens with specific permissions.
|
||||
If the token is requested with any roles, the permissions of requesting entity are checked against the requested permissions to ensure the token would not grant its owner additional privileges.
|
||||
|
||||
RBAC is involved in several stages of the OAuth token flow.
|
||||
If, due to modifications of roles or entities, at API request time a token has any scopes that its owner does not, those scopes are removed. The API request is resolved without additional errors using the scopes _intersection_, but the Hub logs a warning (see {ref}`Figure 2 <api-request-chart>`).
|
||||
|
||||
When requesting a token via the tokens API (`/users/:name/tokens`), or the token page (`/hub/token`),
|
||||
if no scopes are requested, the token is issued with the permissions stored on the default `token` role
|
||||
(provided the requester is allowed to create the token).
|
||||
|
||||
OAuth tokens are also requested via OAuth flow
|
||||
|
||||
If the token is requested with any scopes, the permissions of requesting entity are checked against the requested permissions to ensure the token would not grant its owner additional privileges.
|
||||
|
||||
If a token has any scopes that its owner does not possess
|
||||
at the time of making the API request, those scopes are removed.
|
||||
The API request is resolved without additional errors using the scope _intersection_;
|
||||
the Hub logs a warning in this case (see {ref}`Figure 2 <api-request-chart>`).
|
||||
|
||||
Resolving a token's scope (yellow box in {ref}`Figure 1 <token-request-chart>`) corresponds to resolving all the roles of the token's owner (including the roles associated with their groups) and the token's own scopes into a set of scopes. The two sets are compared (Resolve the scopes box in orange in {ref}`Figure 1 <token-request-chart>`), taking into account the scope hierarchy.
|
||||
If the token's scopes are a subset of the token owner's scopes, the token is issued with the requested scopes; if not, JupyterHub will raise an error.
|
||||
Resolving a token's roles (yellow box in {ref}`Figure 1 <token-request-chart>`) corresponds to resolving all the token's owner roles (including the roles associated with their groups) and the token's requested roles into a set of scopes. The two sets are compared (Resolve the scopes box in orange in {ref}`Figure 1 <token-request-chart>`), taking into account the scope hierarchy but, solely for role assignment, omitting any {ref}`horizontal filter <horizontal-filtering-target>` comparison. If the token's scopes are a subset of the token owner's scopes, the token is issued with the requested roles; if not, JupyterHub will raise an error.
|
||||
|
||||
{ref}`Figure 1 <token-request-chart>` below illustrates the steps involved. The orange rectangles highlight where in the process the roles and scopes are resolved.
|
||||
|
||||
@@ -74,10 +55,10 @@ Figure 1. Resolving roles and scopes during API token request
|
||||
|
||||
### Making an API request
|
||||
|
||||
With the RBAC framework, each authenticated JupyterHub API request is guarded by a scope decorator that specifies which scopes are required in order to gain the access to the API.
|
||||
With the RBAC framework each authenticated JupyterHub API request is guarded by a scope decorator that specifies which scopes are required to gain the access to the API.
|
||||
|
||||
When an API request is made, the requesting API token's scopes are again intersected with its owner's (yellow box in {ref}`Figure 2 <api-request-chart>`) to ensure that the token does not grant more permissions than its owner has at the request time (e.g., due to changing/losing roles).
|
||||
If the owner's roles do not include some scopes of the token, only the _intersection_ of the token's and owner's scopes will be used. For example, using a token with scope `users` whose owner's role scope is `read:users:name` will result in only the `read:users:name` scope being passed on. In the case of no _intersection_, an empty set of scopes will be used.
|
||||
When an API request is performed, the requesting API token's roles are again resolved (yellow box in {ref}`Figure 2 <api-request-chart>`) to ensure the token does not grant more permissions than its owner has at the request time (e.g., due to changing/losing roles).
|
||||
If the owner's roles do not include some scopes of the token's scopes, only the _intersection_ of the token's and owner's scopes will be used. For example, using a token with scope `users` whose owner's role scope is `read:users:name` will result in only the `read:users:name` scope being passed on. In the case of no _intersection_, an empty set of scopes will be used.
|
||||
|
||||
The passed scopes are compared to the scopes required to access the API as follows:
|
||||
|
||||
@@ -85,7 +66,7 @@ The passed scopes are compared to the scopes required to access the API as follo
|
||||
|
||||
- if that is not the case, another check is utilized to determine if subscopes of the required API scopes can be found in the passed scope set:
|
||||
|
||||
- if found, the RBAC framework employs the {ref}`filtering <vertical-filtering-target>` procedures to refine the API response to access only resource attributes corresponding to the passed scopes. For example, providing a scope `read:users:activity!group=class-C` for the `GET /users` API will return a list of user models from group `class-C` containing only the `last_activity` attribute for each user model
|
||||
- if found, the RBAC framework employs the {ref}`filtering <vertical-filtering-target>` procedures to refine the API response to access only resource attributes corresponding to the passed scopes. For example, providing a scope `read:users:activity!group=class-C` for the _GET /users_ API will return a list of user models from group `class-C` containing only the `last_activity` attribute for each user model
|
||||
|
||||
- if not found, the access to API is denied
|
||||
|
||||
|
||||
@@ -9,12 +9,12 @@ To determine which scopes a role should have, one can follow these steps:
|
||||
5. Customize the scopes with filters if needed
|
||||
6. Define the role with required scopes and assign to users/services/groups/tokens
|
||||
|
||||
Below, different use cases are presented on how to use the [RBAC framework](./index.md)
|
||||
Below, different use cases are presented on how to use the RBAC framework.
|
||||
|
||||
## Service to cull idle servers
|
||||
|
||||
Finding and shutting down idle servers can save a lot of computational resources.
|
||||
**We can make use of [jupyterhub-idle-culler](https://github.com/jupyterhub/jupyterhub-idle-culler) to manage this for us.**
|
||||
We can make use of [jupyterhub-idle-culler](https://github.com/jupyterhub/jupyterhub-idle-culler) to manage this for us.
|
||||
Below follows a short tutorial on how to add a cull-idle service in the RBAC system.
|
||||
|
||||
1. Install the cull-idle server script with `pip install jupyterhub-idle-culler`.
|
||||
|
||||
@@ -31,7 +31,8 @@ popular services:
|
||||
- Okpy
|
||||
- OpenShift
|
||||
|
||||
A [generic implementation](https://github.com/jupyterhub/oauthenticator/blob/master/oauthenticator/generic.py), which you can use for OAuth authentication with any provider, is also available.
|
||||
A generic implementation, which you can use for OAuth authentication
|
||||
with any provider, is also available.
|
||||
|
||||
## The Dummy Authenticator
|
||||
|
||||
@@ -164,7 +165,7 @@ setup(
|
||||
```
|
||||
|
||||
If you have added this metadata to your package,
|
||||
admins can select your authenticator with the configuration:
|
||||
users can select your authenticator with the configuration:
|
||||
|
||||
```python
|
||||
c.JupyterHub.authenticator_class = 'myservice'
|
||||
@@ -246,23 +247,6 @@ class MyAuthenticator(Authenticator):
|
||||
spawner.environment['UPSTREAM_TOKEN'] = auth_state['upstream_token']
|
||||
```
|
||||
|
||||
Note that environment variable names and values are always strings, so passing multiple values means setting multiple environment variables or serializing more complex data into a single variable, e.g. as a JSON string.
|
||||
|
||||
auth state can also be used to configure the spawner via _config_ without subclassing
|
||||
by setting `c.Spawner.auth_state_hook`. This function will be called with `(spawner, auth_state)`,
|
||||
only when auth_state is defined.
|
||||
|
||||
For example:
|
||||
(for KubeSpawner)
|
||||
|
||||
```python
|
||||
def auth_state_hook(spawner, auth_state):
|
||||
spawner.volumes = auth_state['user_volumes']
|
||||
spawner.mounts = auth_state['user_mounts']
|
||||
|
||||
c.Spawner.auth_state_hook = auth_state_hook
|
||||
```
|
||||
|
||||
(authenticator-groups)=
|
||||
|
||||
## Authenticator-managed group membership
|
||||
@@ -297,7 +281,7 @@ all group-management via the API is disabled.
|
||||
|
||||
## pre_spawn_start and post_spawn_stop hooks
|
||||
|
||||
Authenticators use two hooks, {meth}`.Authenticator.pre_spawn_start` and
|
||||
Authenticators uses two hooks, {meth}`.Authenticator.pre_spawn_start` and
|
||||
{meth}`.Authenticator.post_spawn_stop(user, spawner)` to add pass additional state information
|
||||
between the authenticator and a spawner. These hooks are typically used auth-related
|
||||
startup, i.e. opening a PAM session, and auth-related cleanup, i.e. closing a
|
||||
|
||||
@@ -5,15 +5,15 @@ deployment with the following assumptions:
|
||||
|
||||
- Running JupyterHub on a single cloud server
|
||||
- Using SSL on the standard HTTPS port 443
|
||||
- Using GitHub OAuth (using [OAuthenticator](https://oauthenticator.readthedocs.io/en/latest)) for login
|
||||
- Using GitHub OAuth (using oauthenticator) for login
|
||||
- Using the default spawner (to configure other spawners, uncomment and edit
|
||||
`spawner_class` as well as follow the instructions for your desired spawner)
|
||||
- Users exist locally on the server
|
||||
- Users' notebooks to be served from `~/assignments` to allow users to browse
|
||||
for notebooks within other users' home directories
|
||||
- You want the landing page for each user to be a `Welcome.ipynb` notebook in
|
||||
their assignments directory
|
||||
- All runtime files are put into `/srv/jupyterhub` and log files in `/var/log`
|
||||
their assignments directory.
|
||||
- All runtime files are put into `/srv/jupyterhub` and log files in `/var/log`.
|
||||
|
||||
The `jupyterhub_config.py` file would have these settings:
|
||||
|
||||
@@ -69,7 +69,7 @@ c.Spawner.args = ['--NotebookApp.default_url=/notebooks/Welcome.ipynb']
|
||||
```
|
||||
|
||||
Using the GitHub Authenticator requires a few additional
|
||||
environment variables to be set prior to launching JupyterHub:
|
||||
environment variable to be set prior to launching JupyterHub:
|
||||
|
||||
```bash
|
||||
export GITHUB_CLIENT_ID=github_id
|
||||
@@ -79,5 +79,3 @@ export CONFIGPROXY_AUTH_TOKEN=super-secret
|
||||
# append log output to log file /var/log/jupyterhub.log
|
||||
jupyterhub -f /etc/jupyterhub/jupyterhub_config.py &>> /var/log/jupyterhub.log
|
||||
```
|
||||
|
||||
Visit the [Github OAuthenticator reference](https://oauthenticator.readthedocs.io/en/latest/api/gen/oauthenticator.github.html) to see the full list of options for configuring Github OAuth with JupyterHub.
|
||||
|
||||
@@ -14,7 +14,7 @@ satisfy the following:
|
||||
- After testing, the server in question should be able to score at least an A on the
|
||||
Qualys SSL Labs [SSL Server Test](https://www.ssllabs.com/ssltest/)
|
||||
|
||||
Let's start out with the needed JupyterHub configuration in `jupyterhub_config.py`:
|
||||
Let's start out with needed JupyterHub configuration in `jupyterhub_config.py`:
|
||||
|
||||
```python
|
||||
# Force the proxy to only listen to connections to 127.0.0.1 (on port 8000)
|
||||
@@ -30,15 +30,15 @@ This can take a few minutes:
|
||||
openssl dhparam -out /etc/ssl/certs/dhparam.pem 4096
|
||||
```
|
||||
|
||||
## Nginx
|
||||
## nginx
|
||||
|
||||
This **`nginx` config file** is fairly standard fare except for the two
|
||||
`location` blocks within the main section for HUB.DOMAIN.tld.
|
||||
To create a new site for jupyterhub in your Nginx config, make a new file
|
||||
To create a new site for jupyterhub in your nginx config, make a new file
|
||||
in `sites.enabled`, e.g. `/etc/nginx/sites.enabled/jupyterhub.conf`:
|
||||
|
||||
```bash
|
||||
# Top-level HTTP config for WebSocket headers
|
||||
# top-level http config for websocket headers
|
||||
# If Upgrade is defined, Connection = upgrade
|
||||
# If Upgrade is empty, Connection = close
|
||||
map $http_upgrade $connection_upgrade {
|
||||
@@ -51,7 +51,7 @@ server {
|
||||
listen 80;
|
||||
server_name HUB.DOMAIN.TLD;
|
||||
|
||||
# Redirect the request to HTTPS
|
||||
# Tell all requests to port 80 to be 302 redirected to HTTPS
|
||||
return 302 https://$host$request_uri;
|
||||
}
|
||||
|
||||
@@ -75,7 +75,7 @@ server {
|
||||
ssl_stapling_verify on;
|
||||
add_header Strict-Transport-Security max-age=15768000;
|
||||
|
||||
# Managing literal requests to the JupyterHub frontend
|
||||
# Managing literal requests to the JupyterHub front end
|
||||
location / {
|
||||
proxy_pass http://127.0.0.1:8000;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
@@ -101,10 +101,10 @@ server {
|
||||
If `nginx` is not running on port 443, substitute `$http_host` for `$host` on
|
||||
the lines setting the `Host` header.
|
||||
|
||||
`nginx` will now be the front-facing element of JupyterHub on `443` which means
|
||||
`nginx` will now be the front facing element of JupyterHub on `443` which means
|
||||
it is also free to bind other servers, like `NO_HUB.DOMAIN.TLD` to the same port
|
||||
on the same machine and network interface. In fact, one can simply use the same
|
||||
server blocks as above for `NO_HUB` and simply add a line for the root directory
|
||||
server blocks as above for `NO_HUB` and simply add line for the root directory
|
||||
of the site as well as the applicable location call:
|
||||
|
||||
```bash
|
||||
@@ -112,7 +112,7 @@ server {
|
||||
listen 80;
|
||||
server_name NO_HUB.DOMAIN.TLD;
|
||||
|
||||
# Redirect the request to HTTPS
|
||||
# Tell all requests to port 80 to be 302 redirected to HTTPS
|
||||
return 302 https://$host$request_uri;
|
||||
}
|
||||
|
||||
@@ -143,12 +143,12 @@ Now restart `nginx`, restart the JupyterHub, and enjoy accessing
|
||||
`https://HUB.DOMAIN.TLD` while serving other content securely on
|
||||
`https://NO_HUB.DOMAIN.TLD`.
|
||||
|
||||
### SELinux permissions for Nginx
|
||||
### SELinux permissions for nginx
|
||||
|
||||
On distributions with SELinux enabled (e.g. Fedora), one may encounter permission errors
|
||||
when the Nginx service is started.
|
||||
when the nginx service is started.
|
||||
|
||||
We need to allow Nginx to perform network relay and connect to the JupyterHub port. The
|
||||
We need to allow nginx to perform network relay and connect to the jupyterhub port. The
|
||||
following commands do that:
|
||||
|
||||
```bash
|
||||
@@ -157,26 +157,26 @@ setsebool -P httpd_can_network_relay 1
|
||||
setsebool -P httpd_can_network_connect 1
|
||||
```
|
||||
|
||||
Replace 8000 with the port the JupyterHub server is running from.
|
||||
Replace 8000 with the port the jupyterhub server is running from.
|
||||
|
||||
## Apache
|
||||
|
||||
As with Nginx above, you can use [Apache](https://httpd.apache.org) as the reverse proxy.
|
||||
First, we will need to enable the Apache modules that we are going to need:
|
||||
As with nginx above, you can use [Apache](https://httpd.apache.org) as the reverse proxy.
|
||||
First, we will need to enable the apache modules that we are going to need:
|
||||
|
||||
```bash
|
||||
a2enmod ssl rewrite proxy headers proxy_http proxy_wstunnel
|
||||
```
|
||||
|
||||
Our Apache configuration is equivalent to the Nginx configuration above:
|
||||
Our Apache configuration is equivalent to the nginx configuration above:
|
||||
|
||||
- Redirect HTTP to HTTPS
|
||||
- Good SSL Configuration
|
||||
- Support for WebSocket on any proxied URL
|
||||
- Support for websockets on any proxied URL
|
||||
- JupyterHub is running locally at http://127.0.0.1:8000
|
||||
|
||||
```bash
|
||||
# Redirect HTTP to HTTPS
|
||||
# redirect HTTP to HTTPS
|
||||
Listen 80
|
||||
<VirtualHost HUB.DOMAIN.TLD:80>
|
||||
ServerName HUB.DOMAIN.TLD
|
||||
@@ -188,26 +188,26 @@ Listen 443
|
||||
|
||||
ServerName HUB.DOMAIN.TLD
|
||||
|
||||
# Enable HTTP/2, if available
|
||||
# enable HTTP/2, if available
|
||||
Protocols h2 http/1.1
|
||||
|
||||
# HTTP Strict Transport Security (mod_headers is required) (63072000 seconds)
|
||||
Header always set Strict-Transport-Security "max-age=63072000"
|
||||
|
||||
# Configure SSL
|
||||
# configure SSL
|
||||
SSLEngine on
|
||||
SSLCertificateFile /etc/letsencrypt/live/HUB.DOMAIN.TLD/fullchain.pem
|
||||
SSLCertificateKeyFile /etc/letsencrypt/live/HUB.DOMAIN.TLD/privkey.pem
|
||||
SSLOpenSSLConfCmd DHParameters /etc/ssl/certs/dhparam.pem
|
||||
|
||||
# Intermediate configuration from SSL-config.mozilla.org (2022-03-03)
|
||||
# Please note, that this configuration might be outdated - please update it accordingly using https://ssl-config.mozilla.org/
|
||||
# intermediate configuration from ssl-config.mozilla.org (2022-03-03)
|
||||
# Please note, that this configuration might be out-dated - please update it accordingly using https://ssl-config.mozilla.org/
|
||||
SSLProtocol all -SSLv3 -TLSv1 -TLSv1.1
|
||||
SSLCipherSuite ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384
|
||||
SSLHonorCipherOrder off
|
||||
SSLSessionTickets off
|
||||
|
||||
# Use RewriteEngine to handle WebSocket connection upgrades
|
||||
# Use RewriteEngine to handle websocket connection upgrades
|
||||
RewriteEngine On
|
||||
RewriteCond %{HTTP:Connection} Upgrade [NC]
|
||||
RewriteCond %{HTTP:Upgrade} websocket [NC]
|
||||
@@ -224,15 +224,15 @@ Listen 443
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
In case of the need to run JupyterHub under /jhub/ or another location please use the below configurations:
|
||||
In case of the need to run the jupyterhub under /jhub/ or other location please use the below configurations:
|
||||
|
||||
- JupyterHub running locally at http://127.0.0.1:8000/jhub/ or other location
|
||||
|
||||
httpd.conf amendments:
|
||||
|
||||
```bash
|
||||
RewriteRule /jhub/(.*) ws://127.0.0.1:8000/jhub/$1 [P,L]
|
||||
RewriteRule /jhub/(.*) http://127.0.0.1:8000/jhub/$1 [P,L]
|
||||
RewriteRule /jhub/(.*) ws://127.0.0.1:8000/jhub/$1 [NE,P,L]
|
||||
RewriteRule /jhub/(.*) http://127.0.0.1:8000/jhub/$1 [NE,P,L]
|
||||
|
||||
ProxyPass /jhub/ http://127.0.0.1:8000/jhub/
|
||||
ProxyPassReverse /jhub/ http://127.0.0.1:8000/jhub/
|
||||
@@ -240,8 +240,8 @@ httpd.conf amendments:
|
||||
|
||||
jupyterhub_config.py amendments:
|
||||
|
||||
```python
|
||||
# The public facing URL of the whole JupyterHub application.
|
||||
# This is the address on which the proxy will bind. Sets protocol, IP, base_url
|
||||
c.JupyterHub.bind_url = 'http://127.0.0.1:8000/jhub/'
|
||||
```bash
|
||||
--The public facing URL of the whole JupyterHub application.
|
||||
--This is the address on which the proxy will bind. Sets protocol, ip, base_url
|
||||
c.JupyterHub.bind_url = 'http://127.0.0.1:8000/jhub/'
|
||||
```
|
||||
|
||||
@@ -6,10 +6,10 @@ Only do this if you are very sure you must.
|
||||
|
||||
## Overview
|
||||
|
||||
There are many [Authenticators](../getting-started/authenticators-users-basics) and [Spawners](../getting-started/spawners-basics) available for JupyterHub. Some, such
|
||||
as [DockerSpawner](https://github.com/jupyterhub/dockerspawner) or [OAuthenticator](https://github.com/jupyterhub/oauthenticator), do not need any elevated permissions. This
|
||||
There are many Authenticators and Spawners available for JupyterHub. Some, such
|
||||
as DockerSpawner or OAuthenticator, do not need any elevated permissions. This
|
||||
document describes how to get the full default behavior of JupyterHub while
|
||||
running notebook servers as real system users on a shared system, without
|
||||
running notebook servers as real system users on a shared system without
|
||||
running the Hub itself as root.
|
||||
|
||||
Since JupyterHub needs to spawn processes as other users, the simplest way
|
||||
@@ -69,8 +69,7 @@ Cmnd_Alias JUPYTER_CMD = /usr/local/bin/sudospawner
|
||||
rhea ALL=(JUPYTER_USERS) NOPASSWD:JUPYTER_CMD
|
||||
```
|
||||
|
||||
It might be useful to modify `secure_path` to add commands in path. (Search for
|
||||
`secure_path` in the [sudo docs](https://www.sudo.ws/man/1.8.14/sudoers.man.html)
|
||||
It might be useful to modify `secure_path` to add commands in path.
|
||||
|
||||
As an alternative to adding every user to the `/etc/sudoers` file, you can
|
||||
use a group in the last line above, instead of `JUPYTER_USERS`:
|
||||
@@ -91,7 +90,7 @@ $ adduser -G jupyterhub newuser
|
||||
Test that the new user doesn't need to enter a password to run the sudospawner
|
||||
command.
|
||||
|
||||
This should prompt for your password to switch to `rhea`, but _not_ prompt for
|
||||
This should prompt for your password to switch to rhea, but _not_ prompt for
|
||||
any password for the second switch. It should show some help output about
|
||||
logging options:
|
||||
|
||||
@@ -120,7 +119,7 @@ the shadow password database.
|
||||
|
||||
### Shadow group (Linux)
|
||||
|
||||
**Note:** On [Fedora based distributions](https://fedoraproject.org/wiki/List_of_Fedora_remixes) there is no clear way to configure
|
||||
**Note:** On Fedora based distributions there is no clear way to configure
|
||||
the PAM database to allow sufficient access for authenticating with the target user's password
|
||||
from JupyterHub. As a workaround we recommend use an
|
||||
[alternative authentication method](https://github.com/jupyterhub/jupyterhub/wiki/Authenticators).
|
||||
@@ -151,7 +150,7 @@ We want our new user to be able to read the shadow passwords, so add it to the s
|
||||
$ sudo usermod -a -G shadow rhea
|
||||
```
|
||||
|
||||
If you want jupyterhub to serve pages on a restricted port (such as port 80 for HTTP),
|
||||
If you want jupyterhub to serve pages on a restricted port (such as port 80 for http),
|
||||
then you will need to give `node` permission to do so:
|
||||
|
||||
```bash
|
||||
@@ -159,7 +158,6 @@ sudo setcap 'cap_net_bind_service=+ep' /usr/bin/node
|
||||
```
|
||||
|
||||
However, you may want to further understand the consequences of this.
|
||||
([Further reading](http://man7.org/linux/man-pages/man7/capabilities.7.html))
|
||||
|
||||
You may also be interested in limiting the amount of CPU any process can use
|
||||
on your server. `cpulimit` is a useful tool that is available for many Linux
|
||||
@@ -169,8 +167,7 @@ instructions](http://ubuntuforums.org/showthread.php?t=992706).
|
||||
|
||||
### Shadow group (FreeBSD)
|
||||
|
||||
**NOTE:** This has not been tested on FreeBSD and may not work as expected on
|
||||
the FreeBSD platform. _Do not use in production without verifying that it works properly!_
|
||||
**NOTE:** This has not been tested and may not work as expected.
|
||||
|
||||
```bash
|
||||
$ ls -l /etc/spwd.db /etc/master.passwd
|
||||
@@ -229,7 +226,7 @@ And try logging in.
|
||||
## Troubleshooting: SELinux
|
||||
|
||||
If you still get a generic `Permission denied` `PermissionError`, it's possible SELinux is blocking you.
|
||||
Here's how you can make a module to resolve this.
|
||||
Here's how you can make a module to allow this.
|
||||
First, put this in a file named `sudo_exec_selinux.te`:
|
||||
|
||||
```bash
|
||||
@@ -256,6 +253,6 @@ $ semodule -i sudo_exec_selinux.pp
|
||||
## Troubleshooting: PAM session errors
|
||||
|
||||
If the PAM authentication doesn't work and you see errors for
|
||||
`login:session-auth`, or similar, consider updating to a more recent version
|
||||
`login:session-auth`, or similar, considering updating to a more recent version
|
||||
of jupyterhub and disabling the opening of PAM sessions with
|
||||
`c.PAMAuthenticator.open_sessions=False`.
|
||||
|
||||
@@ -1,47 +1,49 @@
|
||||
# Configuring user environments
|
||||
|
||||
To deploy JupyterHub means you are providing Jupyter notebook environments for
|
||||
Deploying JupyterHub means you are providing Jupyter notebook environments for
|
||||
multiple users. Often, this includes a desire to configure the user
|
||||
environment in a custom way.
|
||||
environment in some way.
|
||||
|
||||
Since the `jupyterhub-singleuser` server extends the standard Jupyter notebook
|
||||
server, most configuration and documentation that applies to Jupyter Notebook
|
||||
applies to the single-user environments. Configuration of user environments
|
||||
typically does not occur through JupyterHub itself, but rather through system-wide
|
||||
configuration of Jupyter, which is inherited by `jupyterhub-singleuser`.
|
||||
typically does not occur through JupyterHub itself, but rather through system-
|
||||
wide configuration of Jupyter, which is inherited by `jupyterhub-singleuser`.
|
||||
|
||||
**Tip:** When searching for configuration tips for JupyterHub user environments, you might want to remove JupyterHub from your search because there are a lot more people out there configuring Jupyter than JupyterHub and the configuration is the same.
|
||||
**Tip:** When searching for configuration tips for JupyterHub user
|
||||
environments, try removing JupyterHub from your search because there are a lot
|
||||
more people out there configuring Jupyter than JupyterHub and the
|
||||
configuration is the same.
|
||||
|
||||
This section will focus on user environments, which includes the following:
|
||||
This section will focus on user environments, including:
|
||||
|
||||
- [Installing packages](#installing-packages)
|
||||
- [Configuring Jupyter and IPython](#configuring-jupyter-and-ipython)
|
||||
- [Installing kernelspecs](#installing-kernelspecs)
|
||||
- [Using containers vs. multi-user hosts](#multi-user-hosts-vs-containers)
|
||||
- Installing packages
|
||||
- Configuring Jupyter and IPython
|
||||
- Installing kernelspecs
|
||||
- Using containers vs. multi-user hosts
|
||||
|
||||
## Installing packages
|
||||
|
||||
To make packages available to users, you will typically install packages system-wide or in a shared environment.
|
||||
To make packages available to users, you generally will install packages
|
||||
system-wide or in a shared environment.
|
||||
|
||||
This installation location should always be in the same environment where
|
||||
This installation location should always be in the same environment that
|
||||
`jupyterhub-singleuser` itself is installed in, and must be _readable and
|
||||
executable_ by your users. If you want your users to be able to install additional
|
||||
packages, the installation location must also be _writable_ by your users.
|
||||
executable_ by your users. If you want users to be able to install additional
|
||||
packages, it must also be _writable_ by your users.
|
||||
|
||||
If you are using a standard Python installation on your system, use the following command:
|
||||
If you are using a standard system Python install, you would use:
|
||||
|
||||
```bash
|
||||
sudo python3 -m pip install numpy
|
||||
```
|
||||
|
||||
to install the numpy package in the default Python 3 environment on your system
|
||||
to install the numpy package in the default system Python 3 environment
|
||||
(typically `/usr/local`).
|
||||
|
||||
You may also use conda to install packages. If you do, you should make sure
|
||||
that the conda environment has appropriate permissions for users to be able to
|
||||
run Python code in the env. The env must be _readable and executable_ by all
|
||||
users. Additionally it must be _writeable_ if you want users to install
|
||||
additional packages.
|
||||
run Python code in the env.
|
||||
|
||||
## Configuring Jupyter and IPython
|
||||
|
||||
@@ -49,9 +51,15 @@ additional packages.
|
||||
and [IPython](https://ipython.readthedocs.io/en/stable/development/config.html)
|
||||
have their own configuration systems.
|
||||
|
||||
As a JupyterHub administrator, you will typically want to install and configure environments for all JupyterHub users. For example, let's say you wish for each student in a class to have the same user environment configuration.
|
||||
As a JupyterHub administrator, you will typically want to install and configure
|
||||
environments for all JupyterHub users. For example, you wish for each student in
|
||||
a class to have the same user environment configuration.
|
||||
|
||||
Jupyter and IPython support **"system-wide"** locations for configuration, which
|
||||
is the logical place to put global configuration that you want to affect all
|
||||
users. It's generally more efficient to configure user environments "system-wide",
|
||||
and it's a good idea to avoid creating files in users' home directories.
|
||||
|
||||
Jupyter and IPython support **"system-wide"** locations for configuration, which is the logical place to put global configuration that you want to affect all users. It's generally more efficient to configure user environments "system-wide", and it's a good practice to avoid creating files in the users' home directories.
|
||||
The typical locations for these config files are:
|
||||
|
||||
- **system-wide** in `/etc/{jupyter|ipython}`
|
||||
@@ -59,7 +67,8 @@ The typical locations for these config files are:
|
||||
|
||||
### Example: Enable an extension system-wide
|
||||
|
||||
For example, to enable the `cython` IPython extension for all of your users, create the file `/etc/ipython/ipython_config.py`:
|
||||
For example, to enable the `cython` IPython extension for all of your users,
|
||||
create the file `/etc/ipython/ipython_config.py`:
|
||||
|
||||
```python
|
||||
c.InteractiveShellApp.extensions.append("cython")
|
||||
@@ -68,18 +77,21 @@ c.InteractiveShellApp.extensions.append("cython")
|
||||
### Example: Enable a Jupyter notebook configuration setting for all users
|
||||
|
||||
:::{note}
|
||||
These examples configure the Jupyter ServerApp, which is used by JupyterLab, the default in JupyterHub 2.0.
|
||||
These examples configure the Jupyter ServerApp,
|
||||
which is used by JupyterLab, the default in JupyterHub 2.0.
|
||||
|
||||
If you are using the classing Jupyter Notebook server,
|
||||
the same things should work,
|
||||
with the following substitutions:
|
||||
|
||||
- Search for `jupyter_server_config`, and replace with `jupyter_notebook_config`
|
||||
- Search for `NotebookApp`, and replace with `ServerApp`
|
||||
- Where you see `jupyter_server_config`, use `jupyter_notebook_config`
|
||||
- Where you see `NotebookApp`, use `ServerApp`
|
||||
|
||||
:::
|
||||
|
||||
To enable Jupyter notebook's internal idle-shutdown behavior (requires notebook ≥ 5.4), set the following in the `/etc/jupyter/jupyter_server_config.py` file:
|
||||
To enable Jupyter notebook's internal idle-shutdown behavior (requires
|
||||
notebook ≥ 5.4), set the following in the `/etc/jupyter/jupyter_server_config.py`
|
||||
file:
|
||||
|
||||
```python
|
||||
# shutdown the server after no activity for an hour
|
||||
@@ -92,14 +104,16 @@ c.MappingKernelManager.cull_interval = 2 * 60
|
||||
|
||||
## Installing kernelspecs
|
||||
|
||||
You may have multiple Jupyter kernels installed and want to make sure that they are available to all of your users. This means installing kernelspecs either system-wide (e.g. in /usr/local/) or in the `sys.prefix` of JupyterHub
|
||||
You may have multiple Jupyter kernels installed and want to make sure that
|
||||
they are available to all of your users. This means installing kernelspecs
|
||||
either system-wide (e.g. in /usr/local/) or in the `sys.prefix` of JupyterHub
|
||||
itself.
|
||||
|
||||
Jupyter kernelspec installation is system-wide by default, but some kernels
|
||||
Jupyter kernelspec installation is system wide by default, but some kernels
|
||||
may default to installing kernelspecs in your home directory. These will need
|
||||
to be moved system-wide to ensure that they are accessible.
|
||||
|
||||
To see where your kernelspecs are, you can use the following command:
|
||||
You can see where your kernelspecs are with:
|
||||
|
||||
```bash
|
||||
jupyter kernelspec list
|
||||
@@ -107,7 +121,8 @@ jupyter kernelspec list
|
||||
|
||||
### Example: Installing kernels system-wide
|
||||
|
||||
Let's assume that I have a Python 2 and Python 3 environment that I want to make sure are available, I can install their specs **system-wide** (in /usr/local) using the following command:
|
||||
Assuming I have a Python 2 and Python 3 environment that I want to make
|
||||
sure are available, I can install their specs system-wide (in /usr/local) with:
|
||||
|
||||
```bash
|
||||
/path/to/python3 -m ipykernel install --prefix=/usr/local
|
||||
@@ -126,25 +141,31 @@ How you configure user environments for each category can differ a bit
|
||||
depending on what Spawner you are using.
|
||||
|
||||
The first category is a **shared system (multi-user host)** where
|
||||
each user has a JupyterHub account, a home directory as well as being
|
||||
each user has a JupyterHub account and a home directory as well as being
|
||||
a real system user. In this example, shared configuration and installation
|
||||
must be in a 'system-wide' location, such as `/etc/`, or `/usr/local`
|
||||
must be in a 'system-wide' location, such as `/etc/` or `/usr/local`
|
||||
or a custom prefix such as `/opt/conda`.
|
||||
|
||||
When JupyterHub uses **container-based** Spawners (e.g. KubeSpawner or
|
||||
DockerSpawner), the 'system-wide' environment is really the container image used for users.
|
||||
DockerSpawner), the 'system-wide' environment is really the container image
|
||||
which you are using for users.
|
||||
|
||||
In both cases, you want to _avoid putting configuration in user home
|
||||
directories_ because users can change those configuration settings. Also, home directories typically persist once they are created, thereby making it difficult for admins to update later.
|
||||
directories_ because users can change those configuration settings. Also,
|
||||
home directories typically persist once they are created, so they are
|
||||
difficult for admins to update later.
|
||||
|
||||
## Named servers
|
||||
|
||||
By default, in a JupyterHub deployment, each user has one server only.
|
||||
By default, in a JupyterHub deployment each user has exactly one server.
|
||||
|
||||
JupyterHub can, however, have multiple servers per user.
|
||||
This is mostly useful in deployments where users can configure the environment in which their server will start (e.g. resource requests on an HPC cluster), so that a given user can have multiple configurations running at the same time, without having to stop and restart their own server.
|
||||
This is most useful in deployments where users can configure the environment
|
||||
in which their server will start (e.g. resource requests on an HPC cluster),
|
||||
so that a given user can have multiple configurations running at the same time,
|
||||
without having to stop and restart their one server.
|
||||
|
||||
To allow named servers, include this code snippet in your config file:
|
||||
To allow named servers:
|
||||
|
||||
```python
|
||||
c.JupyterHub.allow_named_servers = True
|
||||
@@ -160,39 +181,22 @@ as well as the admin page:
|
||||

|
||||
|
||||
Named servers can be accessed, created, started, stopped, and deleted
|
||||
from these pages. Activity tracking is now per server as well.
|
||||
from these pages. Activity tracking is now per-server as well.
|
||||
|
||||
To limit the number of **named server** per user by setting a constant value, include this code snippet in your config file:
|
||||
The number of named servers per user can be limited by setting
|
||||
|
||||
```python
|
||||
c.JupyterHub.named_server_limit_per_user = 5
|
||||
```
|
||||
|
||||
Alternatively, to use a callable/awaitable based on the handler object, include this code snippet in your config file:
|
||||
|
||||
```python
|
||||
def named_server_limit_per_user_fn(handler):
|
||||
user = handler.current_user
|
||||
if user and user.admin:
|
||||
return 0
|
||||
return 5
|
||||
|
||||
c.JupyterHub.named_server_limit_per_user = named_server_limit_per_user_fn
|
||||
```
|
||||
|
||||
This can be useful for quota service implementations. The example above limits the number of named servers for non-admin users only.
|
||||
|
||||
If `named_server_limit_per_user` is set to `0`, no limit is enforced.
|
||||
|
||||
(classic-notebook-ui)=
|
||||
|
||||
## Switching back to the classic notebook
|
||||
## Switching back to classic notebook
|
||||
|
||||
By default, the single-user server launches JupyterLab,
|
||||
By default the single-user server launches JupyterLab,
|
||||
which is based on [Jupyter Server][].
|
||||
|
||||
This is the default server when running JupyterHub ≥ 2.0.
|
||||
To switch to using the legacy Jupyter Notebook server, you can set the `JUPYTERHUB_SINGLEUSER_APP` environment variable
|
||||
You can switch to using the legacy Jupyter Notebook server by setting the `JUPYTERHUB_SINGLEUSER_APP` environment variable
|
||||
(in the single-user environment) to:
|
||||
|
||||
```bash
|
||||
@@ -203,20 +207,19 @@ export JUPYTERHUB_SINGLEUSER_APP='notebook.notebookapp.NotebookApp'
|
||||
[jupyter notebook]: https://jupyter-notebook.readthedocs.io
|
||||
|
||||
:::{versionchanged} 2.0
|
||||
|
||||
JupyterLab is now the default single-user UI, if available,
|
||||
JupyterLab is now the default singleuser UI, if available,
|
||||
which is based on the [Jupyter Server][],
|
||||
no longer the legacy [Jupyter Notebook][] server.
|
||||
JupyterHub prior to 2.0 launched the legacy notebook server (`jupyter notebook`),
|
||||
and the Jupyter server could be selected by specifying the following:
|
||||
and Jupyter server could be selected by specifying
|
||||
|
||||
```python
|
||||
# jupyterhub_config.py
|
||||
c.Spawner.cmd = ["jupyter-labhub"]
|
||||
```
|
||||
|
||||
Alternatively, for an otherwise customized Jupyter Server app,
|
||||
set the environment variable using the following command:
|
||||
or for an otherwise customized Jupyter Server app,
|
||||
set the environment variable:
|
||||
|
||||
```bash
|
||||
export JUPYTERHUB_SINGLEUSER_APP='jupyter_server.serverapp.ServerApp'
|
||||
|
||||
@@ -1,26 +1,26 @@
|
||||
# JupyterHub and OAuth
|
||||
|
||||
JupyterHub uses [OAuth 2](https://oauth.net/2/) as an internal mechanism for authenticating users.
|
||||
JupyterHub uses OAuth 2 internally as a mechanism for authenticating users.
|
||||
As such, JupyterHub itself always functions as an OAuth **provider**.
|
||||
You can find out more about what that means [below](oauth-terms).
|
||||
More on what that means [below](oauth-terms).
|
||||
|
||||
Additionally, JupyterHub is _often_ deployed with [OAuthenticator](https://oauthenticator.readthedocs.io),
|
||||
Additionally, JupyterHub is _often_ deployed with [oauthenticator](https://oauthenticator.readthedocs.io),
|
||||
where an external identity provider, such as GitHub or KeyCloak, is used to authenticate users.
|
||||
When this is the case, there are _two_ nested OAuth flows:
|
||||
an _internal_ OAuth flow where JupyterHub is the **provider**,
|
||||
and an _external_ OAuth flow, where JupyterHub is the **client**.
|
||||
When this is the case, there are _two_ nested oauth flows:
|
||||
an _internal_ oauth flow where JupyterHub is the **provider**,
|
||||
and and _external_ oauth flow, where JupyterHub is a **client**.
|
||||
|
||||
This means that when you are using JupyterHub, there is always _at least one_ and often two layers of OAuth involved in a user logging in and accessing their server.
|
||||
|
||||
The following points are noteworthy:
|
||||
Some relevant points:
|
||||
|
||||
- Single-user servers _never_ need to communicate with or be aware of the upstream provider configured in your Authenticator.
|
||||
As far as the servers are concerned, only JupyterHub is an OAuth provider,
|
||||
As far as they are concerned, only JupyterHub is an OAuth provider,
|
||||
and how users authenticate with the Hub itself is irrelevant.
|
||||
- When interacting with a single-user server,
|
||||
- When talking to a single-user server,
|
||||
there are ~always two tokens:
|
||||
first, a token issued to the server itself to communicate with the Hub API,
|
||||
and second, a per-user token in the browser to represent the completed login process and authorized permissions.
|
||||
a token issued to the server itself to communicate with the Hub API,
|
||||
and a second per-user token in the browser to represent the completed login process and authorized permissions.
|
||||
More on this [later](two-tokens).
|
||||
|
||||
(oauth-terms)=
|
||||
@@ -28,66 +28,66 @@ The following points are noteworthy:
|
||||
## Key OAuth terms
|
||||
|
||||
Here are some key definitions to keep in mind when we are talking about OAuth.
|
||||
You can also read more in detail [here](https://www.oauth.com/oauth2-servers/definitions/).
|
||||
You can also read more detail [here](https://www.oauth.com/oauth2-servers/definitions/).
|
||||
|
||||
- **provider**: The entity responsible for managing identity and authorization;
|
||||
- **provider** the entity responsible for managing identity and authorization,
|
||||
always a web server.
|
||||
JupyterHub is _always_ an OAuth provider for JupyterHub's components.
|
||||
When OAuthenticator is used, an external service, such as GitHub or KeyCloak, is also an OAuth provider.
|
||||
- **client**: An entity that requests OAuth **tokens** on a user's behalf;
|
||||
JupyterHub is _always_ an oauth provider for JupyterHub's components.
|
||||
When OAuthenticator is used, an external service, such as GitHub or KeyCloak, is also an oauth provider.
|
||||
- **client** An entity that requests OAuth **tokens** on a user's behalf,
|
||||
generally a web server of some kind.
|
||||
OAuth **clients** are services that _delegate_ authentication and/or authorization
|
||||
to an OAuth **provider**.
|
||||
JupyterHub _services_ or single-user _servers_ are OAuth **clients** of the JupyterHub **provider**.
|
||||
When OAuthenticator is used, JupyterHub is itself _also_ an OAuth **client** for the external OAuth **provider**, e.g. GitHub.
|
||||
- **browser**: A user's web browser, which makes requests and stores things like cookies.
|
||||
- **token**: The secret value used to represent a user's authorization. This is the final product of the OAuth process.
|
||||
- **code**: A short-lived temporary secret that the **client** exchanges
|
||||
for a **token** at the conclusion of OAuth,
|
||||
in what's generally called the "OAuth callback handler."
|
||||
When OAuthenticator is used, JupyterHub is itself _also_ an OAuth **client** for the external oauth **provider**, e.g. GitHub.
|
||||
- **browser** A user's web browser, which makes requests and stores things like cookies
|
||||
- **token** The secret value used to represent a user's authorization. This is the final product of the OAuth process.
|
||||
- **code** A short-lived temporary secret that the **client** exchanges
|
||||
for a **token** at the conclusion of oauth,
|
||||
in what's generally called the "oauth callback handler."
|
||||
|
||||
## One oauth flow
|
||||
|
||||
OAuth **flow** is what we call the sequence of HTTP requests involved in authenticating a user and issuing a token, ultimately used for authorizing access to a service or single-user server.
|
||||
OAuth **flow** is what we call the sequence of HTTP requests involved in authenticating a user and issuing a token, ultimately used for authorized access to a service or single-user server.
|
||||
|
||||
A single OAuth flow typically goes like this:
|
||||
A single oauth flow generally goes like this:
|
||||
|
||||
### OAuth request and redirect
|
||||
|
||||
1. A **browser** makes an HTTP request to an OAuth **client**.
|
||||
2. There are no credentials, so the client _redirects_ the browser to an "authorize" page on the OAuth **provider** with some extra information:
|
||||
- the OAuth **client ID** of the client itself.
|
||||
- the **redirect URI** to be redirected back to after completion.
|
||||
1. A **browser** makes an HTTP request to an oauth **client**.
|
||||
2. There are no credentials, so the client _redirects_ the browser to an "authorize" page on the oauth **provider** with some extra information:
|
||||
- the oauth **client id** of the client itself
|
||||
- the **redirect uri** to be redirected back to after completion
|
||||
- the **scopes** requested, which the user should be presented with to confirm.
|
||||
This is the "X would like to be able to Y on your behalf. Allow this?" page you see on all the "Login with ..." pages around the Internet.
|
||||
3. During this authorize step,
|
||||
the browser must be _authenticated_ with the provider.
|
||||
This is often already stored in a cookie,
|
||||
but if not the provider webapp must begin its _own_ authentication process before serving the authorization page.
|
||||
This _may_ even begin another OAuth flow!
|
||||
This _may_ even begin another oauth flow!
|
||||
4. After the user tells the provider that they want to proceed with the authorization,
|
||||
the provider records this authorization in a short-lived record called an **OAuth code**.
|
||||
5. Finally, the oauth provider redirects the browser _back_ to the oauth client's "redirect URI"
|
||||
(or "OAuth callback URI"),
|
||||
with the OAuth code in a URL parameter.
|
||||
the provider records this authorization in a short-lived record called an **oauth code**.
|
||||
5. Finally, the oauth provider redirects the browser _back_ to the oauth client's "redirect uri"
|
||||
(or "oauth callback uri"),
|
||||
with the oauth code in a url parameter.
|
||||
|
||||
That marks the end of the requests made between the **browser** and the **provider**.
|
||||
That's the end of the requests made between the **browser** and the **provider**.
|
||||
|
||||
### State after redirect
|
||||
|
||||
At this point:
|
||||
|
||||
- The browser is authenticated with the _provider_.
|
||||
- The user's authorized permissions are recorded in an _OAuth code_.
|
||||
- The _provider_ knows that the permissions requested by the OAuth client have been granted, but the client doesn't know this yet.
|
||||
- All the requests so far have been made directly by the browser.
|
||||
No requests have originated from the client or provider.
|
||||
- The browser is authenticated with the _provider_
|
||||
- The user's authorized permissions are recorded in an _oauth code_
|
||||
- The _provider_ knows that the given oauth client's requested permissions have been granted, but the client doesn't know this yet.
|
||||
- All requests so far have been made directly by the browser.
|
||||
No requests have originated at the client or provider.
|
||||
|
||||
### OAuth Client Handles Callback Request
|
||||
|
||||
At this stage, we get to finish the OAuth process.
|
||||
Let's dig into what the OAuth client does when it handles
|
||||
the OAuth callback request.
|
||||
Now we get to finish the OAuth process.
|
||||
Let's dig into what the oauth client does when it handles
|
||||
the oauth callback request with the
|
||||
|
||||
- The OAuth client receives the _code_ and makes an API request to the _provider_ to exchange the code for a real _token_.
|
||||
This is the first direct request between the OAuth _client_ and the _provider_.
|
||||
@@ -95,12 +95,12 @@ the OAuth callback request.
|
||||
makes a second API request to the _provider_
|
||||
to retrieve information about the owner of the token (the user).
|
||||
This is the step where behavior diverges for different OAuth providers.
|
||||
Up to this point, all OAuth providers are the same, following the OAuth specification.
|
||||
However, OAuth does not define a standard for issuing tokens in exchange for information about their owner or permissions ([OpenID Connect](https://openid.net/connect/) does that),
|
||||
Up to this point, all oauth providers are the same, following the oauth specification.
|
||||
However, oauth does not define a standard for exchanging tokens for information about their owner or permissions ([OpenID Connect](https://openid.net/connect/) does that),
|
||||
so this step may be different for each OAuth provider.
|
||||
- Finally, the OAuth client stores its own record that the user is authorized in a cookie.
|
||||
- Finally, the oauth client stores its own record that the user is authorized in a cookie.
|
||||
This could be the token itself, or any other appropriate representation of successful authentication.
|
||||
- Now that credentials have been established,
|
||||
- Last of all, now that credentials have been established,
|
||||
the browser can be redirected to the _original_ URL where it started,
|
||||
to try the request again.
|
||||
If the client wasn't able to keep track of the original URL all this time
|
||||
@@ -113,24 +113,24 @@ So that's _one_ OAuth process.
|
||||
|
||||
## Full sequence of OAuth in JupyterHub
|
||||
|
||||
Let's go through the above OAuth process in JupyterHub,
|
||||
with specific examples of each HTTP request and what information it contains.
|
||||
For bonus points, we are using the double-OAuth example of JupyterHub configured with GitHubOAuthenticator.
|
||||
Let's go through the above oauth process in JupyterHub,
|
||||
with specific examples of each HTTP request and what information is contained.
|
||||
For bonus points, we are using the double-oauth example of JupyterHub configured with GitHubOAuthenticator.
|
||||
|
||||
To disambiguate, we will call the OAuth process where JupyterHub is the **provider** "internal OAuth,"
|
||||
and the one with JupyterHub as a **client** "external OAuth."
|
||||
To disambiguate, we will call the OAuth process where JupyterHub is the **provider** "internal oauth,"
|
||||
and the one with JupyterHub as a **client** "external oauth."
|
||||
|
||||
Our starting point:
|
||||
|
||||
- a user's single-user server is running. Let's call them `danez`
|
||||
- Jupyterhub is running with GitHub as an OAuth provider (this means two full instances of OAuth),
|
||||
- Danez has a fresh browser session with no cookies yet.
|
||||
- jupyterhub is running with GitHub as an oauth provider (this means two full instances of oauth),
|
||||
- Danez has a fresh browser session with no cookies yet
|
||||
|
||||
First request:
|
||||
|
||||
- browser->single-user server running JupyterLab or Jupyter Classic
|
||||
- `GET /user/danez/notebooks/mynotebook.ipynb`
|
||||
- no credentials, so single-user server (as an OAuth **client**) starts internal OAuth process with JupyterHub (the **provider**)
|
||||
- no credentials, so single-user server (as an oauth **client**) starts internal oauth process with JupyterHub (the **provider**)
|
||||
- response: 302 redirect -> `/hub/api/oauth2/authorize`
|
||||
with:
|
||||
- client-id=`jupyterhub-user-danez`
|
||||
@@ -138,9 +138,9 @@ First request:
|
||||
|
||||
Second request, following redirect:
|
||||
|
||||
- browser->JupyterHub
|
||||
- browser->jupyterhub
|
||||
- `GET /hub/api/oauth2/authorize`
|
||||
- no credentials, so JupyterHub starts external OAuth process _with GitHub_
|
||||
- no credentials, so jupyterhub starts external oauth process _with GitHub_
|
||||
- response: 302 redirect -> `https://github.com/login/oauth/authorize`
|
||||
with:
|
||||
- client-id=`jupyterhub-client-uuid`
|
||||
@@ -154,8 +154,8 @@ c.JupyterHub.authenticator_class = 'github'
|
||||
```
|
||||
|
||||
That means authenticating a request to the Hub itself starts
|
||||
a _second_, external OAuth process with GitHub as a provider.
|
||||
This external OAuth process is optional, though.
|
||||
a _second_, external oauth process with GitHub as a provider.
|
||||
This external oauth process is optional, though.
|
||||
If you were using the default username+password PAMAuthenticator,
|
||||
this redirect would have been to `/hub/login` instead, to present the user
|
||||
with a login form.
|
||||
@@ -171,7 +171,7 @@ Here, GitHub prompts for login and asks for confirmation of authorization
|
||||
After successful authorization
|
||||
(either by looking up a pre-existing authorization,
|
||||
or recording it via form submission)
|
||||
GitHub issues an **OAuth code** and redirects to `/hub/oauth_callback?code=github-code`
|
||||
GitHub issues an **oauth code** and redirects to `/hub/oauth_callback?code=github-code`
|
||||
|
||||
Next request:
|
||||
|
||||
@@ -184,7 +184,7 @@ The first:
|
||||
|
||||
- JupyterHub->GitHub
|
||||
- `POST https://github.com/login/oauth/access_token`
|
||||
- request made with OAuth **code** from URL parameter
|
||||
- request made with oauth **code** from url parameter
|
||||
- response includes an access **token**
|
||||
|
||||
The second:
|
||||
@@ -194,9 +194,9 @@ The second:
|
||||
- request made with access **token** in the `Authorization` header
|
||||
- response is the user model, including username, email, etc.
|
||||
|
||||
Now the external OAuth callback request completes with:
|
||||
Now the external oauth callback request completes with:
|
||||
|
||||
- set cookie on `/hub/` path, recording jupyterhub authentication so we don't need to do external OAuth with GitHub again for a while
|
||||
- set cookie on `/hub/` path, recording jupyterhub authentication so we don't need to do external oauth with GitHub again for a while
|
||||
- redirect -> `/hub/api/oauth2/authorize`
|
||||
|
||||
🎉 At this point, we have completed our first OAuth flow! 🎉
|
||||
@@ -211,14 +211,14 @@ Now, we get our first repeated request:
|
||||
2. automatically accepts authorization (shortcut taken when a user is visiting their own server)
|
||||
- redirect -> `/user/danez/oauth_callback?code=jupyterhub-code`
|
||||
|
||||
Here, we start the same OAuth callback process as before, but at Danez's single-user server for the _internal_ OAuth.
|
||||
Here, we start the same oauth callback process as before, but at Danez's single-user server for the _internal_ oauth
|
||||
|
||||
- browser->single-user server
|
||||
- `GET /user/danez/oauth_callback`
|
||||
|
||||
(in handler)
|
||||
|
||||
Inside the internal OAuth callback handler,
|
||||
Inside the internal oauth callback handler,
|
||||
Danez's server makes two API requests to JupyterHub:
|
||||
|
||||
The first:
|
||||
@@ -271,15 +271,15 @@ To handle this, OAuth tokens and the various places they are stored can _expire_
|
||||
which should have the same effect as no credentials,
|
||||
and trigger the authorization process again.
|
||||
|
||||
In JupyterHub's internal OAuth, we have these layers of information that can go stale:
|
||||
In JupyterHub's internal oauth, we have these layers of information that can go stale:
|
||||
|
||||
- The OAuth client has a **cache** of Hub responses for tokens,
|
||||
- The oauth client has a **cache** of Hub responses for tokens,
|
||||
so it doesn't need to make API requests to the Hub for every request it receives.
|
||||
This cache has an expiry of five minutes by default,
|
||||
and is governed by the configuration `HubAuth.cache_max_age` in the single-user server.
|
||||
- The internal OAuth token is stored in a cookie, which has its own expiry (default: 14 days),
|
||||
- The internal oauth token is stored in a cookie, which has its own expiry (default: 14 days),
|
||||
governed by `JupyterHub.cookie_max_age_days`.
|
||||
- The internal OAuth token itself can also expire,
|
||||
- The internal oauth token can also itself expire,
|
||||
which is by default the same as the cookie expiry,
|
||||
since it makes sense for the token itself and the place it is stored to expire at the same time.
|
||||
This is governed by `JupyterHub.cookie_max_age_days` first,
|
||||
@@ -317,9 +317,9 @@ triggering the external login process anew before letting a user proceed.
|
||||
- If the token has expired, but is still in the cookie:
|
||||
when the token response cache expires,
|
||||
the next time the server asks the hub about the token,
|
||||
no user will be identified and the internal OAuth process begins again.
|
||||
no user will be identified and the internal oauth process begins again.
|
||||
- If the token _cookie_ expires, the next browser request will be made with no credentials,
|
||||
and the internal OAuth process will begin again.
|
||||
and the internal oauth process will begin again.
|
||||
This will usually have the form of a transparent redirect browsers won't notice.
|
||||
However, if this occurs on an API request in a long-lived page visit
|
||||
such as a JupyterLab session, the API request may fail and require
|
||||
@@ -352,7 +352,7 @@ Logging out of JupyterHub means clearing and revoking many of these credentials:
|
||||
### A tale of two tokens
|
||||
|
||||
**TODO**: discuss API token issued to server at startup ($JUPYTERHUB_API_TOKEN)
|
||||
and OAuth-issued token in the cookie,
|
||||
and oauth-issued token in the cookie,
|
||||
and some details of how JupyterLab currently deals with that.
|
||||
They are different, and JupyterLab should be making requests using the token from the cookie,
|
||||
not the token from the server,
|
||||
|
||||
@@ -7,12 +7,9 @@ Hub manages by default as a subprocess (it can be run externally, as well, and
|
||||
typically is in production deployments).
|
||||
|
||||
The upside to CHP, and why we use it by default, is that it's easy to install
|
||||
and run (if you have nodejs, you are set!). The downsides are that
|
||||
|
||||
- it's a single process and
|
||||
- does not support any persistence of the routing table.
|
||||
|
||||
So if the proxy process dies, your whole JupyterHub instance is inaccessible
|
||||
and run (if you have nodejs, you are set!). The downsides are that it's a
|
||||
single process and does not support any persistence of the routing table. So
|
||||
if the proxy process dies, your whole JupyterHub instance is inaccessible
|
||||
until the Hub notices, restarts the proxy, and restores the routing table. For
|
||||
deployments that want to avoid such a single point of failure, or leverage
|
||||
existing proxy infrastructure in their chosen deployment (such as Kubernetes
|
||||
@@ -141,7 +138,7 @@ async def delete_route(self, routespec):
|
||||
|
||||
For retrieval, you only _need_ to implement a single method that retrieves all
|
||||
routes. The return value for this function should be a dictionary, keyed by
|
||||
`routespec`, of dicts whose keys are the same three arguments passed to
|
||||
`routespect`, of dicts whose keys are the same three arguments passed to
|
||||
`add_route` (`routespec`, `target`, `data`)
|
||||
|
||||
```python
|
||||
@@ -207,7 +204,7 @@ setup(
|
||||
```
|
||||
|
||||
If you have added this metadata to your package,
|
||||
admins can select your authenticator with the configuration:
|
||||
users can select your proxy with the configuration:
|
||||
|
||||
```python
|
||||
c.JupyterHub.proxy_class = 'mything'
|
||||
@@ -219,7 +216,7 @@ instead of the full
|
||||
c.JupyterHub.proxy_class = 'mypackage:MyProxy'
|
||||
```
|
||||
|
||||
as previously required.
|
||||
previously required.
|
||||
Additionally, configurable attributes for your proxy will
|
||||
appear in jupyterhub help output and auto-generated configuration files
|
||||
via `jupyterhub --generate-config`.
|
||||
|
||||
@@ -4,36 +4,33 @@
|
||||
|
||||
This section will give you information on:
|
||||
|
||||
- What you can do with the API
|
||||
- How to create an API token
|
||||
- Assigning permissions to a token
|
||||
- Updating to admin services
|
||||
- Making an API request programmatically using the requests library
|
||||
- Paginating API requests
|
||||
- Enabling users to spawn multiple named-servers via the API
|
||||
- Learn more about JupyterHub's API
|
||||
|
||||
Before we discuss about JupyterHub's REST API, you can learn about [REST APIs here](https://en.wikipedia.org/wiki/Representational_state_transfer). A REST
|
||||
API provides a standard way for users to get and send information to the
|
||||
Hub.
|
||||
- what you can do with the API
|
||||
- create an API token
|
||||
- add API tokens to the config files
|
||||
- make an API request programmatically using the requests library
|
||||
- learn more about JupyterHub's API
|
||||
|
||||
## What you can do with the API
|
||||
|
||||
Using the [JupyterHub REST API][], you can perform actions on the Hub,
|
||||
such as:
|
||||
|
||||
- Checking which users are active
|
||||
- Adding or removing users
|
||||
- Stopping or starting single user notebook servers
|
||||
- Authenticating services
|
||||
- Communicating with an individual Jupyter server's REST API
|
||||
- checking which users are active
|
||||
- adding or removing users
|
||||
- stopping or starting single user notebook servers
|
||||
- authenticating services
|
||||
- communicating with an individual Jupyter server's REST API
|
||||
|
||||
A [REST](https://en.wikipedia.org/wiki/Representational_state_transfer)
|
||||
API provides a standard way for users to get and send information to the
|
||||
Hub.
|
||||
|
||||
## Create an API token
|
||||
|
||||
To send requests using the JupyterHub API, you must pass an API token with
|
||||
To send requests using JupyterHub API, you must pass an API token with
|
||||
the request.
|
||||
|
||||
The preferred way of generating an API token is by running:
|
||||
The preferred way of generating an API token is:
|
||||
|
||||
```bash
|
||||
openssl rand -hex 32
|
||||
@@ -43,12 +40,8 @@ This `openssl` command generates a potential token that can then be
|
||||
added to JupyterHub using `.api_tokens` configuration setting in
|
||||
`jupyterhub_config.py`.
|
||||
|
||||
```{note}
|
||||
The api_tokens configuration has been softly deprecated since the introduction of services.
|
||||
```
|
||||
|
||||
Alternatively, you can use the `jupyterhub token` command to generate a token
|
||||
for a specific hub user by passing the **username**:
|
||||
Alternatively, use the `jupyterhub token` command to generate a token
|
||||
for a specific hub user by passing the 'username':
|
||||
|
||||
```bash
|
||||
jupyterhub token <username>
|
||||
@@ -60,19 +53,9 @@ it for the given user with the Hub's database.
|
||||
In [version 0.8.0](../changelog.md), a token request page for
|
||||
generating an API token is available from the JupyterHub user interface:
|
||||
|
||||
:::{figure-md}
|
||||

|
||||
|
||||

|
||||
|
||||
JupyterHub's API token page
|
||||
:::
|
||||
|
||||
:::{figure-md}
|
||||

|
||||
|
||||
JupyterHub's token page after successfully requesting a token.
|
||||
|
||||
:::
|
||||

|
||||
|
||||
## Assigning permissions to a token
|
||||
|
||||
@@ -84,26 +67,25 @@ Prior to JupyterHub 2.0, there were two levels of permissions:
|
||||
where a token would always have full permissions to do whatever its owner could do.
|
||||
|
||||
In JupyterHub 2.0,
|
||||
specific permissions are now defined as '**scopes**',
|
||||
specific permissions are now defined as 'scopes',
|
||||
and can be assigned both at the user/service level,
|
||||
and at the individual token level.
|
||||
|
||||
This allows e.g. a user with full admin permissions to request a token with limited permissions.
|
||||
|
||||
## Updating to admin services
|
||||
### Updating to admin services
|
||||
|
||||
```{note}
|
||||
The `api_tokens` configuration has been softly deprecated since the introduction of services.
|
||||
We have no plans to remove it,
|
||||
but deployments are encouraged to use service configuration instead.
|
||||
```
|
||||
|
||||
If you have been using `api_tokens` to create an admin user
|
||||
and the token for that user to perform some automations, then
|
||||
the services' mechanism may be a better fit if you have the following configuration:
|
||||
and a token for that user to perform some automations,
|
||||
the services mechanism may be a better fit.
|
||||
If you have the following configuration:
|
||||
|
||||
```python
|
||||
c.JupyterHub.admin_users = {"service-admin"}
|
||||
c.JupyterHub.admin_users = {"service-admin",}
|
||||
c.JupyterHub.api_tokens = {
|
||||
"secret-token": "service-admin",
|
||||
}
|
||||
@@ -121,8 +103,9 @@ c.JupyterHub.services = [
|
||||
},
|
||||
]
|
||||
|
||||
# roles were introduced in JupyterHub 2.0
|
||||
# prior to 2.0, only "admin": True or False was available
|
||||
# roles are new in JupyterHub 2.0
|
||||
# prior to 2.0, only 'admin': True or False
|
||||
# was available
|
||||
|
||||
c.JupyterHub.load_roles = [
|
||||
{
|
||||
@@ -142,7 +125,7 @@ c.JupyterHub.load_roles = [
|
||||
The token will have the permissions listed in the role
|
||||
(see [scopes][] for a list of available permissions),
|
||||
but there will no longer be a user account created to house it.
|
||||
The main noticeable difference between a user and a service is that there will be no notebook server associated with the account
|
||||
The main noticeable difference is that there will be no notebook server associated with the account
|
||||
and the service will not show up in the various user list pages and APIs.
|
||||
|
||||
## Make an API request
|
||||
@@ -153,8 +136,9 @@ Authorization header.
|
||||
### Use requests
|
||||
|
||||
Using the popular Python [requests](https://docs.python-requests.org)
|
||||
library, an API GET request is made, and the request sends an API token for
|
||||
authorization. The response contains information about the users, here's example code to make an API request for the users of a JupyterHub deployment
|
||||
library, here's example code to make an API request for the users of a JupyterHub
|
||||
deployment. An API GET request is made, and the request sends an API token for
|
||||
authorization. The response contains information about the users:
|
||||
|
||||
```python
|
||||
import requests
|
||||
@@ -192,8 +176,7 @@ r.json()
|
||||
```
|
||||
|
||||
The same API token can also authorize access to the [Jupyter Notebook REST API][]
|
||||
|
||||
provided by notebook servers managed by JupyterHub if it has the necessary `access:servers` scope.
|
||||
provided by notebook servers managed by JupyterHub if it has the necessary `access:users:servers` scope:
|
||||
|
||||
(api-pagination)=
|
||||
|
||||
@@ -262,7 +245,7 @@ with your request, in which case a response will look like:
|
||||
|
||||
where the list results (same as pre-2.0) will be in `items`,
|
||||
and pagination info will be in `_pagination`.
|
||||
The `next` field will include the `offset`, `limit`, and `url` for requesting the next page.
|
||||
The `next` field will include the offset, limit, and URL for requesting the next page.
|
||||
`next` will be `null` if there is no next page.
|
||||
|
||||
Pagination is governed by two configuration options:
|
||||
@@ -276,7 +259,7 @@ Pagination is enabled on the `GET /users`, `GET /groups`, and `GET /proxy` REST
|
||||
|
||||
## Enabling users to spawn multiple named-servers via the API
|
||||
|
||||
Support for multiple servers per user was introduced in JupyterHub [version 0.8.](../changelog.md)
|
||||
With JupyterHub version 0.8, support for multiple servers per user has landed.
|
||||
Prior to that, each user could only launch a single default server via the API
|
||||
like this:
|
||||
|
||||
@@ -292,7 +275,7 @@ First you must enable named-servers by including the following setting in the `j
|
||||
|
||||
`c.JupyterHub.allow_named_servers = True`
|
||||
|
||||
If you are using the [zero-to-jupyterhub-k8s](https://github.com/jupyterhub/zero-to-jupyterhub-k8s) set-up to run JupyterHub,
|
||||
If using the [zero-to-jupyterhub-k8s](https://github.com/jupyterhub/zero-to-jupyterhub-k8s) set-up to run JupyterHub,
|
||||
then instead of editing the `jupyterhub_config.py` file directly, you could pass
|
||||
the following as part of the `config.yaml` file, as per the [tutorial](https://zero-to-jupyterhub.readthedocs.io/en/latest/):
|
||||
|
||||
@@ -320,9 +303,8 @@ or kubernetes pods.
|
||||
|
||||
## Learn more about the API
|
||||
|
||||
You can see the full [JupyterHub REST API][] for more details.
|
||||
You can see the full [JupyterHub REST API][] for details.
|
||||
|
||||
[openapi initiative]: https://www.openapis.org/
|
||||
[jupyterhub rest api]: ./rest-api
|
||||
[scopes]: ../rbac/scopes.md
|
||||
[jupyter notebook rest api]: https://petstore3.swagger.io/?url=https://raw.githubusercontent.com/jupyter/notebook/HEAD/notebook/services/api/api.yaml
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
## Background
|
||||
|
||||
The thing which users directly connect to is the proxy, which by default is
|
||||
The thing which users directly connect to is the proxy, by default
|
||||
`configurable-http-proxy`. The proxy either redirects users to the
|
||||
hub (for login and managing servers), or to their own single-user
|
||||
servers. Thus, as long as the proxy stays running, access to existing
|
||||
@@ -10,15 +10,16 @@ servers continues, even if the hub itself restarts or goes down.
|
||||
|
||||
When you first configure the hub, you may not even realize this
|
||||
because the proxy is automatically managed by the hub. This is great
|
||||
for getting started and even most use-cases, although, everytime you restart the
|
||||
hub, all user connections are also restarted. However, it is also simple to
|
||||
for getting started and even most use, but everytime you restart the
|
||||
hub, all user connections also get restarted. But it's also simple to
|
||||
run the proxy as a service separate from the hub, so that you are free
|
||||
to reconfigure the hub while only interrupting users who are waiting for their notebook server to start.
|
||||
starting their notebook server.
|
||||
to reconfigure the hub while only interrupting users who are currently
|
||||
actively starting the hub.
|
||||
|
||||
The default JupyterHub proxy is
|
||||
[configurable-http-proxy](https://github.com/jupyterhub/configurable-http-proxy). If you are using a different proxy, such
|
||||
as [Traefik](https://github.com/traefik/traefik), these instructions are probably not relevant to you.
|
||||
[configurable-http-proxy](https://github.com/jupyterhub/configurable-http-proxy),
|
||||
and that page has some docs. If you are using a different proxy, such
|
||||
as Traefik, these instructions are probably not relevant to you.
|
||||
|
||||
## Configuration options
|
||||
|
||||
@@ -39,14 +40,9 @@ set to the URL which the hub uses to connect _to the proxy's API_.
|
||||
## Proxy configuration
|
||||
|
||||
You need to configure a service to start the proxy. An example
|
||||
command line argument for this is:
|
||||
|
||||
```bash
|
||||
$ configurable-http-proxy --ip=127.0.0.1 --port=8000 --api-ip=127.0.0.1 --api-port=8001 --default-target=http://localhost:8081 --error-target=http://localhost:8081/hub/error
|
||||
```
|
||||
|
||||
(Details on how to do this is out of the scope of this tutorial. For example, it might be a
|
||||
systemd service configured within another docker container). The proxy has no
|
||||
command line for this is `configurable-http-proxy --ip=127.0.0.1 --port=8000 --api-ip=127.0.0.1 --api-port=8001 --default-target=http://localhost:8081 --error-target=http://localhost:8081/hub/error`. (Details for how to
|
||||
do this is out of scope for this tutorial - for example it might be a
|
||||
systemd service on within another docker cotainer). The proxy has no
|
||||
configuration files, all configuration is via the command line and
|
||||
environment variables.
|
||||
|
||||
@@ -61,9 +57,9 @@ match the token given to `c.ConfigurableHTTPProxy.auth_token`.
|
||||
|
||||
You should check the [configurable-http-proxy
|
||||
options](https://github.com/jupyterhub/configurable-http-proxy) to see
|
||||
what other options are needed, for example, SSL options. Note that
|
||||
these options are configured in the hub if the hub is starting the proxy, so you
|
||||
need to configure the options there.
|
||||
what other options are needed, for example SSL options. Note that
|
||||
these are configured in the hub if the hub is starting the proxy - you
|
||||
need to move the options to here.
|
||||
|
||||
## Docker image
|
||||
|
||||
|
||||
@@ -1,32 +1,37 @@
|
||||
# Starting servers with the JupyterHub API
|
||||
|
||||
Sometimes, when working with applications such as [BinderHub](https://binderhub.readthedocs.io), it may be necessary to launch Jupyter-based services on behalf of your users.
|
||||
Doing so can be achieved through JupyterHub's [REST API](../reference/rest.md), which allows one to launch and manage servers on behalf of users through API calls instead of the JupyterHub UI.
|
||||
This way, you can take advantage of other user/launch/lifecycle patterns that are not natively supported by the JupyterHub UI, all without the need to develop the server management features of JupyterHub Spawners and/or Authenticators.
|
||||
JupyterHub's [REST API][] allows launching servers on behalf of users
|
||||
without ever interacting with the JupyterHub UI.
|
||||
This allows you to build services launching Jupyter-based services for users
|
||||
without relying on the JupyterHub UI at all,
|
||||
enabling a variety of user/launch/lifecycle patterns not natively supported by JupyterHub,
|
||||
without needing to develop all the server management features of JupyterHub Spawners and/or Authenticators.
|
||||
[BinderHub][] is an example of such an application.
|
||||
|
||||
This tutorial goes through working with the JupyterHub API to manage servers for users.
|
||||
In particular, it covers how to:
|
||||
[binderhub]: https://binderhub.readthedocs.io
|
||||
[rest api]: ../reference/rest.md
|
||||
|
||||
1. [Check the status of servers](checking)
|
||||
2. [Start servers](starting)
|
||||
3. [Wait for servers to be ready](waiting)
|
||||
4. [Communicate with servers](communicating)
|
||||
5. [Stop servers](stopping)
|
||||
This document provides an example of working with the JupyterHub API to
|
||||
manage servers for users.
|
||||
In particular, we will cover how to:
|
||||
|
||||
At the end, we also provide sample Python code that can be used to implement these steps.
|
||||
1. [check status of servers](checking)
|
||||
2. [start servers](starting)
|
||||
3. [wait for servers to be ready](waiting)
|
||||
4. [communicate with servers](communicating)
|
||||
5. [stop servers](stopping)
|
||||
|
||||
(checking)=
|
||||
|
||||
## Checking server status
|
||||
|
||||
First, request information about a particular user using a GET request:
|
||||
Requesting information about a user includes a `servers` field,
|
||||
which is a dictionary.
|
||||
|
||||
```
|
||||
GET /hub/api/users/:username
|
||||
```
|
||||
|
||||
The response you get will include a `servers` field, which is a dictionary, as shown in this JSON-formatted response:
|
||||
|
||||
**Required scope: `read:servers`**
|
||||
|
||||
```json
|
||||
@@ -44,9 +49,13 @@ The response you get will include a `servers` field, which is a dictionary, as s
|
||||
}
|
||||
```
|
||||
|
||||
Many JupyterHub deployments only use a 'default' server, represented as an empty string `''` for a name. An investigation of the `servers` field can yield one of two results. First, it can be empty as in the sample JSON response above. In such a case, the user has no running servers.
|
||||
If the `servers` dict is empty, the user has no running servers.
|
||||
The keys of the `servers` dict are server names as strings.
|
||||
Many JupyterHub deployments only use the 'default' server,
|
||||
which has the empty string `''` for a name.
|
||||
In this case, the servers dict will always have either zero or one elements.
|
||||
|
||||
However, should the user have running servers, then the returned dict should contain various information, as shown in this response:
|
||||
This is the servers dict when the user's default server is fully running and ready:
|
||||
|
||||
```json
|
||||
"servers": {
|
||||
@@ -66,28 +75,34 @@ However, should the user have running servers, then the returned dict should con
|
||||
Key properties of a server:
|
||||
|
||||
name
|
||||
: the server's name. Always the same as the key in `servers`.
|
||||
: the server's name. Always the same as the key in `servers`
|
||||
|
||||
ready
|
||||
: boolean. If true, the server can be expected to respond to requests at `url`.
|
||||
|
||||
pending
|
||||
: `null` or a string indicating a transitional state (such as `start` or `stop`).
|
||||
Will always be `null` if `ready` is true or a string if false.
|
||||
Will always be `null` if `ready` is true,
|
||||
and will always be a string if `ready` is false.
|
||||
|
||||
url
|
||||
: The server's url path (e.g. `/users/:name/:servername/`) where the server can be accessed if `ready` is true.
|
||||
: The server's url (just the path, e.g. `/users/:name/:servername/`)
|
||||
where the server can be accessed if `ready` is true.
|
||||
|
||||
progress_url
|
||||
: The API URL path (starting with `/hub/api`) where the progress API can be used to wait for the server to be ready.
|
||||
: The API url path (starting with `/hub/api`)
|
||||
where the progress API can be used to wait for the server to be ready.
|
||||
See below for more details on the progress API.
|
||||
|
||||
last_activity
|
||||
: ISO8601 timestamp indicating when activity was last observed on the server.
|
||||
: ISO8601 timestamp indicating when activity was last observed on the server
|
||||
|
||||
started
|
||||
: ISO801 timestamp indicating when the server was last started.
|
||||
: ISO801 timestamp indicating when the server was last started
|
||||
|
||||
The two responses above are from a user with no servers and another with one `ready` server. The sample below is a response likely to be received when one requests a server launch while the server is not yet ready:
|
||||
We've seen the `servers` model with no servers and with one `ready` server.
|
||||
Here is what it looks like immediately after requesting a server launch,
|
||||
while the server is not ready yet:
|
||||
|
||||
```json
|
||||
"servers": {
|
||||
@@ -104,7 +119,11 @@ The two responses above are from a user with no servers and another with one `re
|
||||
}
|
||||
```
|
||||
|
||||
Note that `ready` is `false` and `pending` has the value `spawn`, meaning that the server is not ready and attempting to access it may not work as it is still in the process of spawning. We'll get more into this below in [waiting for a server][].
|
||||
Note that `ready` is false and `pending` is `spawn`.
|
||||
This means that the server is not ready
|
||||
(attempting to access it may not work)
|
||||
because it isn't finished spawning yet.
|
||||
We'll get more into that below in [waiting for a server][].
|
||||
|
||||
[waiting for a server]: waiting
|
||||
|
||||
@@ -112,7 +131,7 @@ Note that `ready` is `false` and `pending` has the value `spawn`, meaning that t
|
||||
|
||||
## Starting servers
|
||||
|
||||
To start a server, make this API request:
|
||||
To start a server, make the request
|
||||
|
||||
```
|
||||
POST /hub/api/users/:username/servers/[:servername]
|
||||
@@ -120,35 +139,47 @@ POST /hub/api/users/:username/servers/[:servername]
|
||||
|
||||
**Required scope: `servers`**
|
||||
|
||||
Assuming the request was valid, there are two possible responses:
|
||||
(omit servername for the default server)
|
||||
|
||||
Assuming the request was valid,
|
||||
there are two possible responses:
|
||||
|
||||
201 Created
|
||||
: This status code means the launch completed and the server is ready and is available at the server's URL immediately.
|
||||
: This status code means the launch completed and the server is ready.
|
||||
It should be available at the server's URL immediately.
|
||||
|
||||
202 Accepted
|
||||
: This is the more likely response, and means that the server has begun launching,
|
||||
but is not immediately ready. As a result, the server shows `pending: 'spawn'` at this point and you should wait for it to start.
|
||||
: This is the more likely response,
|
||||
and means that the server has begun launching,
|
||||
but isn't immediately ready.
|
||||
The server has `pending: 'spawn'` at this point.
|
||||
|
||||
_Aside: how quickly JupyterHub responds with `202 Accepted` is governed by the `slow_spawn_timeout` tornado setting._
|
||||
|
||||
(waiting)=
|
||||
|
||||
## Waiting for a server to start
|
||||
## Waiting for a server
|
||||
|
||||
After receiving a `202 Accepted` response, you have to wait for the server to start.
|
||||
Two approaches can be applied to establish when the server is ready:
|
||||
If you are starting a server via the API,
|
||||
there's a good change you want to know when it's ready.
|
||||
There are two ways to do with:
|
||||
|
||||
1. {ref}`Polling the server model <polling>`
|
||||
2. {ref}`Using the progress API <progress>`
|
||||
2. the {ref}`progress API <progress>`
|
||||
|
||||
(polling)=
|
||||
|
||||
### Polling the server model
|
||||
|
||||
The simplest way to check if a server is ready is to programmatically query the server model until two conditions are true:
|
||||
The simplest way to check if a server is ready
|
||||
is to request the user model.
|
||||
|
||||
1. The server name is contained in the `servers` response, and
|
||||
2. `servers['servername']['ready']` is true.
|
||||
If:
|
||||
|
||||
The Python code snippet below can be used to check if a server is ready:
|
||||
1. the server name is in the user's `servers` model, and
|
||||
2. `servers['servername']['ready']` is true
|
||||
|
||||
A Python example, checking if a server is ready:
|
||||
|
||||
```python
|
||||
def server_ready(hub_url, user, server_name="", token):
|
||||
@@ -175,12 +206,14 @@ You can keep making this check until `ready` is true.
|
||||
|
||||
(progress)=
|
||||
|
||||
### Using the progress API
|
||||
### Progress API
|
||||
|
||||
The most _efficient_ way to wait for a server to start is by using the progress API.
|
||||
The progress URL is available in the server model under `progress_url` and has the form `/hub/api/users/:user/servers/:servername/progress`.
|
||||
The most _efficient_ way to wait for a server to start is the progress API.
|
||||
|
||||
The default server progress can be accessed at `:user/servers//progress` or `:user/server/progress` as demonstrated in the following GET request:
|
||||
The progress URL is available in the server model under `progress_url`,
|
||||
and has the form `/hub/api/users/:user/servers/:servername/progress`.
|
||||
|
||||
_the default server progress can be accessed at `:user/servers//progress` or `:user/server/progress`_
|
||||
|
||||
```
|
||||
GET /hub/api/users/:user/servers/:servername/progress
|
||||
@@ -188,8 +221,8 @@ GET /hub/api/users/:user/servers/:servername/progress
|
||||
|
||||
**Required scope: `read:servers`**
|
||||
|
||||
The progress API is an example of an [EventStream][] API.
|
||||
Messages are _streamed_ and delivered in the form:
|
||||
This is an [EventStream][] API.
|
||||
In an event stream, messages are _streamed_ and delivered on lines of the form:
|
||||
|
||||
```
|
||||
data: {"progress": 10, "message": "...", ...}
|
||||
@@ -200,7 +233,7 @@ Lines that do not start with `data:` should be ignored.
|
||||
|
||||
[eventstream]: https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events#examples
|
||||
|
||||
Progress events have the form:
|
||||
progress events have the form:
|
||||
|
||||
```python
|
||||
{
|
||||
@@ -221,10 +254,11 @@ ready
|
||||
: present and true only for the last event when the server is ready
|
||||
|
||||
url
|
||||
: only present if `ready` is true; will be the server's URL
|
||||
: only present if `ready` is true; will be the server's url
|
||||
|
||||
The progress API can be used even with fully ready servers.
|
||||
If the server is ready, there will only be one event, which will look like:
|
||||
the progress API can be used even with fully ready servers.
|
||||
If the server is ready,
|
||||
there will only be one event that looks like:
|
||||
|
||||
```json
|
||||
{
|
||||
@@ -236,10 +270,9 @@ If the server is ready, there will only be one event, which will look like:
|
||||
}
|
||||
```
|
||||
|
||||
where `ready` and `url` are the same as in the server model, and `ready` will always be true.
|
||||
where `ready` and `url` are the same as in the server model (`ready` will always be true).
|
||||
|
||||
A significant advantage of the progress API is that it shows the status of the server through a stream of messages.
|
||||
Below is an example of a typical complete stream from the API:
|
||||
A typical complete stream from the event-stream API:
|
||||
|
||||
```
|
||||
|
||||
@@ -269,21 +302,21 @@ DELETE /hub/api/users/:user/servers/[:servername]
|
||||
|
||||
**Required scope: `servers`**
|
||||
|
||||
Similar to when starting a server, issuing the DELETE request above might not stop the server immediately.
|
||||
Instead, the DELETE request has two possible response codes:
|
||||
Like start, delete may not complete immediately.
|
||||
The DELETE request has two possible response codes:
|
||||
|
||||
204 Deleted
|
||||
: This status code means the delete completed and the server is fully stopped.
|
||||
It will now be absent from the user `servers` model.
|
||||
|
||||
202 Accepted
|
||||
: This code means your request was accepted but is not yet completely processed.
|
||||
: Like start, `202` means your request was accepted,
|
||||
but is not yet complete.
|
||||
The server has `pending: 'stop'` at this point.
|
||||
|
||||
There is no progress API for checking when a server actually stops.
|
||||
The only way to wait for a server to stop is to poll it and wait for the server to disappear from the user `servers` model.
|
||||
|
||||
This Python code snippet can be used to stop a server and the wait for the process to complete:
|
||||
Unlike start, there is no progress API for stop.
|
||||
To wait for stop to finish, you must poll the user model
|
||||
and wait for the server to disappear from the user `servers` model.
|
||||
|
||||
```{literalinclude} ../../../examples/server-api/start-stop-server.py
|
||||
:language: python
|
||||
@@ -294,8 +327,9 @@ This Python code snippet can be used to stop a server and the wait for the proce
|
||||
|
||||
## Communicating with servers
|
||||
|
||||
JupyterHub tokens with the `access:servers` scope can be used to communicate with servers themselves.
|
||||
The tokens can be the same as those you used to launch your service.
|
||||
JupyterHub tokens with the the `access:servers` scope
|
||||
can be used to communicate with servers themselves.
|
||||
This can be the same token you used to launch your service.
|
||||
|
||||
```{note}
|
||||
Access scopes are new in JupyterHub 2.0.
|
||||
@@ -304,26 +338,29 @@ a token must be owned by the same user as the server,
|
||||
*or* be an admin token if admin_access is enabled.
|
||||
```
|
||||
|
||||
The URL returned from a server model is the URL path suffix,
|
||||
The URL returned from a server model is the url path suffix,
|
||||
e.g. `/user/:name/` to append to the jupyterhub base URL.
|
||||
The returned URL is of the form `{hub_url}{server_url}`,
|
||||
where `hub_url` would be `http://127.0.0.1:8000` by default and `server_url` is `/user/myname`.
|
||||
When combined, the two give a full URL of `http://127.0.0.1:8000/user/myname`.
|
||||
|
||||
For instance, `{hub_url}{server_url}`,
|
||||
where `hub_url` would be e.g. `http://127.0.0.1:8000` by default,
|
||||
and `server_url` `/user/myname`,
|
||||
for a full url of `http://127.0.0.1:8000/user/myname`.
|
||||
|
||||
## Python example
|
||||
|
||||
The JupyterHub repo includes a complete example in {file}`examples/server-api`
|
||||
that ties all theses steps together.
|
||||
tying all this together.
|
||||
|
||||
In summary, the processes involved in managing servers on behalf of users are:
|
||||
To summarize the steps:
|
||||
|
||||
1. Get user information from `/user/:name`.
|
||||
2. The server model includes a `ready` state to tell you if it's ready.
|
||||
3. If it's not ready, you can follow up with `progress_url` to wait for it.
|
||||
4. If it is ready, you can use the `url` field to link directly to the running server.
|
||||
1. get user info from `/user/:name`
|
||||
2. the server model includes a `ready` state to tell you if it's ready
|
||||
3. if it's not ready, you can follow up with `progress_url` to wait for it
|
||||
4. if it is ready, you can use the `url` field to link directly to the running server
|
||||
|
||||
The example below demonstrates starting and stopping servers via the JupyterHub API,
|
||||
including waiting for them to start via the progress API and waiting for them to stop by polling the user model.
|
||||
The example demonstrates starting and stopping servers via the JupyterHub API,
|
||||
including waiting for them to start via the progress API,
|
||||
as well as waiting for them to stop via polling the user model.
|
||||
|
||||
```{literalinclude} ../../../examples/server-api/start-stop-server.py
|
||||
:language: python
|
||||
|
||||
@@ -35,17 +35,6 @@ A Service may have the following properties:
|
||||
the service will be added to the proxy at `/services/:name`
|
||||
- `api_token: str (default - None)` - For Externally-Managed Services you need to specify
|
||||
an API token to perform API requests to the Hub
|
||||
- `display: bool (default - True)` - When set to true, display a link to the
|
||||
service's URL under the 'Services' dropdown in user's hub home page.
|
||||
|
||||
- `oauth_no_confirm: bool (default - False)` - When set to true,
|
||||
skip the OAuth confirmation page when users access this service.
|
||||
|
||||
By default, when users authenticate with a service using JupyterHub,
|
||||
they are prompted to confirm that they want to grant that service
|
||||
access to their credentials.
|
||||
Skipping the confirmation page is useful for admin-managed services that are considered part of the Hub
|
||||
and shouldn't need extra prompts for login.
|
||||
|
||||
If a service is also to be managed by the Hub, it has a few extra options:
|
||||
|
||||
@@ -61,7 +50,7 @@ If a service is also to be managed by the Hub, it has a few extra options:
|
||||
A **Hub-Managed Service** is started by the Hub, and the Hub is responsible
|
||||
for the Service's actions. A Hub-Managed Service can only be a local
|
||||
subprocess of the Hub. The Hub will take care of starting the process and
|
||||
restart the service if the service stops.
|
||||
restarts it if it stops.
|
||||
|
||||
While Hub-Managed Services share some similarities with notebook Spawners,
|
||||
there are no plans for Hub-Managed Services to support the same spawning
|
||||
@@ -125,10 +114,7 @@ JUPYTERHUB_BASE_URL: Base URL of the Hub (https://mydomain[:port]/)
|
||||
JUPYTERHUB_SERVICE_PREFIX: URL path prefix of this service (/services/:service-name/)
|
||||
JUPYTERHUB_SERVICE_URL: Local URL where the service is expected to be listening.
|
||||
Only for proxied web services.
|
||||
JUPYTERHUB_OAUTH_SCOPES: JSON-serialized list of scopes to use for allowing access to the service
|
||||
(deprecated in 3.0, use JUPYTERHUB_OAUTH_ACCESS_SCOPES).
|
||||
JUPYTERHUB_OAUTH_ACCESS_SCOPES: JSON-serialized list of scopes to use for allowing access to the service (new in 3.0).
|
||||
JUPYTERHUB_OAUTH_CLIENT_ALLOWED_SCOPES: JSON-serialized list of scopes that can be requested by the oauth client on behalf of users (new in 3.0).
|
||||
JUPYTERHUB_OAUTH_SCOPES: JSON-serialized list of scopes to use for allowing access to the service.
|
||||
```
|
||||
|
||||
For the previous 'cull idle' Service example, these environment variables
|
||||
@@ -186,7 +172,7 @@ information to the Service via the environment variables described above. A
|
||||
flexible Service, whether managed by the Hub or not, can make use of these
|
||||
same environment variables.
|
||||
|
||||
When you run a service that has a URL, it will be accessible under a
|
||||
When you run a service that has a url, it will be accessible under a
|
||||
`/services/` prefix, such as `https://myhub.horse/services/my-service/`. For
|
||||
your service to route proxied requests properly, it must take
|
||||
`JUPYTERHUB_SERVICE_PREFIX` into account when routing requests. For example, a
|
||||
@@ -234,17 +220,8 @@ There are two levels of authentication with the Hub:
|
||||
- {class}`.HubOAuth` - For services that should use oauth to authenticate with the Hub.
|
||||
This should be used for any service that serves pages that should be visited with a browser.
|
||||
|
||||
To use HubAuth, you must set the `.api_token` instance variable. This can be
|
||||
done either programmatically when constructing the class, or via the
|
||||
`JUPYTERHUB_API_TOKEN` environment variable. A number of the examples in the
|
||||
root of the jupyterhub git repository set the `JUPYTERHUB_API_TOKEN` variable
|
||||
so consider having a look at those for futher reading
|
||||
([cull-idle](https://github.com/jupyterhub/jupyterhub/tree/master/examples/cull-idle),
|
||||
[external-oauth](https://github.com/jupyterhub/jupyterhub/tree/master/examples/external-oauth),
|
||||
[service-notebook](https://github.com/jupyterhub/jupyterhub/tree/master/examples/service-notebook)
|
||||
and [service-whoiami](https://github.com/jupyterhub/jupyterhub/tree/master/examples/service-whoami))
|
||||
|
||||
(TODO: Where is this API TOKen set?)
|
||||
To use HubAuth, you must set the `.api_token`, either programmatically when constructing the class,
|
||||
or via the `JUPYTERHUB_API_TOKEN` environment variable.
|
||||
|
||||
Most of the logic for authentication implementation is found in the
|
||||
{meth}`.HubAuth.user_for_token` methods,
|
||||
@@ -258,7 +235,7 @@ which makes a request of the Hub, and returns:
|
||||
"name": "username",
|
||||
"groups": ["list", "of", "groups"],
|
||||
"scopes": [
|
||||
"access:servers!server=username/",
|
||||
"access:users:servers!server=username/",
|
||||
],
|
||||
}
|
||||
```
|
||||
@@ -277,7 +254,7 @@ you can access the token authenticating the current request with {meth}`.HubAuth
|
||||
:::{versionchanged} 2.2
|
||||
|
||||
{meth}`.HubAuth.get_token` adds support for retrieving
|
||||
tokens stored in tornado cookies after the completion of OAuth.
|
||||
tokens stored in tornado cookies after completion of OAuth.
|
||||
Previously, it only retrieved tokens from URL parameters or the Authorization header.
|
||||
Passing `get_token(handler, in_cookie=False)` preserves this behavior.
|
||||
:::
|
||||
@@ -397,10 +374,10 @@ The `scopes` field can be used to manage access.
|
||||
Note: a user will have access to a service to complete oauth access to the service for the first time.
|
||||
Individual permissions may be revoked at any later point without revoking the token,
|
||||
in which case the `scopes` field in this model should be checked on each access.
|
||||
The default required scopes for access are available from `hub_auth.oauth_scopes` or `$JUPYTERHUB_OAUTH_ACCESS_SCOPES`.
|
||||
The default required scopes for access are available from `hub_auth.oauth_scopes` or `$JUPYTERHUB_OAUTH_SCOPES`.
|
||||
|
||||
An example of using an Externally-Managed Service and authentication is
|
||||
in the [nbviewer README][nbviewer example] section on securing the notebook viewer,
|
||||
in [nbviewer README][nbviewer example] section on securing the notebook viewer,
|
||||
and an example of its configuration is found [here](https://github.com/jupyter/nbviewer/blob/ed942b10a52b6259099e2dd687930871dc8aac22/nbviewer/providers/base.py#L95).
|
||||
nbviewer can also be run as a Hub-Managed Service as described [nbviewer README][nbviewer example]
|
||||
section on securing the notebook viewer.
|
||||
|
||||
@@ -4,9 +4,9 @@ A [Spawner][] starts each single-user notebook server.
|
||||
The Spawner represents an abstract interface to a process,
|
||||
and a custom Spawner needs to be able to take three actions:
|
||||
|
||||
- start a process
|
||||
- poll whether a process is still running
|
||||
- stop a process
|
||||
- start the process
|
||||
- poll whether the process is still running
|
||||
- stop the process
|
||||
|
||||
## Examples
|
||||
|
||||
@@ -15,9 +15,9 @@ Some examples include:
|
||||
|
||||
- [DockerSpawner](https://github.com/jupyterhub/dockerspawner) for spawning user servers in Docker containers
|
||||
- `dockerspawner.DockerSpawner` for spawning identical Docker containers for
|
||||
each user
|
||||
each users
|
||||
- `dockerspawner.SystemUserSpawner` for spawning Docker containers with an
|
||||
environment and home directory for each user
|
||||
environment and home directory for each users
|
||||
- both `DockerSpawner` and `SystemUserSpawner` also work with Docker Swarm for
|
||||
launching containers on remote machines
|
||||
- [SudoSpawner](https://github.com/jupyterhub/sudospawner) enables JupyterHub to
|
||||
@@ -28,13 +28,12 @@ Some examples include:
|
||||
servers in YARN containers on a Hadoop cluster
|
||||
- [SSHSpawner](https://github.com/NERSC/sshspawner) to spawn notebooks
|
||||
on a remote server using SSH
|
||||
- [KubeSpawner](https://github.com/jupyterhub/kubespawner) to spawn notebook servers on kubernetes cluster.
|
||||
|
||||
## Spawner control methods
|
||||
|
||||
### Spawner.start
|
||||
|
||||
`Spawner.start` should start a single-user server for a single user.
|
||||
`Spawner.start` should start the single-user server for a single user.
|
||||
Information about the user can be retrieved from `self.user`,
|
||||
an object encapsulating the user's name, authentication, and server info.
|
||||
|
||||
@@ -69,13 +68,13 @@ via relaxing the `Spawner.start_timeout` config value.
|
||||
|
||||
#### Note on IPs and ports
|
||||
|
||||
`Spawner.ip` and `Spawner.port` attributes set the _bind_ URL,
|
||||
`Spawner.ip` and `Spawner.port` attributes set the _bind_ url,
|
||||
which the single-user server should listen on
|
||||
(passed to the single-user process via the `JUPYTERHUB_SERVICE_URL` environment variable).
|
||||
The _return_ value is the IP and port (or full URL) the Hub should _connect to_.
|
||||
The _return_ value is the ip and port (or full url) the Hub should _connect to_.
|
||||
These are not necessarily the same, and usually won't be in any Spawner that works with remote resources or containers.
|
||||
|
||||
The default for `Spawner.ip`, and `Spawner.port` is `127.0.0.1:{random}`,
|
||||
The default for Spawner.ip, and Spawner.port is `127.0.0.1:{random}`,
|
||||
which is appropriate for Spawners that launch local processes,
|
||||
where everything is on localhost and each server needs its own port.
|
||||
For remote or container Spawners, it will often make sense to use a different value,
|
||||
@@ -111,7 +110,7 @@ class MySpawner(Spawner):
|
||||
|
||||
#### Exception handling
|
||||
|
||||
When `Spawner.start` raises an Exception, a message can be passed on to the user via the exception using a `.jupyterhub_html_message` or `.jupyterhub_message` attribute.
|
||||
When `Spawner.start` raises an Exception, a message can be passed on to the user via the exception via a `.jupyterhub_html_message` or `.jupyterhub_message` attribute.
|
||||
|
||||
When the Exception has a `.jupyterhub_html_message` attribute, it will be rendered as HTML to the user.
|
||||
|
||||
@@ -121,11 +120,11 @@ If both attributes are not present, the Exception will be shown to the user as u
|
||||
|
||||
### Spawner.poll
|
||||
|
||||
`Spawner.poll` checks if the spawner is still running.
|
||||
`Spawner.poll` should check if the spawner is still running.
|
||||
It should return `None` if it is still running,
|
||||
and an integer exit status, otherwise.
|
||||
|
||||
In the case of local processes, `Spawner.poll` uses `os.kill(PID, 0)`
|
||||
For the local process case, `Spawner.poll` uses `os.kill(PID, 0)`
|
||||
to check if the local process is still running. On Windows, it uses `psutil.pid_exists`.
|
||||
|
||||
### Spawner.stop
|
||||
@@ -141,7 +140,7 @@ A JSON-able dictionary of state can be used to store persisted information.
|
||||
|
||||
Unlike start, stop, and poll methods, the state methods must not be coroutines.
|
||||
|
||||
In the case of single processes, the Spawner state is only the process ID of the server:
|
||||
For the single-process case, the Spawner state is only the process ID of the server:
|
||||
|
||||
```python
|
||||
def get_state(self):
|
||||
@@ -267,8 +266,8 @@ Spawners mainly do one thing: launch a command in an environment.
|
||||
|
||||
The command-line is constructed from user configuration:
|
||||
|
||||
- Spawner.cmd (default: `['jupyterhub-singleuser']`)
|
||||
- Spawner.args (CLI args to pass to the cmd, default: empty)
|
||||
- Spawner.cmd (default: `['jupterhub-singleuser']`)
|
||||
- Spawner.args (cli args to pass to the cmd, default: empty)
|
||||
|
||||
where the configuration:
|
||||
|
||||
@@ -283,7 +282,7 @@ would result in spawning the command:
|
||||
my-singleuser-wrapper --debug --flag
|
||||
```
|
||||
|
||||
The `Spawner.get_args()` method is how `Spawner.args` is accessed,
|
||||
The `Spawner.get_args()` method is how Spawner.args is accessed,
|
||||
and can be used by Spawners to customize/extend user-provided arguments.
|
||||
|
||||
Prior to 2.0, JupyterHub unconditionally added certain options _if specified_ to the command-line,
|
||||
@@ -297,36 +296,33 @@ Additional variables can be specified via the `Spawner.environment` configuratio
|
||||
|
||||
The process environment is returned by `Spawner.get_env`, which specifies the following environment variables:
|
||||
|
||||
- JUPYTERHUB*SERVICE_URL - the \_bind* URL where the server should launch its HTTP server (`http://127.0.0.1:12345`).
|
||||
This includes `Spawner.ip` and `Spawner.port`; _new in 2.0, prior to 2.0 IP, port were on the command-line and only if specified_
|
||||
- JUPYTERHUB*SERVICE_URL - the \_bind* url where the server should launch its http server (`http://127.0.0.1:12345`).
|
||||
This includes Spawner.ip and Spawner.port; _new in 2.0, prior to 2.0 ip,port were on the command-line and only if specified_
|
||||
- JUPYTERHUB_SERVICE_PREFIX - the URL prefix the service will run on (e.g. `/user/name/`)
|
||||
- JUPYTERHUB_USER - the JupyterHub user's username
|
||||
- JUPYTERHUB_SERVER_NAME - the server's name, if using named servers (default server has an empty name)
|
||||
- JUPYTERHUB_API_URL - the full URL for the JupyterHub API (http://17.0.0.1:8001/hub/api)
|
||||
- JUPYTERHUB_BASE_URL - the base URL of the whole jupyterhub deployment, i.e. the bit before `hub/` or `user/`,
|
||||
as set by `c.JupyterHub.base_url` (default: `/`)
|
||||
- JUPYTERHUB_API_URL - the full url for the JupyterHub API (http://17.0.0.1:8001/hub/api)
|
||||
- JUPYTERHUB_BASE_URL - the base url of the whole jupyterhub deployment, i.e. the bit before `hub/` or `user/`,
|
||||
as set by c.JupyterHub.base_url (default: `/`)
|
||||
- JUPYTERHUB_API_TOKEN - the API token the server can use to make requests to the Hub.
|
||||
This is also the OAuth client secret.
|
||||
- JUPYTERHUB_CLIENT_ID - the OAuth client ID for authenticating visitors.
|
||||
- JUPYTERHUB_OAUTH_CALLBACK_URL - the callback URL to use in OAuth, typically `/user/:name/oauth_callback`
|
||||
- JUPYTERHUB_OAUTH_ACCESS_SCOPES - the scopes required to access the server (called JUPYTERHUB_OAUTH_SCOPES prior to 3.0)
|
||||
- JUPYTERHUB_OAUTH_CLIENT_ALLOWED_SCOPES - the scopes the service is allowed to request.
|
||||
If no scopes are requested explicitly, these scopes will be requested.
|
||||
- JUPYTERHUB_OAUTH_CALLBACK_URL - the callback URL to use in oauth, typically `/user/:name/oauth_callback`
|
||||
|
||||
Optional environment variables, depending on configuration:
|
||||
|
||||
- JUPYTERHUB*SSL*[KEYFILE|CERTFILE|CLIENT_CI] - SSL configuration, when `internal_ssl` is enabled
|
||||
- JUPYTERHUB_ROOT_DIR - the root directory of the server (notebook directory), when `Spawner.notebook_dir` is defined (new in 2.0)
|
||||
- JUPYTERHUB_DEFAULT_URL - the default URL for the server (for redirects from `/user/:name/`),
|
||||
if `Spawner.default_url` is defined
|
||||
(new in 2.0, previously passed via CLI)
|
||||
- JUPYTERHUB_DEBUG=1 - generic debug flag, sets maximum log level when `Spawner.debug` is True
|
||||
(new in 2.0, previously passed via CLI)
|
||||
- JUPYTERHUB*SSL*[KEYFILE|CERTFILE|CLIENT_CI] - SSL configuration, when internal_ssl is enabled
|
||||
- JUPYTERHUB_ROOT_DIR - the root directory of the server (notebook directory), when Spawner.notebook_dir is defined (new in 2.0)
|
||||
- JUPYTERHUB_DEFAULT_URL - the default URL for the server (for redirects from /user/:name/),
|
||||
if Spawner.default_url is defined
|
||||
(new in 2.0, previously passed via cli)
|
||||
- JUPYTERHUB_DEBUG=1 - generic debug flag, sets maximum log level when Spawner.debug is True
|
||||
(new in 2.0, previously passed via cli)
|
||||
- JUPYTERHUB_DISABLE_USER_CONFIG=1 - disable loading user config,
|
||||
sets maximum log level when `Spawner.debug` is True (new in 2.0,
|
||||
previously passed via CLI)
|
||||
sets maximum log level when Spawner.debug is True (new in 2.0,
|
||||
previously passed via cli)
|
||||
|
||||
- JUPYTERHUB*[MEM|CPU]*[LIMIT_GUARANTEE] - the values of CPU and memory limits and guarantees.
|
||||
- JUPYTERHUB*[MEM|CPU]*[LIMIT_GUARANTEE] - the values of cpu and memory limits and guarantees.
|
||||
These are not expected to be enforced by the process,
|
||||
but are made available as a hint,
|
||||
e.g. for resource monitoring extensions.
|
||||
@@ -338,10 +334,9 @@ guarantees on resources, such as CPU and memory. To provide a consistent
|
||||
experience for sysadmins and users, we provide a standard way to set and
|
||||
discover these resource limits and guarantees, such as for memory and CPU.
|
||||
For the limits and guarantees to be useful, **the spawner must implement
|
||||
support for them**. For example, `LocalProcessSpawner`, the default
|
||||
support for them**. For example, LocalProcessSpawner, the default
|
||||
spawner, does not support limits and guarantees. One of the spawners
|
||||
that supports limits and guarantees is the
|
||||
[`systemdspawner`](https://github.com/jupyterhub/systemdspawner).
|
||||
that supports limits and guarantees is the `systemdspawner`.
|
||||
|
||||
### Memory Limits & Guarantees
|
||||
|
||||
@@ -368,7 +363,7 @@ limits or guarantees are provided, and no environment values are set.
|
||||
`c.Spawner.cpu_limit`: In supported spawners, you can set
|
||||
`c.Spawner.cpu_limit` to limit the total number of cpu-cores that a
|
||||
single-user notebook server can use. These can be fractional - `0.5` means 50%
|
||||
of one CPU core, `4.0` is 4 CPU-cores, etc. This value is also set in the
|
||||
of one CPU core, `4.0` is 4 cpu-cores, etc. This value is also set in the
|
||||
single-user notebook server's environment variable `CPU_LIMIT`. The limit does
|
||||
not claim that you will be able to use all the CPU up to your limit as other
|
||||
higher priority applications might be taking up CPU.
|
||||
@@ -401,10 +396,9 @@ container `ip` prior to starting and pass that to `.create_certs` (TODO: edit).
|
||||
In general though, this method will not need to be changed and the default
|
||||
`ip`/`dns` (localhost) info will suffice.
|
||||
|
||||
When `.create_certs` is run, it will create the certificates in a default,
|
||||
central location specified by `c.JupyterHub.internal_certs_location`. For
|
||||
`Spawners` that need access to these certs elsewhere (i.e. on another host
|
||||
altogether), the `.move_certs` method can be overridden to move the certs
|
||||
appropriately. Again, using `DockerSpawner` as an example, this would entail
|
||||
moving certs to a directory that will get mounted into the container this
|
||||
spawner starts.
|
||||
When `.create_certs` is run, it will `.create_certs` in a default, central
|
||||
location specified by `c.JupyterHub.internal_certs_location`. For `Spawners`
|
||||
that need access to these certs elsewhere (i.e. on another host altogether),
|
||||
the `.move_certs` method can be overridden to move the certs appropriately.
|
||||
Again, using `DockerSpawner` as an example, this would entail moving certs
|
||||
to a directory that will get mounted into the container this spawner starts.
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
The **Technical Overview** section gives you a high-level view of:
|
||||
|
||||
- JupyterHub's major Subsystems: Hub, Proxy, Single-User Notebook Server
|
||||
- JupyterHub's Subsystems: Hub, Proxy, Single-User Notebook Server
|
||||
- how the subsystems interact
|
||||
- the process from JupyterHub access to user login
|
||||
- JupyterHub's default behavior
|
||||
@@ -11,16 +11,16 @@ The **Technical Overview** section gives you a high-level view of:
|
||||
The goal of this section is to share a deeper technical understanding of
|
||||
JupyterHub and how it works.
|
||||
|
||||
## The Major Subsystems: Hub, Proxy, Single-User Notebook Server
|
||||
## The Subsystems: Hub, Proxy, Single-User Notebook Server
|
||||
|
||||
JupyterHub is a set of processes that together, provide a single-user Jupyter
|
||||
Notebook server for each person in a group. Three subsystems are started
|
||||
JupyterHub is a set of processes that together provide a single user Jupyter
|
||||
Notebook server for each person in a group. Three major subsystems are started
|
||||
by the `jupyterhub` command line program:
|
||||
|
||||
- **Hub** (Python/Tornado): manages user accounts, authentication, and
|
||||
coordinates Single User Notebook Servers using a [Spawner](./spawners.md).
|
||||
coordinates Single User Notebook Servers using a Spawner.
|
||||
|
||||
- **Proxy**: the public-facing part of JupyterHub that uses a dynamic proxy
|
||||
- **Proxy**: the public facing part of JupyterHub that uses a dynamic proxy
|
||||
to route HTTP requests to the Hub and Single User Notebook Servers.
|
||||
[configurable http proxy](https://github.com/jupyterhub/configurable-http-proxy)
|
||||
(node-http-proxy) is the default proxy.
|
||||
@@ -28,7 +28,7 @@ by the `jupyterhub` command line program:
|
||||
- **Single-User Notebook Server** (Python/Tornado): a dedicated,
|
||||
single-user, Jupyter Notebook server is started for each user on the system
|
||||
when the user logs in. The object that starts the single-user notebook
|
||||
servers is called a **[Spawner](./spawners.md)**.
|
||||
servers is called a **Spawner**.
|
||||
|
||||

|
||||
|
||||
@@ -41,8 +41,8 @@ The basic principles of operation are:
|
||||
|
||||
- The Hub spawns the proxy (in the default JupyterHub configuration)
|
||||
- The proxy forwards all requests to the Hub by default
|
||||
- The Hub handles login and spawns single-user notebook servers on demand
|
||||
- The Hub configures the proxy to forward URL prefixes to single-user notebook
|
||||
- The Hub handles login, and spawns single-user notebook servers on demand
|
||||
- The Hub configures the proxy to forward url prefixes to single-user notebook
|
||||
servers
|
||||
|
||||
The proxy is the only process that listens on a public interface. The Hub sits
|
||||
@@ -50,16 +50,17 @@ behind the proxy at `/hub`. Single-user servers sit behind the proxy at
|
||||
`/user/[username]`.
|
||||
|
||||
Different **[authenticators](./authenticators.md)** control access
|
||||
to JupyterHub. The default one [(PAM)](https://en.wikipedia.org/wiki/Pluggable_authentication_module) uses the user accounts on the server where
|
||||
to JupyterHub. The default one (PAM) uses the user accounts on the server where
|
||||
JupyterHub is running. If you use this, you will need to create a user account
|
||||
on the system for each user on your team. However, using other authenticators you can
|
||||
on the system for each user on your team. Using other authenticators, you can
|
||||
allow users to sign in with e.g. a GitHub account, or with any single-sign-on
|
||||
system your organization has.
|
||||
|
||||
Next, **[spawners](./spawners.md)** control how JupyterHub starts
|
||||
the individual notebook server for each user. The default spawner will
|
||||
start a notebook server on the same machine running under their system username.
|
||||
The other main option is to start each server in a separate container, often using [Docker](https://jupyterhub-dockerspawner.readthedocs.io/en/latest/).
|
||||
The other main option is to start each server in a separate container, often
|
||||
using Docker.
|
||||
|
||||
## The Process from JupyterHub Access to User Login
|
||||
|
||||
@@ -71,20 +72,20 @@ When a user accesses JupyterHub, the following events take place:
|
||||
- A single-user notebook server instance is [spawned](./spawners.md) for the
|
||||
logged-in user
|
||||
- When the single-user notebook server starts, the proxy is notified to forward
|
||||
requests made to `/user/[username]/*`, to the single-user notebook server.
|
||||
- A [cookie](https://en.wikipedia.org/wiki/HTTP_cookie) is set on `/hub/`, containing an encrypted token. (Prior to version
|
||||
requests to `/user/[username]/*` to the single-user notebook server.
|
||||
- A cookie is set on `/hub/`, containing an encrypted token. (Prior to version
|
||||
0.8, a cookie for `/user/[username]` was used too.)
|
||||
- The browser is redirected to `/user/[username]`, and the request is handled by
|
||||
the single-user notebook server.
|
||||
|
||||
How does the single-user server identify the user with the Hub via OAuth?
|
||||
The single-user server identifies the user with the Hub via OAuth:
|
||||
|
||||
- On request, the single-user server checks a cookie
|
||||
- If no cookie is set, the single-user server redirects to the Hub for verification via OAuth
|
||||
- After verification at the Hub, the browser is redirected back to the
|
||||
- on request, the single-user server checks a cookie
|
||||
- if no cookie is set, redirect to the Hub for verification via OAuth
|
||||
- after verification at the Hub, the browser is redirected back to the
|
||||
single-user server
|
||||
- The token is verified and stored in a cookie
|
||||
- If no user is identified, the browser is redirected back to `/hub/login`
|
||||
- the token is verified and stored in a cookie
|
||||
- if no user is identified, the browser is redirected back to `/hub/login`
|
||||
|
||||
## Default Behavior
|
||||
|
||||
@@ -110,7 +111,7 @@ working directory:
|
||||
This file needs to persist so that a **Hub** server restart will avoid
|
||||
invalidating cookies. Conversely, deleting this file and restarting the server
|
||||
effectively invalidates all login cookies. The cookie secret file is discussed
|
||||
in the [Cookie Secret section of the Security Settings document](../getting-started/security-basics.rst).
|
||||
in the [Cookie Secret section of the Security Settings document](../getting-started/security-basics.md).
|
||||
|
||||
The location of these files can be specified via configuration settings. It is
|
||||
recommended that these files be stored in standard UNIX filesystem locations,
|
||||
|
||||
@@ -1,29 +1,28 @@
|
||||
# Working with templates and UI
|
||||
|
||||
The pages of the JupyterHub application are generated from
|
||||
[Jinja](https://jinja.palletsprojects.com) templates. These allow the header, for
|
||||
[Jinja](http://jinja.pocoo.org/) templates. These allow the header, for
|
||||
example, to be defined once and incorporated into all pages. By providing
|
||||
your own template(s), you can have complete control over JupyterHub's
|
||||
your own templates, you can have complete control over JupyterHub's
|
||||
appearance.
|
||||
|
||||
## Custom Templates
|
||||
|
||||
JupyterHub will look for custom templates in all paths included in the
|
||||
`JupyterHub.template_paths` configuration option, falling back on these
|
||||
JupyterHub will look for custom templates in all of the paths in the
|
||||
`JupyterHub.template_paths` configuration option, falling back on the
|
||||
[default templates](https://github.com/jupyterhub/jupyterhub/tree/HEAD/share/jupyterhub/templates)
|
||||
if no custom template(s) with specified name(s) are found. This fallback
|
||||
behavior is new in version 0.9; previous versions searched only the paths
|
||||
if no custom template with that name is found. This fallback
|
||||
behavior is new in version 0.9; previous versions searched only those paths
|
||||
explicitly included in `template_paths`. You may override as many
|
||||
or as few templates as you desire.
|
||||
|
||||
## Extending Templates
|
||||
|
||||
Jinja provides a mechanism to [extend templates](https://jinja.palletsprojects.com/en/3.0.x/templates/#template-inheritance).
|
||||
|
||||
A base template can define `block`(s) within itself that child templates can fill up or
|
||||
supply content to. The
|
||||
[JupyterHub default templates](https://github.com/jupyterhub/jupyterhub/tree/HEAD/share/jupyterhub/templates)
|
||||
make extensive use of blocks, thus allowing you to customize parts of the
|
||||
Jinja provides a mechanism to [extend templates](http://jinja.pocoo.org/docs/2.10/templates/#template-inheritance).
|
||||
A base template can define a `block`, and child templates can replace or
|
||||
supplement the material in the block. The
|
||||
[JupyterHub templates](https://github.com/jupyterhub/jupyterhub/tree/HEAD/share/jupyterhub/templates)
|
||||
make extensive use of blocks, which allows you to customize parts of the
|
||||
interface easily.
|
||||
|
||||
In general, a child template can extend a base template, `page.html`, by beginning with:
|
||||
@@ -41,15 +40,15 @@ file with this block:
|
||||
{% extends "templates/page.html" %}
|
||||
```
|
||||
|
||||
By defining `block`s with the same name as in the base template, child templates
|
||||
By defining `block`s with same name as in the base template, child templates
|
||||
can replace those sections with custom content. The content from the base
|
||||
template can be included in the child template with the `{{ super() }}` directive.
|
||||
template can be included with the `{{ super() }}` directive.
|
||||
|
||||
### Example
|
||||
|
||||
To add an additional message to the spawn-pending page, below the existing
|
||||
text about the server starting up, place the content below in a file named
|
||||
`spawn_pending.html`. This directory must also be included in the
|
||||
text about the server starting up, place this content in a file named
|
||||
`spawn_pending.html` in a directory included in the
|
||||
`JupyterHub.template_paths` configuration option.
|
||||
|
||||
```html
|
||||
@@ -62,7 +61,7 @@ text about the server starting up, place the content below in a file named
|
||||
|
||||
To add announcements to be displayed on a page, you have two options:
|
||||
|
||||
- [Extend the page templates as described above](#extending-templates)
|
||||
- Extend the page templates as described above
|
||||
- Use configuration variables
|
||||
|
||||
### Announcement Configuration Variables
|
||||
@@ -72,10 +71,10 @@ the top of all pages. The more specific variables
|
||||
`announcement_login`, `announcement_spawn`, `announcement_home`, and
|
||||
`announcement_logout` are more specific and only show on their
|
||||
respective pages (overriding the global `announcement` variable).
|
||||
Note that changing these variables requires a restart, unlike direct
|
||||
Note that changing these variables require a restart, unlike direct
|
||||
template extension.
|
||||
|
||||
Alternatively, you can get the same effect by extending templates, which allows you
|
||||
You can get the same effect by extending templates, which allows you
|
||||
to update the messages without restarting. Set
|
||||
`c.JupyterHub.template_paths` as mentioned above, and then create a
|
||||
template (for example, `login.html`) with:
|
||||
@@ -85,5 +84,5 @@ template (for example, `login.html`) with:
|
||||
```
|
||||
|
||||
Extending `page.html` puts the message on all pages, but note that
|
||||
extending `page.html` takes precedence over an extension of a specific
|
||||
extending `page.html` take precedence over an extension of a specific
|
||||
page (unlike the variable-based approach above).
|
||||
|
||||
@@ -2,13 +2,13 @@
|
||||
|
||||
This document describes how JupyterHub routes requests.
|
||||
|
||||
This does not include the [REST API](./rest.md) URLs.
|
||||
This does not include the [REST API](./rest.md) urls.
|
||||
|
||||
In general, all URLs can be prefixed with `c.JupyterHub.base_url` to
|
||||
run the whole JupyterHub application on a prefix.
|
||||
|
||||
All authenticated handlers redirect to `/hub/login` to log-in users
|
||||
before being redirected back to the originating page.
|
||||
All authenticated handlers redirect to `/hub/login` to login users
|
||||
prior to being redirected back to the originating page.
|
||||
The returned request should preserve all query parameters.
|
||||
|
||||
## `/`
|
||||
@@ -25,12 +25,12 @@ This is an authenticated URL.
|
||||
|
||||
This handler redirects users to the default URL of the application,
|
||||
which defaults to the user's default server.
|
||||
That is, the handler redirects to `/hub/spawn` if the user's server is not running,
|
||||
or to the server itself (`/user/:name`) if the server is running.
|
||||
That is, it redirects to `/hub/spawn` if the user's server is not running,
|
||||
or the server itself (`/user/:name`) if the server is running.
|
||||
|
||||
This default URL behavior can be customized in two ways:
|
||||
This default url behavior can be customized in two ways:
|
||||
|
||||
First, to redirect users to the JupyterHub home page (`/hub/home`)
|
||||
To redirect users to the JupyterHub home page (`/hub/home`)
|
||||
instead of spawning their server,
|
||||
set `redirect_to_server` to False:
|
||||
|
||||
@@ -40,7 +40,7 @@ c.JupyterHub.redirect_to_server = False
|
||||
|
||||
This might be useful if you have a Hub where you expect
|
||||
users to be managing multiple server configurations
|
||||
but automatic spawning is not desirable.
|
||||
and automatic spawning is not desirable.
|
||||
|
||||
Second, you can customise the landing page to any page you like,
|
||||
such as a custom service you have deployed e.g. with course information:
|
||||
@@ -57,7 +57,7 @@ By default, the Hub home page has just one or two buttons
|
||||
for starting and stopping the user's server.
|
||||
|
||||
If named servers are enabled, there will be some additional
|
||||
tools for management of the named servers.
|
||||
tools for management of named servers.
|
||||
|
||||
_Version added: 1.0_ named server UI is new in 1.0.
|
||||
|
||||
@@ -65,34 +65,34 @@ _Version added: 1.0_ named server UI is new in 1.0.
|
||||
|
||||
This is the JupyterHub login page.
|
||||
If you have a form-based username+password login,
|
||||
such as the default [PAMAuthenticator](https://en.wikipedia.org/wiki/Pluggable_authentication_module),
|
||||
such as the default PAMAuthenticator,
|
||||
this page will render the login form.
|
||||
|
||||

|
||||
|
||||
If login is handled by an external service,
|
||||
e.g. with OAuth, this page will have a button,
|
||||
declaring "Log in with ..." which users can click
|
||||
to log in with the chosen service.
|
||||
declaring "Login with ..." which users can click
|
||||
to login with the chosen service.
|
||||
|
||||

|
||||
|
||||
If you want to skip the user interaction and initiate login
|
||||
via the button, you can set:
|
||||
If you want to skip the user-interaction to initiate logging in
|
||||
via the button, you can set
|
||||
|
||||
```python
|
||||
c.Authenticator.auto_login = True
|
||||
```
|
||||
|
||||
This can be useful when the user is "already logged in" via some mechanism.
|
||||
However, a handshake via `redirects` is necessary to complete the authentication with JupyterHub.
|
||||
This can be useful when the user is "already logged in" via some mechanism,
|
||||
but a handshake via redirects is necessary to complete the authentication with JupyterHub.
|
||||
|
||||
## `/hub/logout`
|
||||
|
||||
Visiting `/hub/logout` clears [cookies](https://en.wikipedia.org/wiki/HTTP_cookie) from the current browser.
|
||||
Visiting `/hub/logout` clears cookies from the current browser.
|
||||
Note that **logging out does not stop a user's server(s)** by default.
|
||||
|
||||
If you would like to shut down user servers on logout,
|
||||
If you would like to shutdown user servers on logout,
|
||||
you can enable this behavior with:
|
||||
|
||||
```python
|
||||
@@ -105,8 +105,8 @@ does not mean the user is no longer actively using their server from another mac
|
||||
## `/user/:username[/:servername]`
|
||||
|
||||
If a user's server is running, this URL is handled by the user's given server,
|
||||
not by the Hub.
|
||||
The username is the first part, and if using named servers,
|
||||
not the Hub.
|
||||
The username is the first part and, if using named servers,
|
||||
the server name is the second part.
|
||||
|
||||
If the user's server is _not_ running, this will be redirected to `/hub/user/:username/...`
|
||||
@@ -117,15 +117,14 @@ This URL indicates a request for a user server that is not running
|
||||
(because `/user/...` would have been handled by the notebook server
|
||||
if the specified server were running).
|
||||
|
||||
Handling this URL depends on two conditions: whether a requested user is found
|
||||
as a match and the state of the requested user's notebook server,
|
||||
for example:
|
||||
Handling this URL is the most complicated condition in JupyterHub,
|
||||
because there can be many states:
|
||||
|
||||
1. the server is not active
|
||||
1. server is not active
|
||||
a. user matches
|
||||
b. user doesn't match
|
||||
2. the server is ready
|
||||
3. the server is pending, but not ready
|
||||
2. server is ready
|
||||
3. server is pending, but not ready
|
||||
|
||||
If the server is pending spawn,
|
||||
the browser will be redirected to `/hub/spawn-pending/:username/:servername`
|
||||
@@ -141,37 +140,39 @@ Some checks are performed and a delay is added before redirecting back to `/user
|
||||
If something is really wrong, this can result in a redirect loop.
|
||||
|
||||
Visiting this page will never result in triggering the spawn of servers
|
||||
without additional user action (i.e. clicking the link on the page).
|
||||
without additional user action (i.e. clicking the link on the page)
|
||||
|
||||

|
||||
|
||||
_Version changed: 1.0_
|
||||
|
||||
Prior to 1.0, this URL itself was responsible for spawning servers.
|
||||
If the progress page was pending, the URL redirected it to running servers.
|
||||
This was useful because it made sure that the requested servers were restarted after they stopped.
|
||||
However, it could also be harmful because unused servers would continuously be restarted if e.g.
|
||||
an idle JupyterLab frontend that constantly makes polling requests was openly pointed at it.
|
||||
Prior to 1.0, this URL itself was responsible for spawning servers,
|
||||
and served the progress page if it was pending,
|
||||
redirected to running servers, and
|
||||
This was useful because it made sure that requested servers were restarted after they stopped,
|
||||
but could also be harmful because unused servers would continuously be restarted if e.g.
|
||||
an idle JupyterLab frontend were open pointed at it,
|
||||
which constantly makes polling requests.
|
||||
|
||||
### Special handling of API requests
|
||||
|
||||
Requests to `/user/:username[/:servername]/api/...` are assumed to be
|
||||
from applications connected to stopped servers.
|
||||
These requests fail with a `503` status code and an informative JSON error message
|
||||
that indicates how to spawn the server.
|
||||
This is meant to help applications such as JupyterLab,
|
||||
These are failed with 503 and an informative JSON error message
|
||||
indicating how to spawn the server.
|
||||
This is meant to help applications such as JupyterLab
|
||||
that are connected to a server that has stopped.
|
||||
|
||||
_Version changed: 1.0_
|
||||
|
||||
JupyterHub version 0.9 failed these API requests with status `404`,
|
||||
but version 1.0 uses 503.
|
||||
JupyterHub 0.9 failed these API requests with status 404,
|
||||
but 1.0 uses 503.
|
||||
|
||||
## `/user-redirect/...`
|
||||
|
||||
The `/user-redirect/...` URL is for sharing a URL that will redirect a user
|
||||
This URL is for sharing a URL that will redirect a user
|
||||
to a path on their own default server.
|
||||
This is useful when different users have the same file at the same URL on their servers,
|
||||
This is useful when users have the same file at the same URL on their servers,
|
||||
and you want a single link to give to any user that will open that file on their server.
|
||||
|
||||
e.g. a link to `/user-redirect/notebooks/Index.ipynb`
|
||||
@@ -193,7 +194,7 @@ that is intended to make it possible.
|
||||
### `/hub/spawn[/:username[/:servername]]`
|
||||
|
||||
Requesting `/hub/spawn` will spawn the default server for the current user.
|
||||
If the `username` and optionally `servername` are specified,
|
||||
If `username` and optionally `servername` are specified,
|
||||
then the specified server for the specified user will be spawned.
|
||||
Once spawn has been requested,
|
||||
the browser is redirected to `/hub/spawn-pending/...`.
|
||||
@@ -206,7 +207,7 @@ and a POST request will trigger the actual spawn and redirect.
|
||||
|
||||
_Version added: 1.0_
|
||||
|
||||
1.0 adds the ability to specify `username` and `servername`.
|
||||
1.0 adds the ability to specify username and servername.
|
||||
Prior to 1.0, only `/hub/spawn` was recognized for the default server.
|
||||
|
||||
_Version changed: 1.0_
|
||||
@@ -246,7 +247,7 @@ against the [JupyterHub REST API](./rest.md).
|
||||
|
||||
Administrators can take various administrative actions from this page:
|
||||
|
||||
- add/remove users
|
||||
- grant admin privileges
|
||||
- start/stop user servers
|
||||
- shutdown JupyterHub itself
|
||||
1. add/remove users
|
||||
2. grant admin privileges
|
||||
3. start/stop user servers
|
||||
4. shutdown JupyterHub itself
|
||||
|
||||
@@ -5,7 +5,7 @@ The **Security Overview** section helps you learn about:
|
||||
- the design of JupyterHub with respect to web security
|
||||
- the semi-trusted user
|
||||
- the available mitigations to protect untrusted users from each other
|
||||
- the value of periodic security audits
|
||||
- the value of periodic security audits.
|
||||
|
||||
This overview also helps you obtain a deeper understanding of how JupyterHub
|
||||
works.
|
||||
@@ -13,12 +13,12 @@ works.
|
||||
## Semi-trusted and untrusted users
|
||||
|
||||
JupyterHub is designed to be a _simple multi-user server for modestly sized
|
||||
groups_ of **semi-trusted** users. While the design reflects serving
|
||||
semi-trusted users, JupyterHub can also be suitable for serving **untrusted** users.
|
||||
groups_ of **semi-trusted** users. While the design reflects serving semi-trusted
|
||||
users, JupyterHub is not necessarily unsuitable for serving **untrusted** users.
|
||||
|
||||
As a result, using JupyterHub with **untrusted** users means more work by the
|
||||
administrator, since much care is required to secure a Hub, with extra caution on
|
||||
protecting users from each other.
|
||||
Using JupyterHub with **untrusted** users does mean more work by the
|
||||
administrator. Much care is required to secure a Hub, with extra caution on
|
||||
protecting users from each other as the Hub is serving untrusted users.
|
||||
|
||||
One aspect of JupyterHub's _design simplicity_ for **semi-trusted** users is that
|
||||
the Hub and single-user servers are placed in a _single domain_, behind a
|
||||
@@ -31,8 +31,9 @@ servers) as a single website (i.e. single domain).
|
||||
## Protect users from each other
|
||||
|
||||
To protect users from each other, a user must **never** be able to write arbitrary
|
||||
HTML and serve it to another user on the Hub's domain. This is prevented by JupyterHub's
|
||||
authentication setup because only the owner of a given single-user notebook server is
|
||||
HTML and serve it to another user on the Hub's domain. JupyterHub's
|
||||
authentication setup prevents a user writing arbitrary HTML and serving it to
|
||||
another user because only the owner of a given single-user notebook server is
|
||||
allowed to view user-authored pages served by the given single-user notebook
|
||||
server.
|
||||
|
||||
@@ -41,15 +42,15 @@ ensure that:
|
||||
|
||||
- A user **does not have permission** to modify their single-user notebook server,
|
||||
including:
|
||||
- the installation of new packages in the Python environment that runs
|
||||
their single-user server;
|
||||
- the creation of new files in any `PATH` directory that precedes the
|
||||
directory containing `jupyterhub-singleuser` (if the `PATH` is used
|
||||
to resolve the single-user executable instead of using an absolute path);
|
||||
- the modification of environment variables (e.g. PATH, PYTHONPATH) for
|
||||
their single-user server;
|
||||
- the modification of the configuration of the notebook server
|
||||
(the `~/.jupyter` or `JUPYTER_CONFIG_DIR` directory).
|
||||
- A user **may not** install new packages in the Python environment that runs
|
||||
their single-user server.
|
||||
- If the `PATH` is used to resolve the single-user executable (instead of
|
||||
using an absolute path), a user **may not** create new files in any `PATH`
|
||||
directory that precedes the directory containing `jupyterhub-singleuser`.
|
||||
- A user may not modify environment variables (e.g. PATH, PYTHONPATH) for
|
||||
their single-user server.
|
||||
- A user **may not** modify the configuration of the notebook server
|
||||
(the `~/.jupyter` or `JUPYTER_CONFIG_DIR` directory).
|
||||
|
||||
If any additional services are run on the same domain as the Hub, the services
|
||||
**must never** display user-authored HTML that is neither _sanitized_ nor _sandboxed_
|
||||
@@ -57,7 +58,7 @@ If any additional services are run on the same domain as the Hub, the services
|
||||
|
||||
## Mitigate security issues
|
||||
|
||||
The several approaches to mitigating security issues with configuration
|
||||
Several approaches to mitigating these issues with configuration
|
||||
options provided by JupyterHub include:
|
||||
|
||||
### Enable subdomains
|
||||
@@ -68,23 +69,24 @@ desired effect, and user servers and the Hub are protected from each other. A
|
||||
user's single-user server will be at `username.jupyter.mydomain.com`. This also
|
||||
requires all user subdomains to point to the same address, which is most easily
|
||||
accomplished with wildcard DNS. Since this spreads the service across multiple
|
||||
domains, you will need wildcard SSL as well. Unfortunately, for many
|
||||
domains, you will need wildcard SSL, as well. Unfortunately, for many
|
||||
institutional domains, wildcard DNS and SSL are not available. **If you do plan
|
||||
to serve untrusted users, enabling subdomains is highly encouraged**, as it
|
||||
resolves the cross-site issues.
|
||||
|
||||
### Disable user config
|
||||
|
||||
If subdomains are unavailable or undesirable, JupyterHub provides a
|
||||
If subdomains are not available or not desirable, JupyterHub provides a
|
||||
configuration option `Spawner.disable_user_config`, which can be set to prevent
|
||||
the user-owned configuration files from being loaded. After implementing this
|
||||
option, `PATH`s and package installation are the other things that the
|
||||
option, PATHs and package installation and PATHs are the other things that the
|
||||
admin must enforce.
|
||||
|
||||
### Prevent spawners from evaluating shell configuration files
|
||||
|
||||
For most Spawners, `PATH` is not something users can influence, but it's important that
|
||||
the Spawner should _not_ evaluate shell configuration files prior to launching the server.
|
||||
For most Spawners, `PATH` is not something users can influence, but care should
|
||||
be taken to ensure that the Spawner does _not_ evaluate shell configuration
|
||||
files prior to launching the server.
|
||||
|
||||
### Isolate packages using virtualenv
|
||||
|
||||
@@ -99,14 +101,14 @@ pose additional risk to the web application's security.
|
||||
|
||||
### Encrypt internal connections with SSL/TLS
|
||||
|
||||
By default, all communications on the server, between the proxy, hub, and single
|
||||
-user notebooks are performed unencrypted. Setting the `internal_ssl` flag in
|
||||
By default, all communication on the server, between the proxy, hub, and single
|
||||
-user notebooks is performed unencrypted. Setting the `internal_ssl` flag in
|
||||
`jupyterhub_config.py` secures the aforementioned routes. Turning this
|
||||
feature on does require that the enabled `Spawner` can use the certificates
|
||||
generated by the `Hub` (the default `LocalProcessSpawner` can, for instance).
|
||||
|
||||
It is also important to note that this encryption **does not** cover the
|
||||
`zmq tcp` sockets between the Notebook client and kernel yet. While users cannot
|
||||
It is also important to note that this encryption **does not** (yet) cover the
|
||||
`zmq tcp` sockets between the Notebook client and kernel. While users cannot
|
||||
submit arbitrary commands to another user's kernel, they can bind to these
|
||||
sockets and listen. When serving untrusted users, this eavesdropping can be
|
||||
mitigated by setting `KernelManager.transport` to `ipc`. This applies standard
|
||||
@@ -117,8 +119,8 @@ extend to securing the `tcp` sockets as well.
|
||||
## Security audits
|
||||
|
||||
We recommend that you do periodic reviews of your deployment's security. It's
|
||||
good practice to keep [JupyterHub](https://readthedocs.org/projects/jupyterhub/), [configurable-http-proxy][], and [nodejs
|
||||
versions](https://github.com/nodejs/Release) up to date.
|
||||
good practice to keep JupyterHub, configurable-http-proxy, and nodejs
|
||||
versions up to date.
|
||||
|
||||
A handy website for testing your deployment is
|
||||
[Qualsys' SSL analyzer tool](https://www.ssllabs.com/ssltest/analyze.html).
|
||||
@@ -127,7 +129,7 @@ A handy website for testing your deployment is
|
||||
|
||||
## Vulnerability reporting
|
||||
|
||||
If you believe you have found a security vulnerability in JupyterHub, or any
|
||||
If you believe you’ve found a security vulnerability in JupyterHub, or any
|
||||
Jupyter project, please report it to
|
||||
[security@ipython.org](mailto:security@ipython.org). If you prefer to encrypt
|
||||
your security reports, you can use [this PGP public
|
||||
|
||||
@@ -1,9 +1,35 @@
|
||||
# Troubleshooting
|
||||
|
||||
When troubleshooting, you may see unexpected behaviors or receive an error
|
||||
message. This section provides links for identifying the cause of the
|
||||
message. This section provide links for identifying the cause of the
|
||||
problem and how to resolve it.
|
||||
|
||||
[_Behavior_](#behavior)
|
||||
|
||||
- JupyterHub proxy fails to start
|
||||
- sudospawner fails to run
|
||||
- What is the default behavior when none of the lists (admin, allowed,
|
||||
allowed groups) are set?
|
||||
- JupyterHub Docker container not accessible at localhost
|
||||
|
||||
[_Errors_](#errors)
|
||||
|
||||
- 500 error after spawning my single-user server
|
||||
|
||||
[_How do I...?_](#how-do-i)
|
||||
|
||||
- Use a chained SSL certificate
|
||||
- Install JupyterHub without a network connection
|
||||
- I want access to the whole filesystem, but still default users to their home directory
|
||||
- How do I increase the number of pySpark executors on YARN?
|
||||
- How do I use JupyterLab's prerelease version with JupyterHub?
|
||||
- How do I set up JupyterHub for a workshop (when users are not known ahead of time)?
|
||||
- How do I set up rotating daily logs?
|
||||
- Toree integration with HDFS rack awareness script
|
||||
- Where do I find Docker images and Dockerfiles related to JupyterHub?
|
||||
|
||||
[_Troubleshooting commands_](#troubleshooting-commands)
|
||||
|
||||
## Behavior
|
||||
|
||||
### JupyterHub proxy fails to start
|
||||
@@ -14,9 +40,9 @@ If you have tried to start the JupyterHub proxy and it fails to start:
|
||||
`c.JupyterHub.ip = '*'`; if it is, try `c.JupyterHub.ip = ''`
|
||||
- Try starting with `jupyterhub --ip=0.0.0.0`
|
||||
|
||||
**Note**: If this occurs on Ubuntu/Debian, check that you are using a
|
||||
recent version of [Node](https://nodejs.org). Some versions of Ubuntu/Debian come with a very old version
|
||||
of Node and it is necessary to update Node.
|
||||
**Note**: If this occurs on Ubuntu/Debian, check that the you are using a
|
||||
recent version of node. Some versions of Ubuntu/Debian come with a version
|
||||
of node that is very old, and it is necessary to update node.
|
||||
|
||||
### sudospawner fails to run
|
||||
|
||||
@@ -35,24 +61,24 @@ to the config file, `jupyterhub_config.py`.
|
||||
### What is the default behavior when none of the lists (admin, allowed, allowed groups) are set?
|
||||
|
||||
When nothing is given for these lists, there will be no admins, and all users
|
||||
who can authenticate on the system (i.e. all the Unix users on the server with
|
||||
who can authenticate on the system (i.e. all the unix users on the server with
|
||||
a password) will be allowed to start a server. The allowed username set lets you limit
|
||||
this to a particular set of users, and admin_users lets you specify who
|
||||
among them may use the admin interface (not necessary, unless you need to do
|
||||
things like inspect other users' servers or modify the user list at runtime).
|
||||
things like inspect other users' servers, or modify the user list at runtime).
|
||||
|
||||
### JupyterHub Docker container is not accessible at localhost
|
||||
### JupyterHub Docker container not accessible at localhost
|
||||
|
||||
Even though the command to start your Docker container exposes port 8000
|
||||
(`docker run -p 8000:8000 -d --name jupyterhub jupyterhub/jupyterhub jupyterhub`),
|
||||
it is possible that the IP address itself is not accessible/visible. As a result,
|
||||
it is possible that the IP address itself is not accessible/visible. As a result
|
||||
when you try http://localhost:8000 in your browser, you are unable to connect
|
||||
even though the container is running properly. One workaround is to explicitly
|
||||
tell Jupyterhub to start at `0.0.0.0` which is visible to everyone. Try this
|
||||
command:
|
||||
`docker run -p 8000:8000 -d --name jupyterhub jupyterhub/jupyterhub jupyterhub --ip 0.0.0.0 --port 8000`
|
||||
|
||||
### How can I kill ports from JupyterHub-managed services that have been orphaned?
|
||||
### How can I kill ports from JupyterHub managed services that have been orphaned?
|
||||
|
||||
I started JupyterHub + nbgrader on the same host without containers. When I try to restart JupyterHub + nbgrader with this configuration, errors appear that the service accounts cannot start because the ports are being used.
|
||||
|
||||
@@ -66,12 +92,12 @@ Where `<service_port>` is the port used by the nbgrader course service. This con
|
||||
|
||||
### Why am I getting a Spawn failed error message?
|
||||
|
||||
After successfully logging in to JupyterHub with a compatible authenticator, I get a 'Spawn failed' error message in the browser. The JupyterHub logs have `jupyterhub KeyError: "getpwnam(): name not found: <my_user_name>`.
|
||||
After successfully logging in to JupyterHub with a compatible authenticators, I get a 'Spawn failed' error message in the browser. The JupyterHub logs have `jupyterhub KeyError: "getpwnam(): name not found: <my_user_name>`.
|
||||
|
||||
This issue occurs when the authenticator requires a local system user to exist. In these cases, you need to use a spawner
|
||||
that does not require an existing system user account, such as `DockerSpawner` or `KubeSpawner`.
|
||||
|
||||
### How can I run JupyterHub with sudo but use my current environment variables and virtualenv location?
|
||||
### How can I run JupyterHub with sudo but use my current env vars and virtualenv location?
|
||||
|
||||
When launching JupyterHub with `sudo jupyterhub` I get import errors and my environment variables don't work.
|
||||
|
||||
@@ -83,11 +109,25 @@ sudo MY_ENV=abc123 \
|
||||
/srv/jupyterhub/jupyterhub
|
||||
```
|
||||
|
||||
### How can I view the logs for JupyterHub or the user's Notebook servers when using the DockerSpawner?
|
||||
|
||||
Use `docker logs <container>` where `<container>` is the container name defined within `docker-compose.yml`. For example, to view the logs of the JupyterHub container use:
|
||||
|
||||
docker logs hub
|
||||
|
||||
By default, the user's notebook server is named `jupyter-<username>` where `username` is the user's username within JupyterHub's db. So if you wanted to see the logs for user `foo` you would use:
|
||||
|
||||
docker logs jupyter-foo
|
||||
|
||||
You can also tail logs to view them in real time using the `-f` option:
|
||||
|
||||
docker logs -f hub
|
||||
|
||||
## Errors
|
||||
|
||||
### Error 500 after spawning my single-user server
|
||||
### 500 error after spawning my single-user server
|
||||
|
||||
You receive a 500 error while accessing the URL `/user/<your_name>/...`.
|
||||
You receive a 500 error when accessing the URL `/user/<your_name>/...`.
|
||||
This is often seen when your single-user server cannot verify your user cookie
|
||||
with the Hub.
|
||||
|
||||
@@ -113,9 +153,9 @@ If everything is working, the response logged will be similar to this:
|
||||
|
||||
You should see a similar 200 message, as above, in the Hub log when you first
|
||||
visit your single-user notebook server. If you don't see this message in the log, it
|
||||
may mean that your single-user notebook server is not connecting to your Hub.
|
||||
may mean that your single-user notebook server isn't connecting to your Hub.
|
||||
|
||||
If you see 403 (forbidden) like this, it is likely a token problem:
|
||||
If you see 403 (forbidden) like this, it's likely a token problem:
|
||||
|
||||
```
|
||||
403 GET /hub/api/authorizations/cookie/jupyterhub-token-name/[secret] (@10.0.1.4) 4.14ms
|
||||
@@ -145,10 +185,10 @@ If you receive a 403 error, the API token for the single-user server is likely
|
||||
invalid. Commonly, the 403 error is caused by resetting the JupyterHub
|
||||
database (either removing jupyterhub.sqlite or some other action) while
|
||||
leaving single-user servers running. This happens most frequently when using
|
||||
DockerSpawner because Docker's default behavior is to stop/start containers
|
||||
that reset the JupyterHub database, rather than destroying and recreating
|
||||
DockerSpawner, because Docker's default behavior is to stop/start containers
|
||||
which resets the JupyterHub database, rather than destroying and recreating
|
||||
the container every time. This means that the same API token is used by the
|
||||
server for its whole life until the container is rebuilt.
|
||||
server for its whole life, until the container is rebuilt.
|
||||
|
||||
The fix for this Docker case is to remove any Docker containers seeing this
|
||||
issue (typically all containers created before a certain point in time):
|
||||
@@ -161,28 +201,28 @@ your server again.
|
||||
|
||||
##### Proxy settings (403 GET)
|
||||
|
||||
When your whole JupyterHub sits behind an organization proxy (_not_ a reverse proxy like NGINX as part of your setup and _not_ the configurable-http-proxy) the environment variables `HTTP_PROXY`, `HTTPS_PROXY`, `http_proxy`, and `https_proxy` might be set. This confuses the JupyterHub single-user servers: When connecting to the Hub for authorization they connect via the proxy instead of directly connecting to the Hub on localhost. The proxy might deny the request (403 GET). This results in the single-user server thinking it has the wrong auth token. To circumvent this you should add `<hub_url>,<hub_ip>,localhost,127.0.0.1` to the environment variables `NO_PROXY` and `no_proxy`.
|
||||
When your whole JupyterHub sits behind a organization proxy (_not_ a reverse proxy like NGINX as part of your setup and _not_ the configurable-http-proxy) the environment variables `HTTP_PROXY`, `HTTPS_PROXY`, `http_proxy` and `https_proxy` might be set. This confuses the jupyterhub-singleuser servers: When connecting to the Hub for authorization they connect via the proxy instead of directly connecting to the Hub on localhost. The proxy might deny the request (403 GET). This results in the singleuser server thinking it has a wrong auth token. To circumvent this you should add `<hub_url>,<hub_ip>,localhost,127.0.0.1` to the environment variables `NO_PROXY` and `no_proxy`.
|
||||
|
||||
### Launching Jupyter Notebooks to run as an externally managed JupyterHub service with the `jupyterhub-singleuser` command returns a `JUPYTERHUB_API_TOKEN` error
|
||||
|
||||
[JupyterHub services](https://jupyterhub.readthedocs.io/en/stable/reference/services.html) allow processes to interact with JupyterHub's REST API. Example use-cases include:
|
||||
|
||||
- **Secure Testing**: provide a canonical Jupyter Notebook for testing production data to reduce the number of entry points into production systems.
|
||||
- **Grading Assignments**: provide access to shared Jupyter Notebooks that may be used for management tasks such as grading assignments.
|
||||
- **Grading Assignments**: provide access to shared Jupyter Notebooks that may be used for management tasks such grading assignments.
|
||||
- **Private Dashboards**: share dashboards with certain group members.
|
||||
|
||||
If possible, try to run the Jupyter Notebook as an externally managed service with one of the provided [jupyter/docker-stacks](https://github.com/jupyter/docker-stacks).
|
||||
|
||||
Standard JupyterHub installations include a [jupyterhub-singleuser](https://github.com/jupyterhub/jupyterhub/blob/9fdab027daa32c9017845572ad9d5ba1722dbc53/setup.py#L116) command which is built from the `jupyterhub.singleuser:main` method. The `jupyterhub-singleuser` command is the default command when JupyterHub launches single-user Jupyter Notebooks. One of the goals of this command is to make sure the version of JupyterHub installed within the Jupyter Notebook coincides with the version of the JupyterHub server itself.
|
||||
|
||||
If you launch a Jupyter Notebook with the `jupyterhub-singleuser` command directly from the command line, the Jupyter Notebook won't have access to the `JUPYTERHUB_API_TOKEN` and will return:
|
||||
If you launch a Jupyter Notebook with the `jupyterhub-singleuser` command directly from the command line the Jupyter Notebook won't have access to the `JUPYTERHUB_API_TOKEN` and will return:
|
||||
|
||||
```
|
||||
JUPYTERHUB_API_TOKEN env is required to run jupyterhub-singleuser.
|
||||
Did you launch it manually?
|
||||
```
|
||||
|
||||
If you plan on testing `jupyterhub-singleuser` independently from JupyterHub, then you can set the API token environment variable. For example, if you were to run the single-user Jupyter Notebook on the host, then:
|
||||
If you plan on testing `jupyterhub-singleuser` independently from JupyterHub, then you can set the api token environment variable. For example, if were to run the single-user Jupyter Notebook on the host, then:
|
||||
|
||||
export JUPYTERHUB_API_TOKEN=my_secret_token
|
||||
jupyterhub-singleuser
|
||||
@@ -203,7 +243,7 @@ With a docker container, pass in the environment variable with the run command:
|
||||
Some certificate providers, i.e. Entrust, may provide you with a chained
|
||||
certificate that contains multiple files. If you are using a chained
|
||||
certificate you will need to concatenate the individual files by appending the
|
||||
chained cert and root cert to your host cert:
|
||||
chain cert and root cert to your host cert:
|
||||
|
||||
cat your_host.crt chain.crt root.crt > your_host-chained.crt
|
||||
|
||||
@@ -216,7 +256,7 @@ You would then set in your `jupyterhub_config.py` file the `ssl_key` and
|
||||
#### Example
|
||||
|
||||
Your certificate provider gives you the following files: `example_host.crt`,
|
||||
`Entrust_L1Kroot.txt`, and `Entrust_Root.txt`.
|
||||
`Entrust_L1Kroot.txt` and `Entrust_Root.txt`.
|
||||
|
||||
Concatenate the files appending the chain cert and root cert to your host cert:
|
||||
|
||||
@@ -249,7 +289,7 @@ with npmbox:
|
||||
python3 -m pip wheel jupyterhub
|
||||
npmbox configurable-http-proxy
|
||||
|
||||
### I want access to the whole filesystem and still default users to their home directory
|
||||
### I want access to the whole filesystem, but still default users to their home directory
|
||||
|
||||
Setting the following in `jupyterhub_config.py` will configure access to
|
||||
the entire filesystem and set the default to the user's home directory.
|
||||
@@ -268,7 +308,7 @@ similar to this one:
|
||||
provides additional information. The [pySpark configuration documentation](https://spark.apache.org/docs/0.9.0/configuration.html)
|
||||
is also helpful for programmatic configuration examples.
|
||||
|
||||
### How do I use JupyterLab's pre-release version with JupyterHub?
|
||||
### How do I use JupyterLab's prerelease version with JupyterHub?
|
||||
|
||||
While JupyterLab is still under active development, we have had users
|
||||
ask about how to try out JupyterLab with JupyterHub.
|
||||
@@ -281,7 +321,7 @@ For instance:
|
||||
python3 -m pip install jupyterlab
|
||||
jupyter serverextension enable --py jupyterlab --sys-prefix
|
||||
|
||||
The important thing is that JupyterLab is installed and enabled in the
|
||||
The important thing is that jupyterlab is installed and enabled in the
|
||||
single-user notebook server environment. For system users, this means
|
||||
system-wide, as indicated above. For Docker containers, it means inside
|
||||
the single-user docker image, etc.
|
||||
@@ -294,14 +334,14 @@ notebook servers to default to JupyterLab:
|
||||
### How do I set up JupyterHub for a workshop (when users are not known ahead of time)?
|
||||
|
||||
1. Set up JupyterHub using OAuthenticator for GitHub authentication
|
||||
2. Configure the admin list to have workshop leaders listed with administrator privileges.
|
||||
2. Configure admin list to have workshop leaders be listed with administrator privileges.
|
||||
|
||||
Users will need a GitHub account to log in and be authenticated by the Hub.
|
||||
Users will need a GitHub account to login and be authenticated by the Hub.
|
||||
|
||||
### How do I set up rotating daily logs?
|
||||
|
||||
You can do this with [logrotate](https://linux.die.net/man/8/logrotate),
|
||||
or pipe to `logger` to use Syslog instead of directly to a file.
|
||||
or pipe to `logger` to use syslog instead of directly to a file.
|
||||
|
||||
For example, with this logrotate config file:
|
||||
|
||||
@@ -322,9 +362,34 @@ Or use syslog:
|
||||
|
||||
jupyterhub | logger -t jupyterhub
|
||||
|
||||
## Troubleshooting commands
|
||||
|
||||
The following commands provide additional detail about installed packages,
|
||||
versions, and system information that may be helpful when troubleshooting
|
||||
a JupyterHub deployment. The commands are:
|
||||
|
||||
- System and deployment information
|
||||
|
||||
```bash
|
||||
jupyter troubleshooting
|
||||
```
|
||||
|
||||
- Kernel information
|
||||
|
||||
```bash
|
||||
jupyter kernelspec list
|
||||
```
|
||||
|
||||
- Debug logs when running JupyterHub
|
||||
|
||||
```bash
|
||||
jupyterhub --debug
|
||||
```
|
||||
|
||||
### Toree integration with HDFS rack awareness script
|
||||
|
||||
The Apache Toree kernel will have an issue when running with JupyterHub if the standard HDFS rack awareness script is used. This will materialize in the logs as a repeated WARN:
|
||||
The Apache Toree kernel will an issue, when running with JupyterHub, if the standard HDFS
|
||||
rack awareness script is used. This will materialize in the logs as a repeated WARN:
|
||||
|
||||
```bash
|
||||
16/11/29 16:24:20 WARN ScriptBasedMapping: Exception running /etc/hadoop/conf/topology_script.py some.ip.address
|
||||
@@ -347,47 +412,8 @@ In order to resolve this issue, there are two potential options.
|
||||
|
||||
Docker images can be found at the [JupyterHub organization on DockerHub](https://hub.docker.com/u/jupyterhub/).
|
||||
The Docker image [jupyterhub/singleuser](https://hub.docker.com/r/jupyterhub/singleuser/)
|
||||
provides an example single-user notebook server for use with DockerSpawner.
|
||||
provides an example single user notebook server for use with DockerSpawner.
|
||||
|
||||
Additional single-user notebook server images can be found at the [Jupyter
|
||||
Additional single user notebook server images can be found at the [Jupyter
|
||||
organization on DockerHub](https://hub.docker.com/r/jupyter/) and information
|
||||
about each image at the [jupyter/docker-stacks repo](https://github.com/jupyter/docker-stacks).
|
||||
|
||||
### How can I view the logs for JupyterHub or the user's Notebook servers when using the DockerSpawner?
|
||||
|
||||
Use `docker logs <container>` where `<container>` is the container name defined within `docker-compose.yml`. For example, to view the logs of the JupyterHub container use:
|
||||
|
||||
docker logs hub
|
||||
|
||||
By default, the user's notebook server is named `jupyter-<username>` where `username` is the user's username within JupyterHub's database.
|
||||
So if you wanted to see the logs for user `foo` you would use:
|
||||
|
||||
docker logs jupyter-foo
|
||||
|
||||
You can also tail logs to view them in real-time using the `-f` option:
|
||||
|
||||
docker logs -f hub
|
||||
|
||||
## Troubleshooting commands
|
||||
|
||||
The following commands provide additional detail about installed packages,
|
||||
versions, and system information that may be helpful when troubleshooting
|
||||
a JupyterHub deployment. The commands are:
|
||||
|
||||
- System and deployment information
|
||||
|
||||
```bash
|
||||
jupyter troubleshoot
|
||||
```
|
||||
|
||||
- Kernel information
|
||||
|
||||
```bash
|
||||
jupyter kernelspec list
|
||||
```
|
||||
|
||||
- Debug logs when running JupyterHub
|
||||
|
||||
```bash
|
||||
jupyterhub --debug
|
||||
```
|
||||
|
||||
@@ -7,9 +7,8 @@ to enable testing without administrative privileges.
|
||||
c = get_config() # noqa
|
||||
c.Application.log_level = 'DEBUG'
|
||||
|
||||
import os
|
||||
|
||||
from oauthenticator.azuread import AzureAdOAuthenticator
|
||||
import os
|
||||
|
||||
c.JupyterHub.authenticator_class = AzureAdOAuthenticator
|
||||
|
||||
|
||||
@@ -9,7 +9,7 @@ _Providing writeable storage for LDAP users_
|
||||
|
||||
Your Jupyterhub is configured to use the LDAPAuthenticator and DockerSpawer.
|
||||
|
||||
- The user has no file directory on the host since you are using LDAP.
|
||||
- The user has no file directory on the host since your are using LDAP.
|
||||
- When a user has no directory and DockerSpawner wants to mount a volume,
|
||||
the spawner will use docker to create a directory.
|
||||
Since the docker daemon is running as root, the generated directory for the volume
|
||||
@@ -23,7 +23,7 @@ Another use would be to copy initial content, such as tutorial files or referenc
|
||||
material, into the user's space when a notebook server is newly spawned.
|
||||
|
||||
You can define your own bootstrap process by implementing a `pre_spawn_hook` on any spawner.
|
||||
The Spawner itself is passed as a parameter to your hook and you can easily get the contextual information out of the spawning process.
|
||||
The Spawner itself is passed as parameter to your hook and you can easily get the contextual information out of the spawning process.
|
||||
|
||||
Similarly, there may be cases where you would like to clean up after a spawner stops.
|
||||
You may implement a `post_stop_hook` that is always executed after the spawner stops.
|
||||
|
||||
@@ -1,132 +0,0 @@
|
||||
import os
|
||||
from functools import wraps
|
||||
from html import escape
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.web import Application, RequestHandler, authenticated
|
||||
|
||||
from jupyterhub.services.auth import HubOAuthCallbackHandler, HubOAuthenticated
|
||||
from jupyterhub.utils import url_path_join
|
||||
|
||||
SCOPE_PREFIX = "custom:grades"
|
||||
READ_SCOPE = f"{SCOPE_PREFIX}:read"
|
||||
WRITE_SCOPE = f"{SCOPE_PREFIX}:write"
|
||||
|
||||
|
||||
def require_scope(scopes):
|
||||
"""Decorator to require scopes
|
||||
|
||||
For use if multiple methods on one Handler
|
||||
may want different scopes,
|
||||
so class-level .hub_scopes is insufficient
|
||||
(e.g. read for GET, write for POST).
|
||||
"""
|
||||
if isinstance(scopes, str):
|
||||
scopes = [scopes]
|
||||
|
||||
def wrap(method):
|
||||
"""The actual decorator"""
|
||||
|
||||
@wraps(method)
|
||||
@authenticated
|
||||
def wrapped(self, *args, **kwargs):
|
||||
self.hub_scopes = scopes
|
||||
return method(self, *args, **kwargs)
|
||||
|
||||
return wrapped
|
||||
|
||||
return wrap
|
||||
|
||||
|
||||
class MyGradesHandler(HubOAuthenticated, RequestHandler):
|
||||
# no hub_scopes, anyone with access to this service
|
||||
# will be able to visit this URL
|
||||
|
||||
@authenticated
|
||||
def get(self):
|
||||
self.write("<h1>My grade</h1>")
|
||||
name = self.current_user["name"]
|
||||
grades = self.settings["grades"]
|
||||
self.write(f"<p>My name is: {escape(name)}</p>")
|
||||
if name in grades:
|
||||
self.write(f"<p>My grade is: {escape(str(grades[name]))}</p>")
|
||||
else:
|
||||
self.write("<p>No grade entered</p>")
|
||||
if READ_SCOPE in self.current_user["scopes"]:
|
||||
self.write('<a href="grades/">enter grades</a>')
|
||||
|
||||
|
||||
class GradesHandler(HubOAuthenticated, RequestHandler):
|
||||
# default scope for this Handler: read-only
|
||||
hub_scopes = [READ_SCOPE]
|
||||
|
||||
def _render(self):
|
||||
grades = self.settings["grades"]
|
||||
self.write("<h1>All grades</h1>")
|
||||
self.write("<table>")
|
||||
self.write("<tr><th>Student</th><th>Grade</th></tr>")
|
||||
for student, grade in grades.items():
|
||||
qstudent = escape(student)
|
||||
qgrade = escape(str(grade))
|
||||
self.write(
|
||||
f"""
|
||||
<tr>
|
||||
<td class="student">{qstudent}</td>
|
||||
<td class="grade">{qgrade}</td>
|
||||
</tr>
|
||||
"""
|
||||
)
|
||||
if WRITE_SCOPE in self.current_user["scopes"]:
|
||||
self.write("Enter grade:")
|
||||
self.write(
|
||||
"""
|
||||
<form action=. method=POST>
|
||||
<input name=student placeholder=student></input>
|
||||
<input kind=number name=grade placeholder=grade></input>
|
||||
<input type="submit" value="Submit">
|
||||
"""
|
||||
)
|
||||
|
||||
@require_scope([READ_SCOPE])
|
||||
async def get(self):
|
||||
self._render()
|
||||
|
||||
# POST requires WRITE_SCOPE instead of READ_SCOPE
|
||||
@require_scope([WRITE_SCOPE])
|
||||
async def post(self):
|
||||
name = self.get_argument("student")
|
||||
grade = self.get_argument("grade")
|
||||
self.settings["grades"][name] = grade
|
||||
self._render()
|
||||
|
||||
|
||||
def main():
|
||||
base_url = os.environ['JUPYTERHUB_SERVICE_PREFIX']
|
||||
|
||||
app = Application(
|
||||
[
|
||||
(base_url, MyGradesHandler),
|
||||
(url_path_join(base_url, 'grades/'), GradesHandler),
|
||||
(
|
||||
url_path_join(base_url, 'oauth_callback'),
|
||||
HubOAuthCallbackHandler,
|
||||
),
|
||||
],
|
||||
cookie_secret=os.urandom(32),
|
||||
grades={"student": 53},
|
||||
)
|
||||
|
||||
http_server = HTTPServer(app)
|
||||
url = urlparse(os.environ['JUPYTERHUB_SERVICE_URL'])
|
||||
|
||||
http_server.listen(url.port, url.hostname)
|
||||
try:
|
||||
IOLoop.current().start()
|
||||
except KeyboardInterrupt:
|
||||
pass
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@@ -1,52 +0,0 @@
|
||||
import sys
|
||||
|
||||
c = get_config() # noqa
|
||||
|
||||
c.JupyterHub.services = [
|
||||
{
|
||||
'name': 'grades',
|
||||
'url': 'http://127.0.0.1:10101',
|
||||
'command': [sys.executable, './grades.py'],
|
||||
'oauth_client_allowed_scopes': [
|
||||
'custom:grades:write',
|
||||
'custom:grades:read',
|
||||
],
|
||||
},
|
||||
]
|
||||
|
||||
c.JupyterHub.custom_scopes = {
|
||||
"custom:grades:read": {
|
||||
"description": "read-access to all grades",
|
||||
},
|
||||
"custom:grades:write": {
|
||||
"description": "Enter new grades",
|
||||
"subscopes": ["custom:grades:read"],
|
||||
},
|
||||
}
|
||||
|
||||
c.JupyterHub.load_roles = [
|
||||
{
|
||||
"name": "user",
|
||||
# grant all users access to services
|
||||
"scopes": ["access:services", "self"],
|
||||
},
|
||||
{
|
||||
"name": "grader",
|
||||
# grant graders access to write grades
|
||||
"scopes": ["custom:grades:write"],
|
||||
"users": ["grader"],
|
||||
},
|
||||
{
|
||||
"name": "instructor",
|
||||
# grant instructors access to read, but not write grades
|
||||
"scopes": ["custom:grades:read"],
|
||||
"users": ["instructor"],
|
||||
},
|
||||
]
|
||||
|
||||
c.JupyterHub.allowed_users = {"instructor", "grader", "student"}
|
||||
# dummy spawner and authenticator for testing, don't actually use these!
|
||||
c.JupyterHub.authenticator_class = 'dummy'
|
||||
c.JupyterHub.spawner_class = 'simple'
|
||||
c.JupyterHub.ip = '127.0.0.1' # let's just run on localhost while dummy auth is enabled
|
||||
c.JupyterHub.log_level = 10
|
||||
@@ -5,10 +5,13 @@ so all URLs and requests necessary for OAuth with JupyterHub should be in one pl
|
||||
"""
|
||||
import json
|
||||
import os
|
||||
from urllib.parse import urlencode, urlparse
|
||||
from urllib.parse import urlencode
|
||||
from urllib.parse import urlparse
|
||||
|
||||
from tornado import log, web
|
||||
from tornado.httpclient import AsyncHTTPClient, HTTPRequest
|
||||
from tornado import log
|
||||
from tornado import web
|
||||
from tornado.httpclient import AsyncHTTPClient
|
||||
from tornado.httpclient import HTTPRequest
|
||||
from tornado.httputil import url_concat
|
||||
from tornado.ioloop import IOLoop
|
||||
|
||||
|
||||
@@ -2,8 +2,6 @@
|
||||
# 1. start/stop servers, and
|
||||
# 2. access the server API
|
||||
|
||||
c = get_config() # noqa
|
||||
|
||||
c.JupyterHub.load_roles = [
|
||||
{
|
||||
"name": "launcher",
|
||||
|
||||
@@ -16,6 +16,7 @@ import time
|
||||
|
||||
import requests
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
|
||||
@@ -6,28 +6,12 @@ that appear when JupyterHub renders pages.
|
||||
To run the service as a hub-managed service simply include in your JupyterHub
|
||||
configuration file something like:
|
||||
|
||||
:notebook:**Info**: You can run the announcement service example from the `examples`
|
||||
directory, using one of the several services provided by JupyterHub.
|
||||
|
||||
```python
|
||||
|
||||
import sys
|
||||
|
||||
from pathlib import Path
|
||||
# absolute path to announcement.py
|
||||
announcement_py = str(Path(__file__).parent.joinpath("announcement.py").resolve())
|
||||
|
||||
#ensure get_config() is added in
|
||||
c = get_config()
|
||||
|
||||
...
|
||||
..
|
||||
|
||||
c.JupyterHub.services = [
|
||||
{
|
||||
'name': 'announcement',
|
||||
'url': 'http://127.0.0.1:8888',
|
||||
'command': [sys.executable, announcement_py, "--port", "8888"],
|
||||
'command': [sys.executable, "-m", "announcement", "--port", "8888"],
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
@@ -3,7 +3,9 @@ import datetime
|
||||
import json
|
||||
import os
|
||||
|
||||
from tornado import escape, ioloop, web
|
||||
from tornado import escape
|
||||
from tornado import ioloop
|
||||
from tornado import web
|
||||
|
||||
from jupyterhub.services.auth import HubAuthenticated
|
||||
|
||||
|
||||
@@ -1,7 +1,5 @@
|
||||
import sys
|
||||
|
||||
c = get_config()
|
||||
|
||||
# To run the announcement service managed by the hub, add this.
|
||||
|
||||
port = 9999
|
||||
|
||||
@@ -1,3 +1 @@
|
||||
from .app import app
|
||||
|
||||
__all__ = ["app"]
|
||||
|
||||
@@ -1,5 +1,8 @@
|
||||
from datetime import datetime
|
||||
from typing import Any, Dict, List, Optional
|
||||
from typing import Any
|
||||
from typing import Dict
|
||||
from typing import List
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
import json
|
||||
import os
|
||||
|
||||
from fastapi import HTTPException, Security, status
|
||||
from fastapi import HTTPException
|
||||
from fastapi import Security
|
||||
from fastapi import status
|
||||
from fastapi.security import OAuth2AuthorizationCodeBearer
|
||||
from fastapi.security.api_key import APIKeyQuery
|
||||
|
||||
|
||||
@@ -1,9 +1,14 @@
|
||||
import os
|
||||
|
||||
from fastapi import APIRouter, Depends, Form, Request
|
||||
from fastapi import APIRouter
|
||||
from fastapi import Depends
|
||||
from fastapi import Form
|
||||
from fastapi import Request
|
||||
|
||||
from .client import get_client
|
||||
from .models import AuthorizationError, HubApiError, User
|
||||
from .models import AuthorizationError
|
||||
from .models import HubApiError
|
||||
from .models import User
|
||||
from .security import get_current_user
|
||||
|
||||
# APIRouter prefix cannot end in /
|
||||
@@ -51,7 +56,7 @@ async def me(user: User = Depends(get_current_user)):
|
||||
|
||||
|
||||
@router.get("/debug")
|
||||
async def debug(request: Request, user: User = Depends(get_current_user)):
|
||||
async def index(request: Request, user: User = Depends(get_current_user)):
|
||||
"""
|
||||
Authenticated function that returns a few pieces of debug
|
||||
* Environ of the service process
|
||||
|
||||
@@ -7,10 +7,16 @@ import os
|
||||
import secrets
|
||||
from functools import wraps
|
||||
|
||||
from flask import Flask, Response, make_response, redirect, request, session
|
||||
from flask import Flask
|
||||
from flask import make_response
|
||||
from flask import redirect
|
||||
from flask import request
|
||||
from flask import Response
|
||||
from flask import session
|
||||
|
||||
from jupyterhub.services.auth import HubOAuth
|
||||
|
||||
|
||||
prefix = os.environ.get('JUPYTERHUB_SERVICE_PREFIX', '/')
|
||||
|
||||
auth = HubOAuth(api_token=os.environ['JUPYTERHUB_API_TOKEN'], cache_max_age=60)
|
||||
|
||||
@@ -26,7 +26,7 @@ After logging in with any username and password, you should see a JSON dump of y
|
||||
```
|
||||
|
||||
What is contained in the model will depend on the permissions
|
||||
requested in the `oauth_client_allowed_scopes` configuration of the service `whoami-oauth` service.
|
||||
requested in the `oauth_roles` configuration of the service `whoami-oauth` service.
|
||||
The default is the minimum required for identification and access to the service,
|
||||
which will provide the username and current scopes.
|
||||
|
||||
|
||||
@@ -14,11 +14,11 @@ c.JupyterHub.services = [
|
||||
# only requesting access to the service,
|
||||
# and identification by name,
|
||||
# nothing more.
|
||||
# Specifying 'oauth_client_allowed_scopes' as a list of scopes
|
||||
# Specifying 'oauth_roles' as a list of role names
|
||||
# allows requesting more information about users,
|
||||
# or the ability to take actions on users' behalf, as required.
|
||||
# the 'inherit' scope means the full permissions of the owner
|
||||
# 'oauth_client_allowed_scopes': ['inherit'],
|
||||
# The default 'token' role has the full permissions of its owner:
|
||||
# 'oauth_roles': ['token'],
|
||||
},
|
||||
]
|
||||
|
||||
|
||||
@@ -10,9 +10,12 @@ from urllib.parse import urlparse
|
||||
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.web import Application, RequestHandler, authenticated
|
||||
from tornado.web import Application
|
||||
from tornado.web import authenticated
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
from jupyterhub.services.auth import HubOAuthCallbackHandler, HubOAuthenticated
|
||||
from jupyterhub.services.auth import HubOAuthCallbackHandler
|
||||
from jupyterhub.services.auth import HubOAuthenticated
|
||||
from jupyterhub.utils import url_path_join
|
||||
|
||||
|
||||
|
||||
@@ -10,7 +10,9 @@ from urllib.parse import urlparse
|
||||
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.web import Application, RequestHandler, authenticated
|
||||
from tornado.web import Application
|
||||
from tornado.web import authenticated
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
from jupyterhub.services.auth import HubAuthenticated
|
||||
|
||||
|
||||
@@ -23,7 +23,7 @@ This app is written in JSX, and then transpiled into an ES5 bundle with Babel an
|
||||
|
||||
#### Centralized state and data management with Redux:
|
||||
|
||||
The app uses Redux throughout the components via the `useSelector` and `useDispatch` hooks to store and update user and group data from the API. With Redux, this data is available to any connected component. This means that if one component receives new data, they all do.
|
||||
The app use Redux throughout the components via the `useSelector` and `useDispatch` hooks to store and update user and group data from the API. With Redux, this data is available to any connected component. This means that if one component recieves new data, they all do.
|
||||
|
||||
#### API functions
|
||||
|
||||
@@ -31,7 +31,7 @@ All API functions used by the front end are packaged as a library of props withi
|
||||
|
||||
#### Pagination
|
||||
|
||||
Indicies of paginated user and group data are stored in a `page` variable in the query string, as well as the `user_page` / `group_page` state variables in Redux. This allows the app to maintain two sources of truth, as well as protect the admin user's place in the collection on page reload. The limit is constant at this point and is held in the Redux state.
|
||||
Indicies of paginated user and group data is stored in a `page` variable in the query string, as well as the `user_page` / `group_page` state variables in Redux. This allows the app to maintain two sources of truth, as well as protect the admin user's place in the collection on page reload. Limit is constant at this point and is held in the Redux state.
|
||||
|
||||
On updates to the paginated data, the app can respond in one of two ways. If a user/group record is either added or deleted, the pagination will reset and data will be pulled back with no offset. Alternatively, if a record is modified, the offset will remain and the change will be shown.
|
||||
|
||||
@@ -55,7 +55,7 @@ startServer().then(() => {
|
||||
.then((data) => dispatchPageChange(data, page));
|
||||
});
|
||||
|
||||
// Alternatively, a new user was added, and user data is being refreshed from offset 0.
|
||||
// Alternatively, a new user was added, user data is being refreshed from offset 0.
|
||||
addUser().then(() => {
|
||||
updateUsers(0, limit)
|
||||
// After data is fetched, the Redux store is updated with the data and asserts page 0.
|
||||
|
||||
56
jsx/build/admin-react.js.LICENSE.txt
Normal file
56
jsx/build/admin-react.js.LICENSE.txt
Normal file
@@ -0,0 +1,56 @@
|
||||
/*
|
||||
object-assign
|
||||
(c) Sindre Sorhus
|
||||
@license MIT
|
||||
*/
|
||||
|
||||
/*!
|
||||
Copyright (c) 2018 Jed Watson.
|
||||
Licensed under the MIT License (MIT), see
|
||||
http://jedwatson.github.io/classnames
|
||||
*/
|
||||
|
||||
/** @license React v0.20.2
|
||||
* scheduler.production.min.js
|
||||
*
|
||||
* Copyright (c) Facebook, Inc. and its affiliates.
|
||||
*
|
||||
* This source code is licensed under the MIT license found in the
|
||||
* LICENSE file in the root directory of this source tree.
|
||||
*/
|
||||
|
||||
/** @license React v16.13.1
|
||||
* react-is.production.min.js
|
||||
*
|
||||
* Copyright (c) Facebook, Inc. and its affiliates.
|
||||
*
|
||||
* This source code is licensed under the MIT license found in the
|
||||
* LICENSE file in the root directory of this source tree.
|
||||
*/
|
||||
|
||||
/** @license React v17.0.2
|
||||
* react-dom.production.min.js
|
||||
*
|
||||
* Copyright (c) Facebook, Inc. and its affiliates.
|
||||
*
|
||||
* This source code is licensed under the MIT license found in the
|
||||
* LICENSE file in the root directory of this source tree.
|
||||
*/
|
||||
|
||||
/** @license React v17.0.2
|
||||
* react-jsx-runtime.production.min.js
|
||||
*
|
||||
* Copyright (c) Facebook, Inc. and its affiliates.
|
||||
*
|
||||
* This source code is licensed under the MIT license found in the
|
||||
* LICENSE file in the root directory of this source tree.
|
||||
*/
|
||||
|
||||
/** @license React v17.0.2
|
||||
* react.production.min.js
|
||||
*
|
||||
* Copyright (c) Facebook, Inc. and its affiliates.
|
||||
*
|
||||
* This source code is licensed under the MIT license found in the
|
||||
* LICENSE file in the root directory of this source tree.
|
||||
*/
|
||||
6
jsx/build/index.html
Normal file
6
jsx/build/index.html
Normal file
@@ -0,0 +1,6 @@
|
||||
<!DOCTYPE html>
|
||||
<head></head>
|
||||
<body>
|
||||
<div id="admin-react-hook"></div>
|
||||
<script src="admin-react.js"></script>
|
||||
</body>
|
||||
@@ -8,7 +8,7 @@
|
||||
"scripts": {
|
||||
"build": "yarn && webpack",
|
||||
"hot": "webpack && webpack-dev-server",
|
||||
"place": "cp build/admin-react.js* ../share/jupyterhub/static/js/",
|
||||
"place": "cp -r build/admin-react.js ../share/jupyterhub/static/js/admin-react.js",
|
||||
"test": "jest --verbose",
|
||||
"snap": "jest --updateSnapshot",
|
||||
"lint": "eslint --ext .jsx --ext .js src/",
|
||||
@@ -28,7 +28,17 @@
|
||||
}
|
||||
},
|
||||
"dependencies": {
|
||||
"@babel/core": "^7.12.3",
|
||||
"@babel/preset-env": "^7.12.11",
|
||||
"@babel/preset-react": "^7.12.10",
|
||||
"@testing-library/jest-dom": "^5.15.1",
|
||||
"@testing-library/react": "^12.1.2",
|
||||
"@testing-library/user-event": "^13.5.0",
|
||||
"babel-loader": "^8.2.1",
|
||||
"bootstrap": "^4.5.3",
|
||||
"css-loader": "^5.0.1",
|
||||
"eslint-plugin-unused-imports": "^1.1.1",
|
||||
"file-loader": "^6.2.0",
|
||||
"history": "^5.0.0",
|
||||
"lodash.debounce": "^4.0.8",
|
||||
"prop-types": "^15.7.2",
|
||||
@@ -41,35 +51,24 @@
|
||||
"react-redux": "^7.2.2",
|
||||
"react-router": "^5.2.0",
|
||||
"react-router-dom": "^5.2.0",
|
||||
"recompose": "npm:react-recompose@^0.31.2",
|
||||
"recompose": "^0.30.0",
|
||||
"redux": "^4.0.5",
|
||||
"regenerator-runtime": "^0.13.9"
|
||||
"regenerator-runtime": "^0.13.9",
|
||||
"style-loader": "^2.0.0",
|
||||
"webpack": "^5.6.0",
|
||||
"webpack-cli": "^3.3.4",
|
||||
"webpack-dev-server": "^3.11.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@babel/core": "^7.12.3",
|
||||
"@babel/preset-env": "^7.12.11",
|
||||
"@babel/preset-react": "^7.12.10",
|
||||
"@testing-library/jest-dom": "^5.15.1",
|
||||
"@testing-library/react": "^12.1.2",
|
||||
"@testing-library/user-event": "^13.5.0",
|
||||
"@webpack-cli/serve": "^1.7.0",
|
||||
"@wojtekmaj/enzyme-adapter-react-17": "^0.6.5",
|
||||
"babel-jest": "^26.6.3",
|
||||
"babel-loader": "^8.2.1",
|
||||
"css-loader": "^5.0.1",
|
||||
"enzyme": "^3.11.0",
|
||||
"eslint": "^7.18.0",
|
||||
"eslint-plugin-prettier": "^3.3.1",
|
||||
"eslint-plugin-react": "^7.22.0",
|
||||
"eslint-plugin-unused-imports": "^1.1.1",
|
||||
"file-loader": "^6.2.0",
|
||||
"identity-obj-proxy": "^3.0.0",
|
||||
"jest": "^26.6.3",
|
||||
"prettier": "^2.2.1",
|
||||
"sinon": "^13.0.1",
|
||||
"style-loader": "^2.0.0",
|
||||
"webpack": "^5.6.0",
|
||||
"webpack-cli": "^4.10.0",
|
||||
"webpack-dev-server": "^4.9.3"
|
||||
"sinon": "^13.0.1"
|
||||
}
|
||||
}
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user